 播面
播面 在LangGraph中,多个并发请求同时对同一个 thread_id 下的状态进行读写,LangGraph 是如何处理并发冲突(Concurrency / Race conditions)的
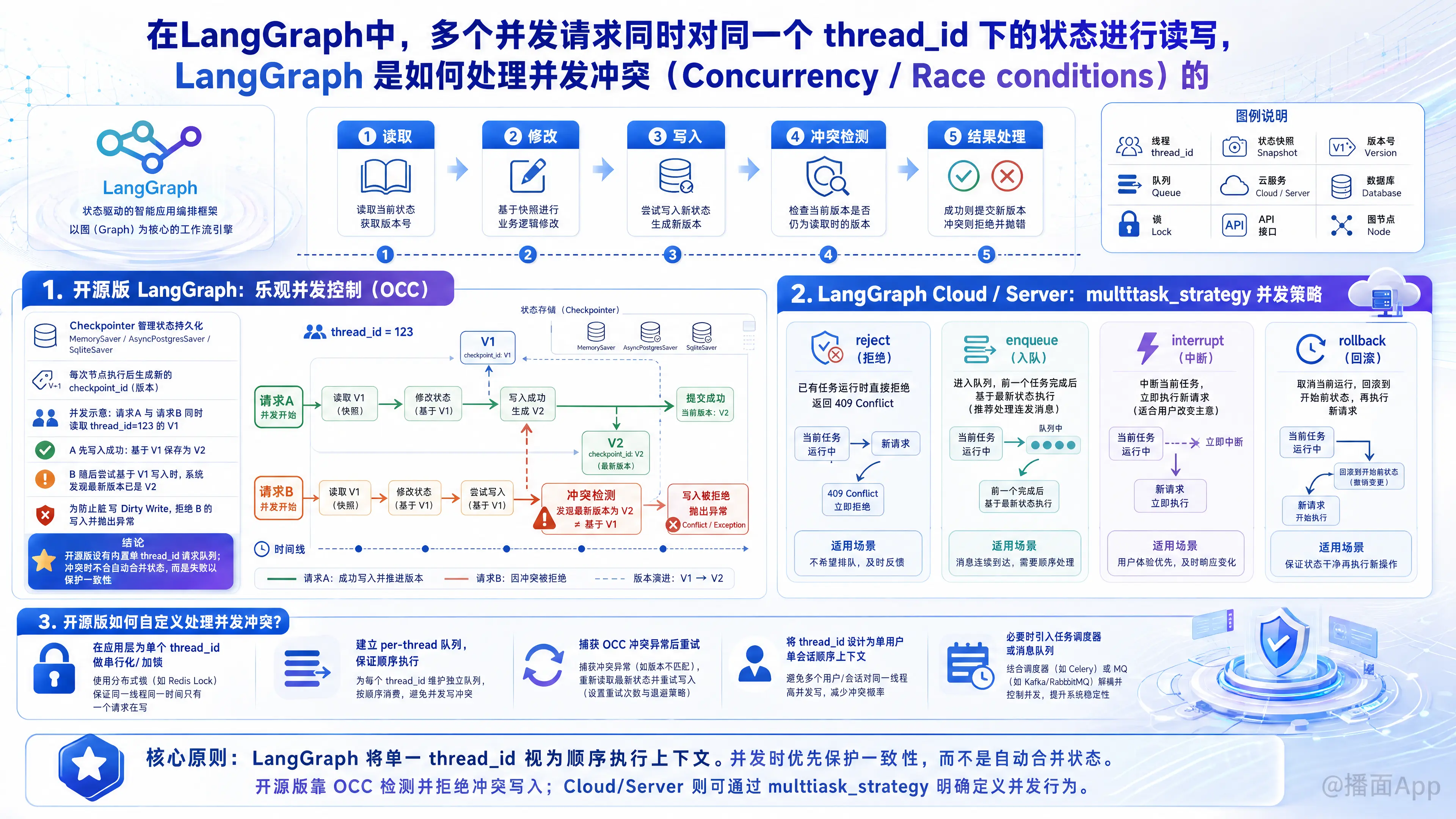
在 LangGraph 中,当多个并发请求同时对同一个 thread_id(线程/会话)下的状态进行读写时,处理并发冲突的机制主要取决于你使用的是 开源版 LangGraph (Open-source LangGraph) 还是 LangGraph Cloud (商业化部署平台)。
总的来说,LangGraph 的设计理念是将单一 thread_id 视为一个顺序执行的上下文(类似于单个用户的单次连续对话)。如果发生并发冲突,它主要通过 乐观并发控制 (Optimistic Concurrency Control, OCC) 来防止状态损坏,而不是自动合并状态。
以下是具体的处理机制和底层原理:
1. 开源版 LangGraph 的处理机制:乐观并发控制 (OCC)
在开源版本的 LangGraph 中,状态的持久化是由 Checkpointer(如 MemorySaver, AsyncPostgresSaver, SqliteSaver 等)来管理的。
- Checkpoint IDs (版本控制): 每次图 (Graph) 中的节点执行完毕并更新状态时,Checkpointer 都会生成一个新的
checkpoint_id(通常是一个基于时间的 UUID)。 - 读取-修改-写入流程:
- 请求 A 和请求 B 同时到达,它们都读取了
thread_id=123的当前最新状态(假设为checkpoint_id=V1)。 - 请求 A 所在的节点执行完毕,准备保存状态。它告诉 Checkpointer:“基于
V1,我要保存新状态V2”。Checkpointer 接受并保存。 - 请求 B 所在的节点随后执行完毕,准备保存状态。它告诉 Checkpointer:“基于
V1,我要保存新状态”。
- 请求 A 和请求 B 同时到达,它们都读取了
- 冲突爆发: 此时,Checkpointer 发现当前数据库中
thread_id=123的最新状态已经是V2了,而不是 B 所依赖的V1。为了防止脏写(Dirty Write)覆盖掉请求 A 的结果,Checkpointer 会拒绝请求 B 的写入,并抛出异常(通常是数据库层面的唯一性约束冲突,或者并发修改异常)。
结论: 开源版 LangGraph 没有内置的针对单个 thread_id 的请求队列。它会通过抛出异常来保护数据一致性,直接导致冲突的请求失败(Crash)。
2. LangGraph Cloud / LangGraph Server 的处理机制:多任务策略 (multitask_strategy)
如果你使用的是 LangGraph Cloud 或官方的 LangGraph API Server,官方在基础架构之上提供了一套完善的并发管理机制。
当你向同一个 thread_id 发起新的 Run(运行)时,你可以通过配置 multitask_strategy 参数来明确告诉服务器如何处理并发冲突。它支持以下几种策略:
reject(拒绝 - 默认行为):
如果该thread_id已经有一个正在运行的任务,新的请求会被直接拒绝,并返回 409 Conflict 错误。enqueue(排队):
将新的请求放入队列中。当前一个任务执行完毕后,新的任务会基于最新的状态(前一个任务更新后的状态)开始执行。这是处理用户快速连续点击(例如连发多条消息)的最佳策略。interrupt(中断):
立即停止当前正在运行的任务(抛出取消异常),并使用最新的请求开始新的运行。这适用于“用户改变主意”的场景(例如生成长文本时,用户打断并提出了新要求)。rollback(回滚):
取消当前运行,并将状态回滚到当前运行开始之前的状态,然后再执行新的请求。
3. 如果你使用开源版,应该如何处理并发冲突?
如果你在自己的服务器上部署开源版 LangGraph,并且需要处理针对同一个 thread_id 的高并发(例如用户狂点发送按钮,或者多个 Agent 尝试修改同一对话),你需要自己在应用层实现控制机制:
方案一:前端防抖/节流 (最简单)
在客户端(Web/App)层面,当用户发送消息后,立即禁用输入框和发送按钮,直到收到 LangGraph 的完整响应。这能避免 90% 以上由同一用户造成的并发问题。
方案二:分布式锁 (Distributed Lock)
在调用 app.invoke(..., {"configurable": {"thread_id": "123"}}) 之前,使用 Redis 或数据库对该 thread_id 加锁。
import redis
r = redis.Redis(...)
def run_langgraph_request(thread_id, user_input):
# 尝试获取锁,设置超时时间防止死锁
if r.setnx(f"lock:thread:{thread_id}", "locked"):
r.expire(f"lock:thread:{thread_id}", 30)
try:
# 执行 LangGraph
app.invoke(...)
finally:
r.delete(f"lock:thread:{thread_id}")
else:
# 锁被占用,说明该 thread 正在执行
return "系统正在处理您的上一条消息,请稍后再试"方案三:消息队列 (Message Queue)
如果你需要类似 LangGraph Cloud 的 enqueue 功能,可以引入 Celery、RabbitMQ 或 Redis Queue。
以 thread_id 作为路由键(Routing Key)或使用一致性哈希,确保同一个 thread_id 的任务总是被投递到同一个 Worker 的同一个顺序队列中处理。这样并发请求就会变成串行执行。
方案四:重试机制 (Retry with Backoff)
捕获写入状态时的异常。如果发生并发冲突异常,捕获它,重新读取该 thread_id 的最新状态(此时已经包含了另一个并发请求的更新),然后重新执行你的逻辑并再次尝试写入。
总结
- 开源版 LangGraph:假设单一
thread_id是串行的,遇并发修改(Race Condition)会通过底层 Checkpointer 的版本校验抛出异常,不会自动合并。 - 商业版 LangGraph Cloud:提供了原生的并发调度器,可通过
multitask_strategy设置为排队(enqueue)、拒绝(reject)或中断(interrupt)。 - 最佳实践:不要让多个独立进程盲目并发写入同一个 thread。应该在系统架构层使用队列串行化或分布式锁来保障同一个 thread_id 一次只执行一个动作。