 播面
播面 在LangGraph中,Supervisor(监督者)Agent 的工作原理。它是如何通过图逻辑将任务分发给不同的执行者 Agent 并收集结果的?
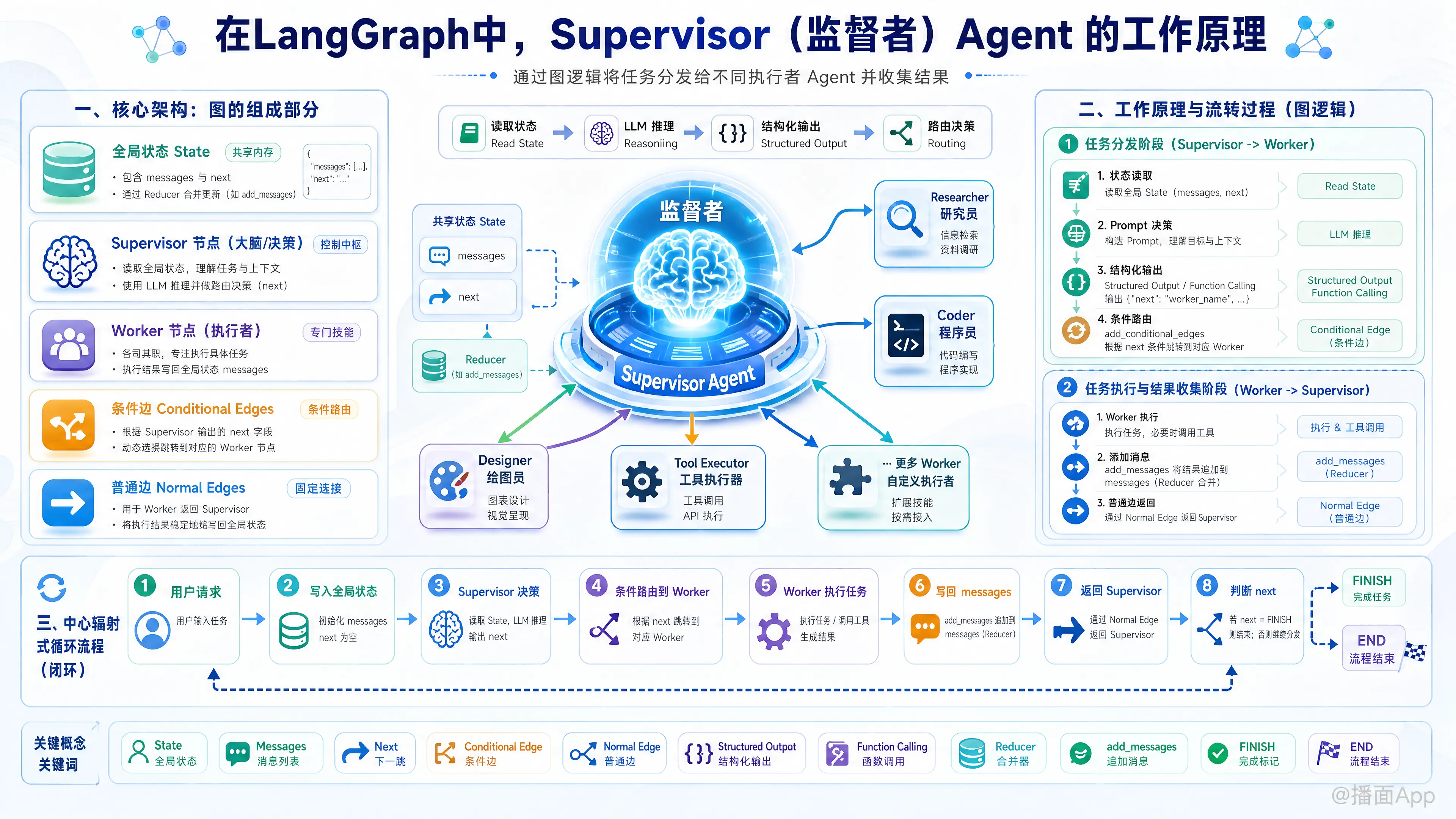
在 LangGraph 中,Supervisor(监督者)Agent 模式是一种非常经典且强大的多智能体(Multi-Agent)架构。你可以把 Supervisor 想象成一个“项目经理”,它本身不负责执行具体的繁重任务,而是负责理解总体目标、制定计划、将子任务分发给拥有不同技能的执行者(Worker Agents),并汇总他们的工作成果,直到最终目标完成。
以下是 Supervisor Agent 在 LangGraph 中的工作原理,以及它如何通过图逻辑实现任务分发和结果收集的详细解析:
一、 核心架构:图的组成部分
在 LangGraph 中,Supervisor 模式的图(Graph)主要由以下几个核心部分构成:
- 全局状态(State): 图的血液。通常是一个包含
messages(对话历史记录)和next(下一个执行者名称)的字典。所有 Agent 都共享并读写这个状态。 - Supervisor 节点(Node): 大脑。一个配置了特定 Prompt 的 LLM,它的唯一任务是阅读当前的状态,并决定接下来该由哪个 Worker 执行,或者是否已经完成任务可以结束。
- Worker 节点(Nodes): 执行者。每个 Worker 是一个专门的 Agent(例如“研究员”、“程序员”、“绘图员”),它们配备了特定的工具(Tools)。
- 条件边(Conditional Edges): 路由逻辑。连接 Supervisor 和各个 Worker,根据 Supervisor 的决策动态改变执行流向。
- 普通边(Normal Edges): 回归逻辑。所有的 Worker 节点执行完毕后,它们的边都强制指向(返回)Supervisor 节点。
二、 工作原理与流转过程(图逻辑)
Supervisor 模式的核心逻辑是一个“中心辐射式”(Hub-and-Spoke)的循环。
1. 任务分发阶段(Supervisor -> Worker)
- 状态读取: 当用户输入请求时,请求进入全局状态。Supervisor 节点首先被触发。
- LLM 推理与决策: Supervisor 读取当前状态(用户的原始请求 + 之前 Worker 生成的所有回复)。Supervisor 的 Prompt 通常会这样写:“你是一个监督者,手下有【研究员】和【程序员】。请根据当前的对话历史,决定下一步应该由谁来行动。如果任务已全部完成,请输出【FINISH】。”
- 结构化输出(Structured Output / Function Calling): Supervisor 使用 OpenAI 的 Function Calling 等能力,强制输出一个 JSON 或特定的枚举值(例如只允许输出
"Researcher","Coder", 或"FINISH")。 - 条件路由(Conditional Edge): LangGraph 的
add_conditional_edges捕捉到 Supervisor 的输出。如果输出是"Researcher",图的执行流就会跳转到“研究员”节点。如果输出是"FINISH",则跳转到图的终点END。
2. 任务执行与结果收集阶段(Worker -> Supervisor)
- Worker 执行: 被唤醒的 Worker(如“研究员”)读取状态中的任务,使用它专属的工具(如搜索引擎)去完成任务。
- 状态更新(结果收集): Worker 完成工作后,会生成一条新的 Message(包含它的执行结果)。在 LangGraph 的 State 定义中,通常会使用
add_messages这个 Reducer,这意味着 Worker 的结果会被追加(Append)到全局状态的messages列表中,而不是覆盖。 - 强制返回(Normal Edge): 在图的定义中,所有的 Worker 节点都没有条件判断,它们的工作完成后,边直接连接回 Supervisor(
graph.add_edge("Researcher", "Supervisor"))。
3. 循环或结束
- 由于 Worker 执行完强制返回了 Supervisor,Supervisor 会再次被触发。
- 此时,Supervisor 看到的全局状态已经更新(包含了用户的请求 + 研究员刚刚查到的资料)。
- Supervisor 再次评估:资料足够了吗?如果足够,还需要写代码,于是它输出
"Coder",流程跳转给程序员。如果全部完成,它输出"FINISH",图运行结束,向用户返回最终的全局状态。
三、 简化的代码逻辑示例
为了更直观地理解,以下是 Supervisor 模式在 LangGraph 中的核心伪代码/逻辑框架:
python
from langgraph.graph import StateGraph, END
from typing import Annotated, TypedDict
from langchain_core.messages import BaseMessage
import operator
# 1. 定义全局状态 (State)
# 使用 operator.add 确保消息是追加的,这是收集结果的关键
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], operator.add]
next: str # 记录下一个该谁执行
# 2. 定义节点 (Nodes)
def supervisor_node(state: AgentState):
# LLM 分析 messages,决定下一个是 "Researcher", "Coder", 还是 "FINISH"
# 返回一个字典更新 State 中的 'next' 字段
next_worker = llm_with_structured_output.invoke(state["messages"])
return {"next": next_worker}
def researcher_node(state: AgentState):
# 研究员执行任务,调用搜索工具
result = researcher_agent.invoke(state["messages"])
# 将结果作为新消息返回,LangGraph 会自动追加到 state["messages"] 中
return {"messages": [result]}
def coder_node(state: AgentState):
# 程序员执行任务,编写代码
result = coder_agent.invoke(state["messages"])
return {"messages": [result]}
# 3. 构建图 (Graph)
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("Supervisor", supervisor_node)
workflow.add_node("Researcher", researcher_node)
workflow.add_node("Coder", coder_node)
# 4. 定义路由逻辑 (Edges)
# 所有的 Worker 执行完后,必须回到 Supervisor(结果收集与重新评估)
workflow.add_edge("Researcher", "Supervisor")
workflow.add_edge("Coder", "Supervisor")
# Supervisor 根据 state["next"] 决定去哪(任务分发)
workflow.add_conditional_edges(
"Supervisor",
lambda state: state["next"], # 路由函数:直接读取 state 里的 next 字段
{
"Researcher": "Researcher",
"Coder": "Coder",
"FINISH": END # 如果是 FINISH,则结束整个流程
}
)
# 设置入口点
workflow.set_entry_point("Supervisor")
# 编译图
app = workflow.compile()四、 这种模式的优势
- 职责分离(Separation of Concerns): 大模型不需要同时充当规划者、搜索者和编码者。Supervisor 专注规划,Worker 专注执行。这大大降低了单个 Prompt 的复杂度,减少了幻觉。
- 状态共享与自然聚合: LangGraph 的
State机制使得“结果收集”变得自动化。Supervisor 不需要编写额外的代码去拉取数据,Worker 只要把结果放到共享的 Message 列表里,Supervisor 下一次“醒来”时自然就能看到。 - 动态与灵活: 任务不是线性硬编码的。如果程序员写代码报错了,它把报错信息放入 State,Supervisor 看到报错后,可以再次把任务派发给程序员去修复,或者派发给研究员去查解决方案。这种图逻辑允许复杂的循环和重试机制。