 播面
播面 在LangGraph中,当工作流被挂起(Interrupt)处于等待状态时,底层机制是如何保持状态等待恢复的?
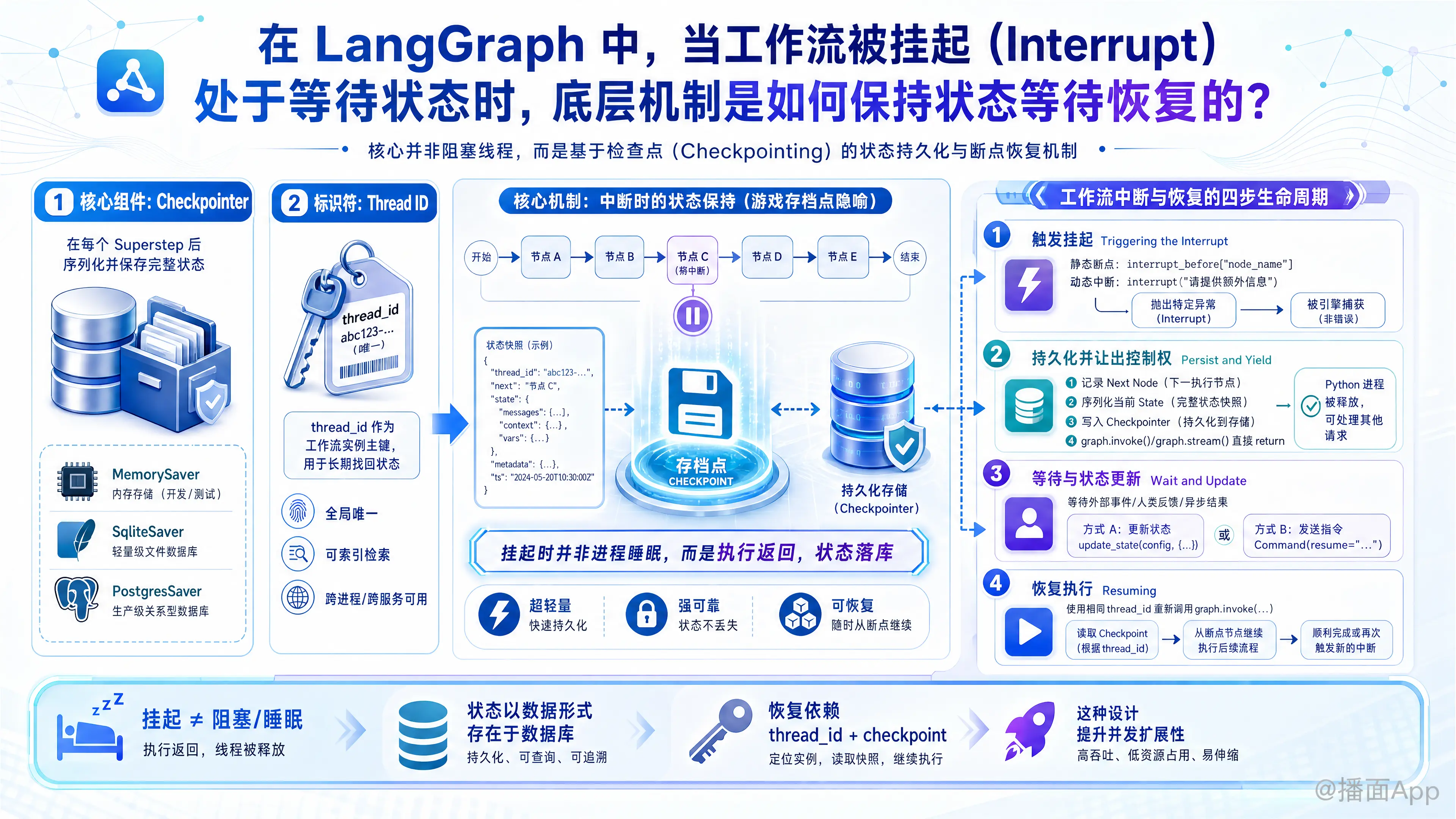
在 LangGraph 中,当工作流被挂起(Interrupt,例如等待人类反馈 Human-in-the-loop)时,底层的 Python 进程或线程并不会处于阻塞(Blocking)或睡眠(Sleep)状态。相反,LangGraph 采用了一种基于检查点(Checkpointing)的状态持久化机制来实现“挂起”和“恢复”。
简单来说,它的底层机制类似于“电子游戏存档”:遇到中断点时,保存当前所有状态并退出当前执行进程;当需要恢复时,读取存档文件,从断点处继续执行。
以下是该底层机制的详细解析:
1. 核心组件:Checkpointer(检查点保存器)
要实现中断和恢复,在编译 LangGraph 工作流时必须传入一个 checkpointer(例如 MemorySaver、SqliteSaver、PostgresSaver 等)。
这是整个机制的基石。Checkpointer 的作用是在工作流的每一个“超步”(Superstep,即图中的节点执行完毕时),将当前工作流的完整状态序列化并写入存储(内存、SQLite 或 PostgreSQL 等数据库)。
2. 标识符:Thread ID(线程 ID)
每个独立的工作流实例运行时,都会被分配一个 thread_id(通过 config 传入)。这个 ID 是 Checkpointer 数据库中的主键。无论工作流被挂起多久,只要有这个 thread_id,就能找回对应的状态。
3. 中断与恢复的完整生命周期(底层机制)
第一步:触发挂起 (Triggering the Interrupt)
在 LangGraph 中触发中断通常有两种方式:
- 静态断点 (Breakpoints):在
graph.compile(interrupt_before=["node_name"])中设置。 - 动态中断 (Dynamic Interrupt):在节点代码内部调用
interrupt("请提供额外信息")。
底层发生了什么?
当执行到中断点时,LangGraph 引擎内部实际上是抛出了一个特定的异常(Exception)(类似于 NodeInterrupt)。这个异常被引擎的最外层捕获。
第二步:持久化并让出控制权 (Persist and Yield)
捕获到中断信号后,LangGraph 引擎会做以下几件事:
- 记录断点位置:记录下一次应该从哪个节点(Next Node)开始执行。
- 序列化当前 State:将图中流转的全局 State(包含所有变量的历史记录和当前值)进行序列化。
- 写入 Checkpointer:将上述信息打包成一个 Checkpoint 对象,使用
thread_id作为键,存入数据库。 - 彻底退出:
graph.invoke()或graph.stream()函数此时会直接return(返回)。Python 进程被释放,它可以去处理其他用户的请求。这使得 LangGraph 在服务器上具有极高的并发扩展性。
此时,你的工作流处于“挂起”状态,但实际上在物理内存/CPU层面,它是不存在的,它只作为一条数据存在于数据库中。
第三步:等待与状态更新 (Wait and Update)
在挂起期间,外部系统(比如前端界面)可以向人类用户展示提示信息。用户输入反馈后,可以通过以下方式更新状态:
- 在旧版本中:使用
graph.update_state(config, {"key": "新输入的值"})将人类的反馈强制写入该thread_id的当前状态中。 - 在新版本中:通过传入
Command(resume="人类的回答")来准备恢复。
第四步:恢复执行 (Resuming)
当外部系统再次调用 graph.invoke(None, config) 或 graph.invoke(Command(resume=...), config) 且传入相同的 thread_id 时。
底层发生了什么?
- 反序列化 (Deserialize):引擎拿到
thread_id,去 Checkpointer 数据库中查询最新的一条 Checkpoint 记录。 - 重建上下文 (Rebuild Context):将数据库中的 State 数据反序列化,恢复成 Python 对象。
- 定位断点 (Find Next Node):引擎读取 Checkpoint 中记录的
next_nodes(即上次挂起前计算出的下一步要执行的节点)。 - 注入新数据 (Inject Resume Data):如果用户提供了
resume数据,LangGraph 会将其作为interrupt()函数的返回值注入到恢复的节点逻辑中。 - 继续图遍历 (Continue Execution):引擎直接跳转到该节点,继续向下执行图的逻辑。
总结图示
[节点 A 执行]
↓
[触发 Interrupt]
↓
引擎打包 (State + Next_Node) → 写入数据库 (Checkpointer)
↓
(Python 函数返回,进程空闲,不消耗 CPU/内存) <--【物理上的挂起阶段】
↓
[用户提供反馈,触发 Resume]
↓
引擎查询数据库 → 读取 (State + Next_Node) → 反序列化恢复内存状态
↓
[从断点 Next_Node 继续执行]为什么采用这种机制?
- 极高的容错性:即使服务器在工作流挂起期间崩溃或重启,只要数据库(Checkpointer)还在,工作流就能无缝恢复。
- 水平扩展能力(Scalability):由于挂起不占用线程/进程,一台普通的服务器可以同时管理数十万个处于“等待人类反馈”状态的 Agent,而不会发生资源耗尽(Out of Memory/Thread Exhaustion)。
- 时间旅行(Time Travel):因为每次跨节点的执行都作为单独的 Checkpoint 保存了版本号(checkpoint_id),你可以不仅可以恢复执行,还可以“回滚”到过去的某个状态重新执行。