 播面
播面 当使用 LangGraph 流式输出多个节点的执行过程时,如何过滤掉中间步骤的内部信息,只向终端用户展示最终答案?
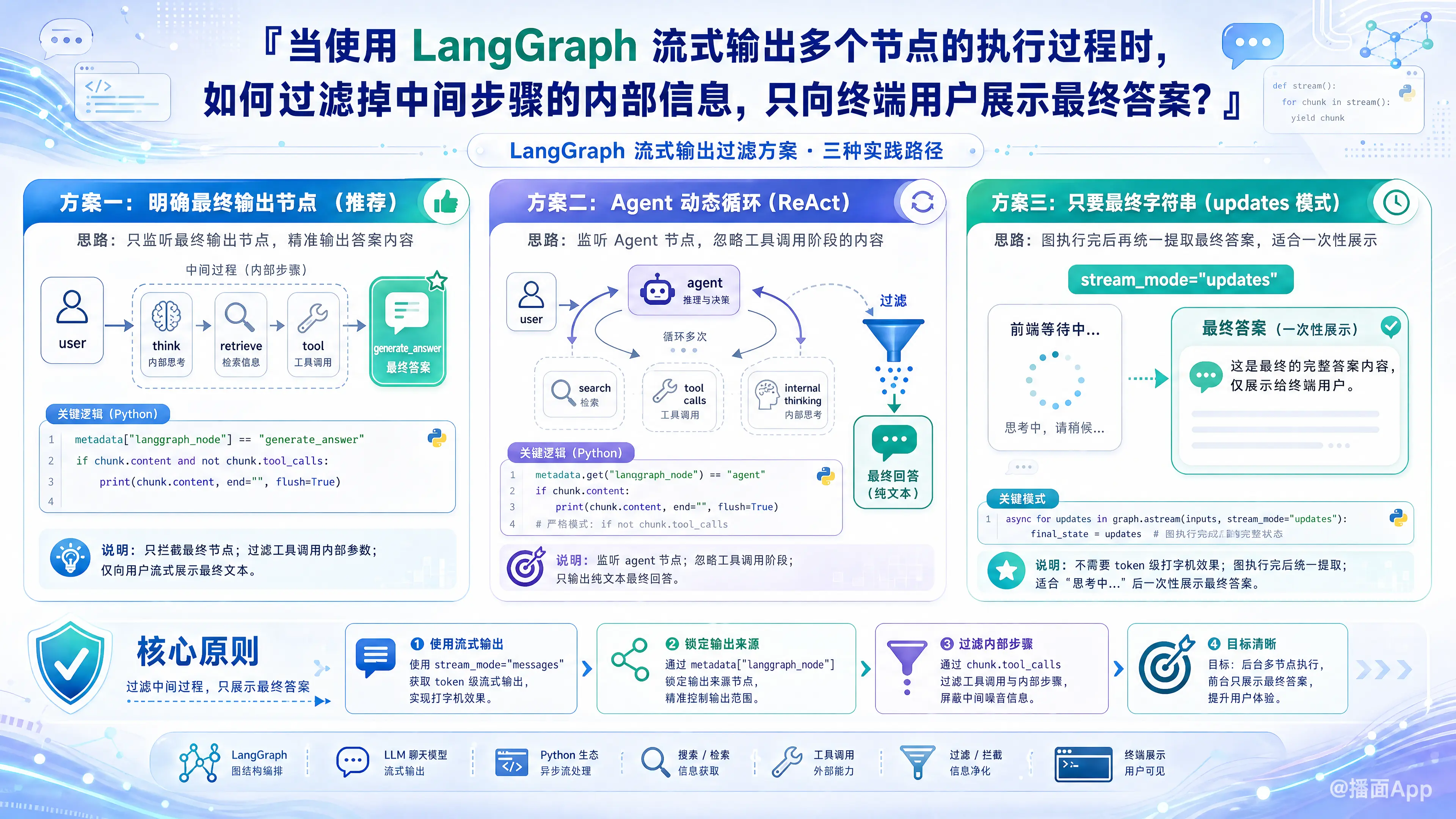
在使用 LangGraph 时,如果你希望在后台执行多个节点(比如思考、调用工具、检索等),但只向终端用户“打字机式”地流式输出最终答案,最核心的思路是:利用 stream_mode="messages" 并在循环中进行条件过滤。
根据你的具体图结构(Graph),这里有三种最常用的过滤方案:
方案一:如果你有明确的“最终输出节点”(推荐)
如果你的图中有一个专门负责生成最终回答的节点(例如命名为 "generate_answer" 或 "final_response"),你可以通过判断 metadata["langgraph_node"] 来过滤。
python
import asyncio
async def stream_final_answer(app, inputs):
# 使用 stream_mode="messages" 可以获取底层的 token 级流式输出
async for chunk, metadata in app.astream(inputs, stream_mode="messages"):
# 1. 只拦截来自最终节点的输出
if metadata.get("langgraph_node") == "generate_answer":
# 2. 确保输出的是文本内容,而不是工具调用(Tool Calls)的内部参数
if chunk.content and not chunk.tool_calls:
print(chunk.content, end="", flush=True)
# 调用示例
# asyncio.run(stream_final_answer(app, {"messages": [("user", "你好")]}))方案二:如果你的 Agent 节点是动态循环的(如 ReAct 架构)
在标准的 Agent 架构中,大模型节点(例如 "agent" 节点)会被反复调用:有时它输出工具调用(内部信息),最后一次它输出最终文本(最终答案)。
这时候,你不能只靠节点名称过滤,还需要过滤掉包含 Tool Calls 的消息。
python
async def stream_agent_final_answer(app, inputs):
async for chunk, metadata in app.astream(inputs, stream_mode="messages"):
# 只监听 LLM 所在的节点
if metadata.get("langgraph_node") == "agent":
# 【关键过滤逻辑】
# 如果大模型正在输出工具调用(比如正在生成搜索关键词),我们就忽略它
# 我们只把纯文本内容(chunk.content)打印给用户看
if chunk.content:
# 某些情况下,大模型会同时输出 content 和 tool_calls,
# 如果你极其严格不想让用户看到任何附带工具调用的闲聊,可以加上:
# if not chunk.tool_calls:
print(chunk.content, end="", flush=True)方案三:不要求 Token 级流式,只需要拿到最终字符串(状态更新模式)
如果你的前端不需要“打字机”效果,只需要展示一个“正在思考中...”的动画,然后等图执行完毕后直接显示最终结果,你应该使用 stream_mode="updates"。
python
def get_final_answer_only(app, inputs):
final_message = ""
# stream_mode="updates" 会在每个节点执行完毕后,返回该节点对 State 的修改
for output in app.stream(inputs, stream_mode="updates"):
# 遍历当前执行完毕的节点名称和更新的数据
for node_name, state_update in output.items():
# 可选:如果你想在终端打印内部进度(仅限开发者看),可以这样:
# print(f"--- [内部执行] 节点 {node_name} 执行完毕 ---")
# 提取最后一条消息作为结果暂存
if "messages" in state_update and len(state_update["messages"]) > 0:
final_message = state_update["messages"][-1].content
# 循环结束后,把最终结果展示给用户
print("【给用户的最终答案】:")
print(final_message)总结与核心原理
LangGraph 流式输出乱七八糟内部信息的原因是:它默认把所有节点的输入/输出,甚至是大模型调用工具时生成的 JSON 参数都当做消息流(Stream)返回了。
为了只给用户看最终结果,你只需要做到两点拦截:
- 看发件人:通过
metadata["langgraph_node"]确认是不是负责最终对话的节点发出的。 - 看内容类型:通过判断
chunk.tool_calls是否为空,确认这是在“和用户说话”还是在“和系统工具说话”。过滤掉后者,用户的体验就完全干净了。