 播面
播面 在多轮循环中,如何监控每次循环消耗的 Token 数量,并将其汇总到某个全局状态中?
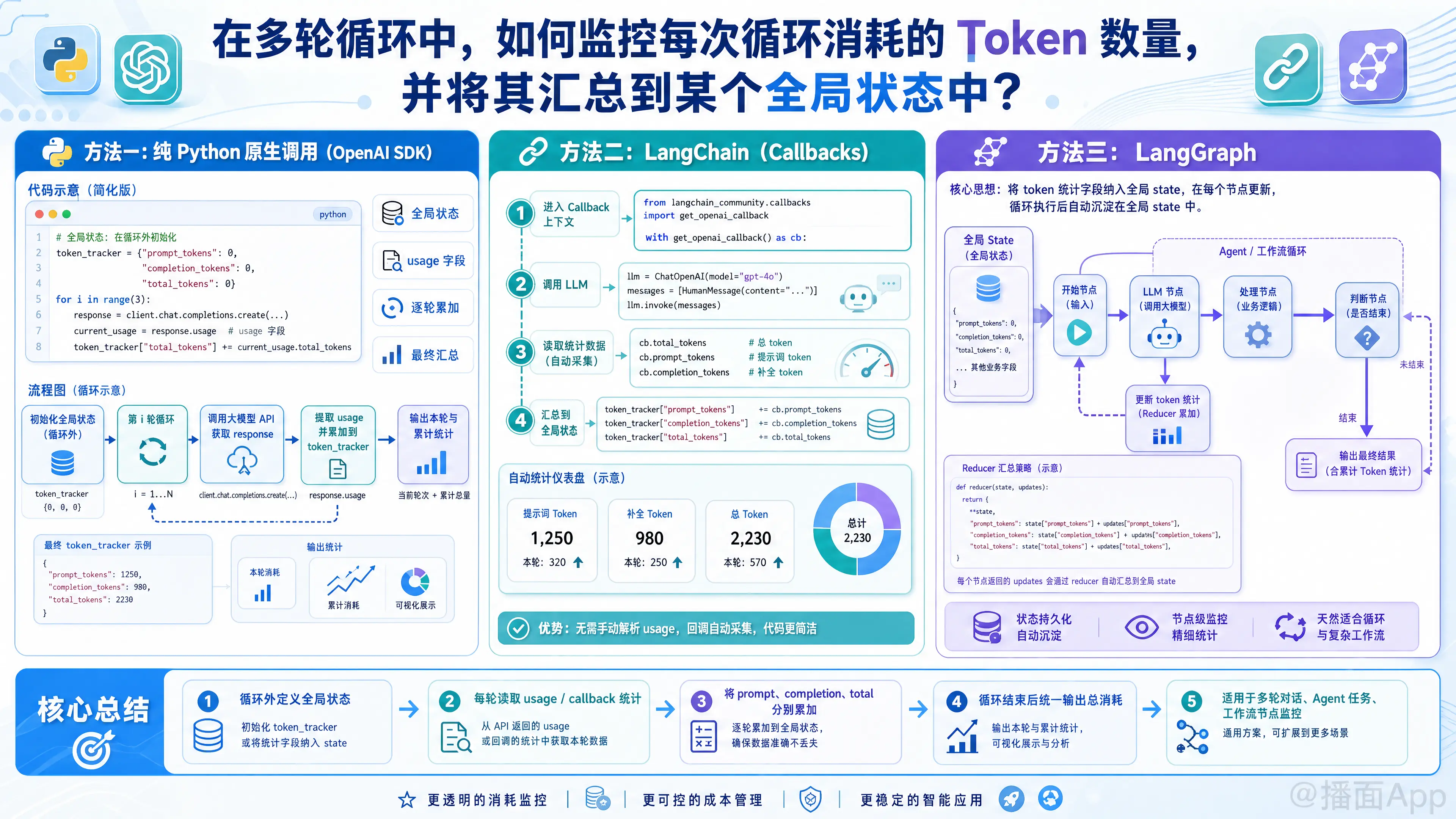
在多轮循环(例如多轮对话、Agent执行任务的循环)中监控并汇总 Token 消耗,核心思路是:在循环外部定义一个全局状态(变量或对象),在每次循环内部解析大模型 API 返回的 usage 信息,并将其累加到全局状态中。
具体实现方式取决于你使用的技术栈。以下提供三种最常见的场景和代码示例:纯代码(以 OpenAI 为例)、LangChain 以及 LangGraph。
方法一:纯 Python 原生调用(以 OpenAI SDK 为例)
这是最基础也最直观的方法。大模型的 API 响应体中通常都会带有一个 usage 字段。
python
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
# 1. 定义全局状态 (Global State)
token_tracker = {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
messages = [{"role": "system", "content": "你是一个有用的助手。"}]
# 多轮循环
for i in range(3):
user_input = f"这是第 {i+1} 轮提问"
messages.append({"role": "user", "content": user_input})
# 2. 调用 API
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
# 3. 提取当前循环的 Token 消耗
current_usage = response.usage
# 4. 汇总到全局状态
if current_usage:
token_tracker["prompt_tokens"] += current_usage.prompt_tokens
token_tracker["completion_tokens"] += current_usage.completion_tokens
token_tracker["total_tokens"] += current_usage.total_tokens
print(f"--- 第 {i+1} 轮消耗 ---")
print(f"本次消耗: {current_usage.total_tokens} tokens")
print(f"累计消耗: {token_tracker['total_tokens']} tokens\n")
# 把助手的回复加入历史记录
messages.append({"role": "assistant", "content": response.choices[0].message.content})
print("=== 最终全局 Token 统计 ===")
print(token_tracker)方法二:使用 LangChain (通过 Callbacks)
在 LangChain 中,API 的返回结果被封装了,直接获取 token 有时不方便。官方推荐使用回调机制 (Callbacks),特别是 get_openai_callback。
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_community.callbacks import get_openai_callback
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# 1. 定义全局状态
class GlobalTokenState:
def __init__(self):
self.total_tokens = 0
self.total_cost = 0.0
global_state = GlobalTokenState()
messages = []
# 多轮循环
for i in range(3):
messages.append(HumanMessage(content=f"讲一个关于数字 {i} 的短笑话"))
# 2. 使用上下文管理器捕获单次循环的 Token
with get_openai_callback() as cb:
response = llm.invoke(messages)
# 3. 将单次消耗汇总到全局状态
global_state.total_tokens += cb.total_tokens
global_state.total_cost += cb.total_cost
print(f"第 {i+1} 轮消耗: {cb.total_tokens} tokens")
messages.append(response)
print("\n=== 全局统计 ===")
print(f"总计 Token: {global_state.total_tokens}")
print(f"总计花费: ${global_state.total_cost:.6f}")注:如果你将 with get_openai_callback() as cb: 放在 for 循环的*外面,它会自动帮你把整个循环所有的调用都累加在一起,无需手动写加法。*
方法三:使用 LangGraph (完美契合“全局状态”概念)
在开发复杂的 Agent 时(如 LangGraph),系统本身就是由图(Graph)和状态(State)驱动的。我们可以利用 Python 的 operator.add 完美实现自动累加。
python
import operator
from typing import Annotated, TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
# 1. 定义带有 reducer (operator.add) 的全局状态
# operator.add 会让每次返回的 token 数自动累加到原有的值上
class GraphState(TypedDict):
messages: Annotated[list, operator.add]
total_tokens: Annotated[int, operator.add] # 自动累加的全局状态
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 2. 定义节点函数
def llm_node(state: GraphState):
# 调用大模型
response = llm.invoke(state["messages"])
# 从元数据中提取本次消耗的 token
# LangChain 的 AIMessage 会把 token 放在 response_metadata 中
usage_metadata = response.response_metadata.get("token_usage", {})
current_tokens = usage_metadata.get("total_tokens", 0)
print(f"[节点执行] 本次调用消耗: {current_tokens} tokens")
# 3. 返回更新字典。由于使用了 operator.add,这里返回的值会被加到全局 state 中
return {
"messages": [response],
"total_tokens": current_tokens
}
# 构建图
workflow = StateGraph(GraphState)
workflow.add_node("agent", llm_node)
workflow.add_edge(START, "agent")
# 为了演示循环,我们简单地让它循环 3 次(实际应用中需要条件判断)
workflow.add_edge("agent", END)
app = workflow.compile()
# 初始化全局状态
initial_state = {
"messages": [("user", "你好!")],
"total_tokens": 0 # 初始值为 0
}
# 运行 (假设这里通过外层循环或者 Graph 内部条件边触发了多次)
final_state = app.invoke(initial_state)
print("\n=== Graph 执行完毕 ===")
print(f"全局汇总 Token: {final_state['total_tokens']}")💡 核心注意事项(避坑指南):
- 流式输出 (Streaming) 的问题:
- 如果开启了流式输出 (
stream=True),大部分模型 API 默认不会返回 token usage(因为数据是一点点吐出来的)。 - 解决办法: 对于 OpenAI,在调用流式接口时需要显式传入参数
stream_options={"include_usage": True}。此时,流的最后一个 chunk 的chunk.usage中会包含完整的统计信息。
- 如果开启了流式输出 (
- 区分输入和输出 Token:
- 在汇总全局状态时,建议将
Prompt Tokens(输入) 和Completion Tokens(输出) 分开记录,因为很多商业 API(如 GPT-4, Claude 3)的输入和输出单价差异很大(通常是 1:3 甚至 1:5)。
- 在汇总全局状态时,建议将
- 不同 API 提供商的字段差异:
- OpenAI/通义千问:
response.usage.total_tokens - Anthropic (Claude):字段名通常叫
input_tokens和output_tokens位于message.usage中。如果在 LangChain 中,统一封装在response_metadata中。
- OpenAI/通义千问: