 播面
播面 如果在某个 Node 调用大模型 API 时发生了超时或异常(Exception),在图中应该如何设计错误捕获机制和重试(Retry)机制?
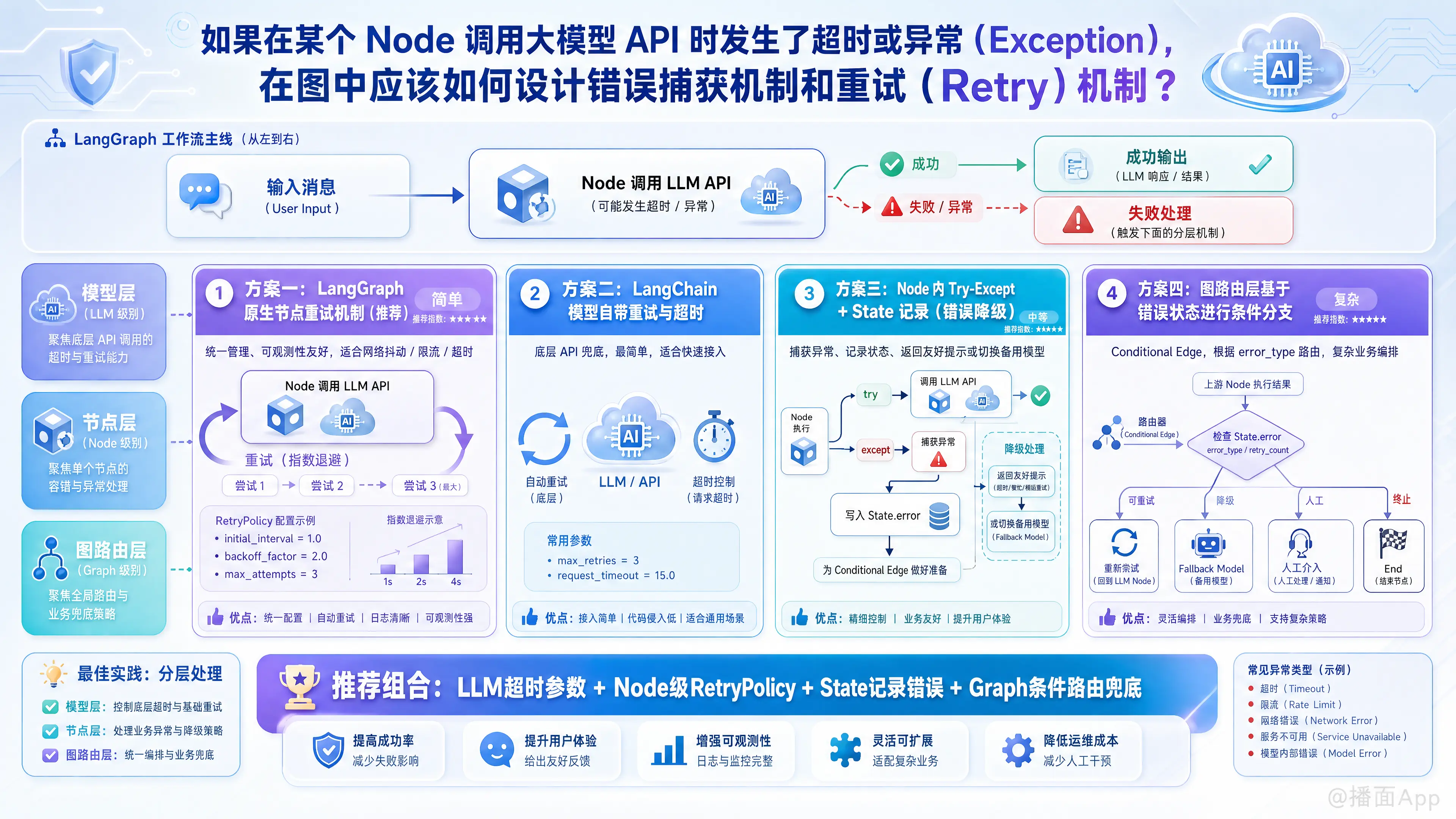
在 LangGraph 中处理大模型 API 调用时的超时或异常(Exception),最佳实践是分层处理。你可以根据具体的业务需求,在 模型层(LLM级别)、节点层(Node级别) 或 图路由层(Graph级别) 来设计重试和错误捕获机制。
以下是具体的 4 种设计方案,按照从简单到复杂的顺序排列:
方案一:使用 LangGraph 原生的节点重试机制(推荐)
LangGraph 原生支持为具体的 Node 配置 RetryPolicy。这是最推荐的方式,因为它能在图引擎级别统一管理,并且对可观测性(如 LangSmith)非常友好。
适用场景: 处理偶发的网络抖动、API 限流(Rate Limit)或超时。
python
from langgraph.graph import StateGraph
from langgraph.pregel import RetryPolicy
from langchain_openai import ChatOpenAI
# 1. 定义你的 Node
def call_llm_node(state):
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 这里可能会抛出异常
response = llm.invoke(state["messages"])
return {"messages": [response]}
workflow = StateGraph(AgentState)
# 2. 在添加节点时,直接配置 retry 策略
workflow.add_node(
"call_llm",
call_llm_node,
retry=RetryPolicy(
initial_interval=1.0, # 初始重试间隔(秒)
backoff_factor=2.0, # 指数退避因子
max_attempts=3, # 最大尝试次数(包含第一次调用)
# retry_on=[Exception], # 你可以指定只对特定的 Exception 重试
)
)方案二:使用 LangChain 模型自带的重试和超时参数
在调用底层大模型时,LangChain 的 ChatModels 本身就封装了基于 tenacity 库的重试机制,并支持设置超时时间。
适用场景: 最简单的 API 兜底,不需要复杂的图逻辑介入。
python
from langchain_openai import ChatOpenAI
def call_llm_node(state):
# 直接在模型初始化时配置
llm = ChatOpenAI(
model="gpt-3.5-turbo",
max_retries=3, # 最大重试次数
request_timeout=15.0, # 设置超时时间(秒),防止节点卡死
)
response = llm.invoke(state["messages"])
return {"messages": [response]}方案三:Node 内部的 Try-Except + State 状态记录(错误降级)
如果重试了依然失败,或者你想根据不同的错误类型执行不同的业务逻辑(比如:超时返回特定文案、抛错则切换备用模型),你应该在 Node 内部捕获异常,并将错误信息写入 State 中。
适用场景: 需要记录错误状态、返回友好的用户提示、或为后续的条件路由(Conditional Edge)做准备。
python
from typing import TypedDict, Optional
# 1. 在 State 中增加 error 字段
class AgentState(TypedDict):
messages: list
error: Optional[str]
def call_llm_node(state):
llm = ChatOpenAI(model="gpt-3.5-turbo", request_timeout=10)
try:
response = llm.invoke(state["messages"])
# 成功时,清空 error
return {"messages": [response], "error": None}
except TimeoutError:
# 捕获超时异常
return {"error": "API Request Timed Out"}
except Exception as e:
# 捕获其他异常
return {"error": f"LLM Error: {str(e)}"}方案四:基于 Conditional Edge 的全局错误路由(Fallback 机制)
结合方案三,如果你希望在主模型(如 GPT-4)发生异常时,图能够自动路由到降级节点(如调用更便宜稳定的模型 GPT-3.5,或者转交人工处理),你可以使用条件边(Conditional Edges)。
适用场景: 复杂的企业级容灾处理、模型 Fallback(备用模型)。
python
# --- 节点定义 ---
def primary_llm_node(state):
try:
llm = ChatOpenAI(model="gpt-4", request_timeout=10)
res = llm.invoke(state["messages"])
return {"messages": [res], "error": None}
except Exception as e:
return {"error": str(e)} # 记录错误
def fallback_llm_node(state):
# 备用轻量级模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
res = llm.invoke(state["messages"])
return {"messages": [res]}
def error_handler_node(state):
# 彻底失败的兜底回复
return {"messages": [{"role": "assistant", "content": "系统繁忙,请稍后再试。"}]}
# --- 路由函数 ---
def route_after_primary(state) -> str:
if state.get("error"):
return "fallback" # 如果有错误,去备用节点
return "end" # 成功则结束
# --- 构建图 ---
workflow = StateGraph(AgentState)
workflow.add_node("primary", primary_llm_node)
workflow.add_node("fallback", fallback_llm_node)
workflow.set_entry_point("primary")
# 根据 primary 节点的结果进行路由
workflow.add_conditional_edges(
"primary",
route_after_primary,
{
"fallback": "fallback",
"end": END
}
)
workflow.add_edge("fallback", END)总结与建议
在实际生产的 LangGraph 应用中,通常是组合使用上述方案的:
- 第一道防线(防抖):使用 方案一 (LangGraph RetryPolicy) 或 方案二 (LangChain max_retries) 来处理短暂的网络超时和 API 500 错误。
- 第二道防线(降级/容灾):如果重试依然失败(抛出异常),使用 方案三 (Try-Except) 捕获它,将错误状态写入
State。 - 第三道防线(业务兜底):使用 方案四 (Conditional Edge) 读取
State中的错误标记,将流程路由到 Fallback 模型或向用户返回友好的错误提示。