 播面
播面 LangGraph的State(状态)
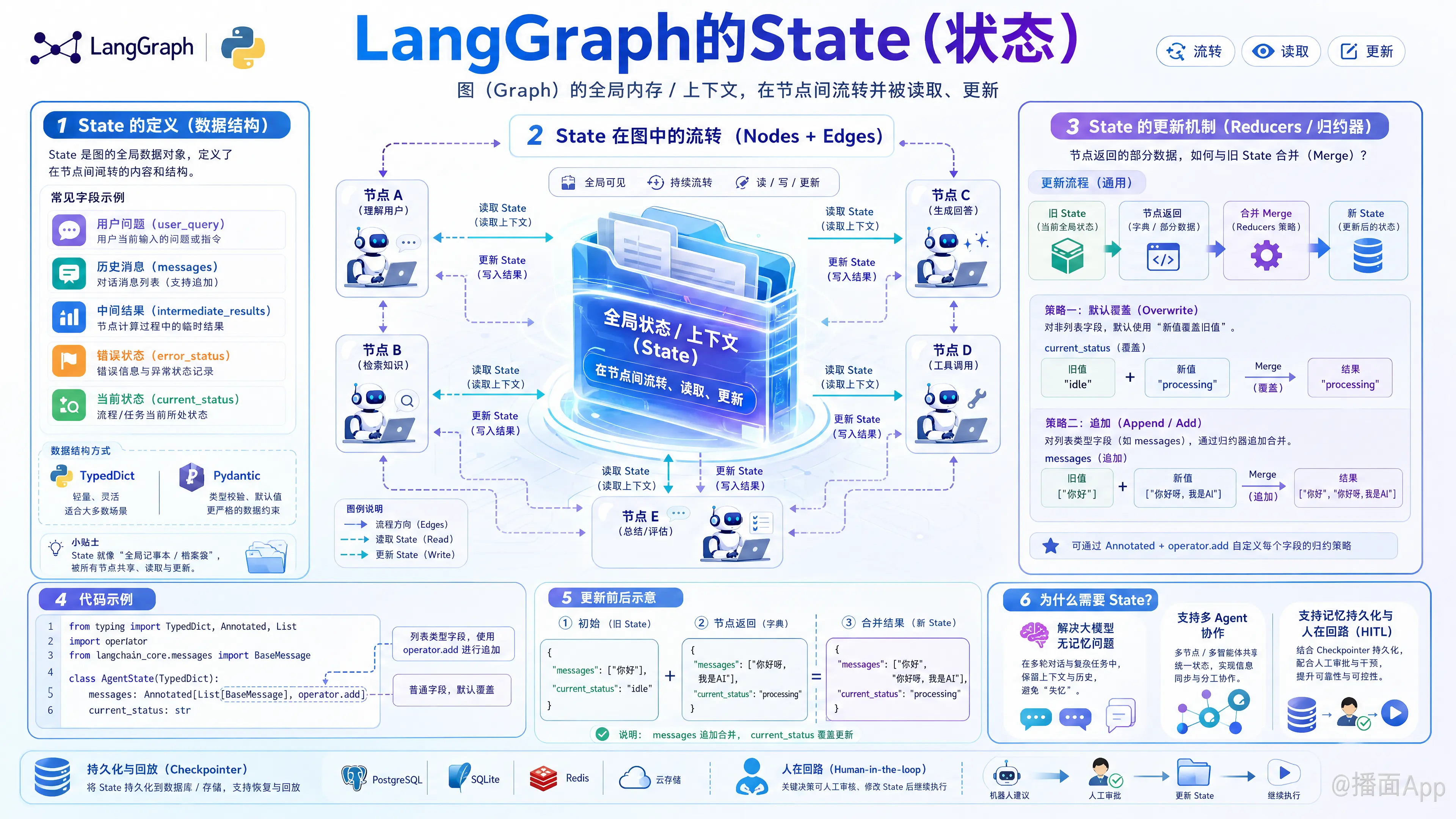
在 LangGraph 中,State(状态) 是整个框架的核心概念。你可以把它理解为整个图(Graph)的“全局内存”或“上下文”。
在 LangGraph 构成的应用(通常是 AI Agent)中,工作流程被抽象为图中的各个节点(Nodes)和边(Edges)。而 State 就是在这些节点之间流转、读取和更新的数据对象。
简单来说,可以打个比方:如果把 LangGraph 的运行过程看作一条流水线,各个节点是流水线上的工人,那么 State 就是那个在传送带上不断被传递、修改和添加内容的“档案袋”。
以下是关于 LangGraph 中 State 的几个关键点:
1. State 的定义(数据结构)
State 通常通过 Python 的 TypedDict 或 Pydantic 模型来定义。你可以在其中声明你的应用需要追踪哪些变量。例如:用户的提问、大模型生成的历史消息、中间计算的临时结果、错误状态等。
2. State 的更新机制(Reducers / 归约器)
这是 LangGraph 中最重要的一点。当一个节点执行完毕后,它会返回一个字典。这个返回的字典并不会直接替换掉原来的 State,而是“合并(Merge)”到现有的 State 中。
LangGraph 允许你为 State 中的每个字段定义更新策略(Reducer):
- 默认覆盖(Overwrite): 如果你不做特殊说明,节点返回的新值会直接覆盖旧值。
- 追加(Append / Add): 对于聊天记录(Messages)等数据,你通常希望是把新消息加到列表末尾,而不是覆盖它。这时你需要使用
Annotated和特定的操作符(如operator.add)。
3. 代码示例
为了让你更直观地理解,请看下面这个经典的 State 定义示例:
from typing import TypedDict, Annotated, List
import operator
from langchain_core.messages import BaseMessage
# 1. 定义 State 的结构
class AgentState(TypedDict):
# 使用 Annotated 和 operator.add,表示当有新数据时,追加到列表中
messages: Annotated[List[BaseMessage], operator.add]
# 没有 Annotated,默认行为:当有新数据时,直接覆盖旧值
current_status: str在图中的运行逻辑:
假设当前 AgentState 里的数据是:{"messages": ["你好"], "current_status": "idle"}
现在,一个节点运行完毕,返回了这样的更新:{"messages": ["你好呀,我是AI"], "current_status": "processing"}
LangGraph 会根据规则更新 State,更新后的 State 会变成:{"messages": ["你好", "你好呀,我是AI"], "current_status": "processing"}
(注意:messages 被追加了,而 current_status 被覆盖了)
4. 为什么需要 State?
- 解决大模型无记忆的问题: LLM 本身是无状态的,通过 State,我们可以把对话历史和中间思考过程记录下来,每次调用大模型时把 State 里的内容传给它。
- 支持多 Agent 协作: 多个 Agent(节点)可以通过向同一个 State 读写数据来实现沟通和协作。
- 支持记忆持久化与“人在回路”(Human-in-the-loop): 因为 State 是一个结构化的数据对象,LangGraph 可以将其保存到数据库(通过 Checkpointer)。这意味着你可以在图运行到一半时暂停(比如等待用户确认),未来再从数据库提取 State 并继续运行。
总结:
在 LangGraph 中,State 是定义应用数据的结构,是连接各个节点的桥梁,也是 Agent 思考和执行任务时依赖的“记忆库”。 所有的节点逻辑都是围绕“读取 State -> 处理 -> 返回更新后的 State”这一核心循环展开的。