 播面
播面 使用 LangGraph 从头构建一个简单的问答机器人(Single-Agent)的 4 个基本核心步骤
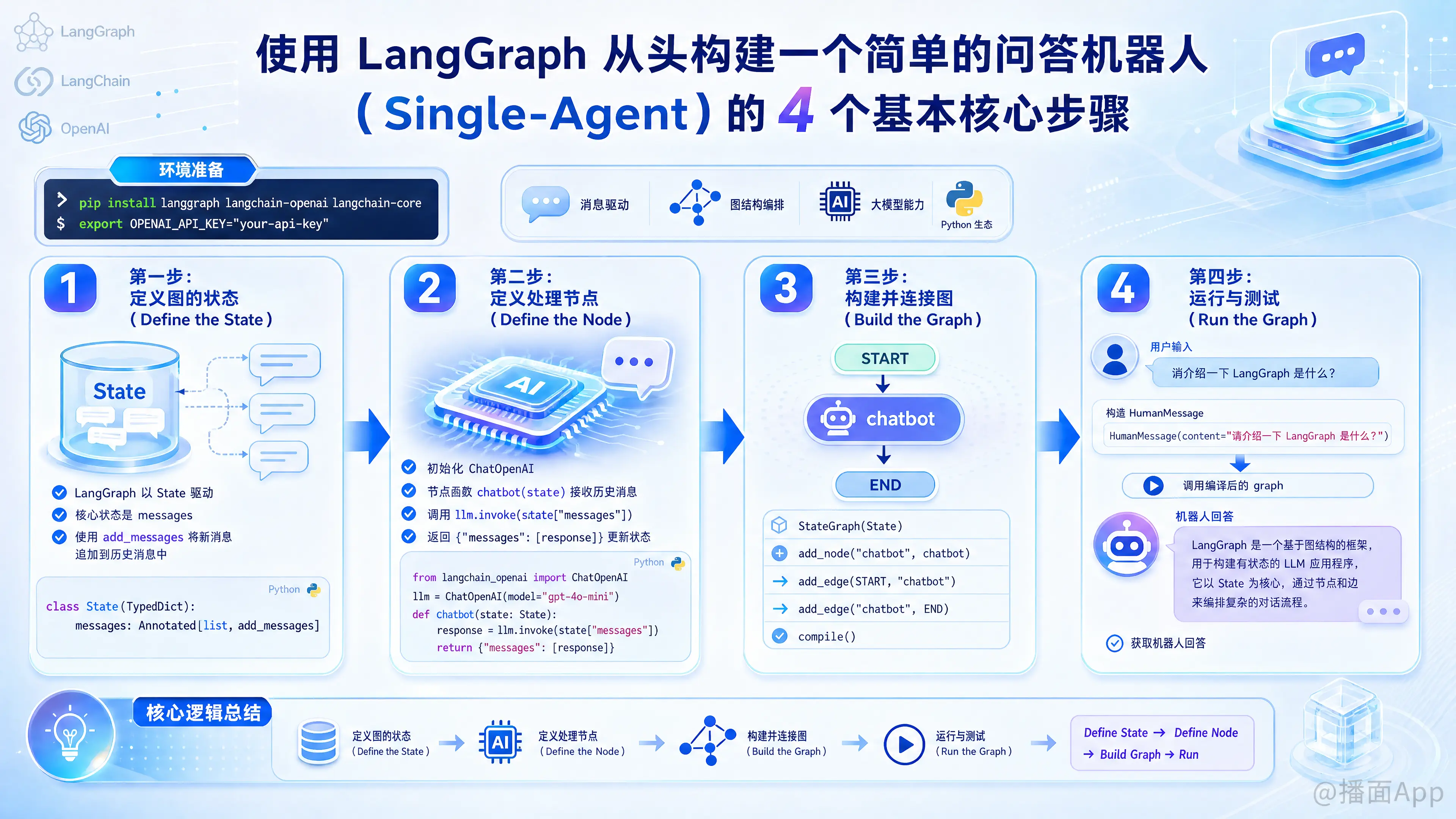
使用 LangGraph 从头构建一个单体智能体(Single-Agent)问答机器人,核心逻辑可以提炼为 4 个基本步骤:定义状态(State)、定义节点(Node)、构建图(Graph)、编译与运行(Run)。
在开始之前,请确保你已经安装了必要的依赖并设置了环境变量(如 OpenAI API Key):
bash
pip install langgraph langchain-openai langchain-core
export OPENAI_API_KEY="your-api-key"以下是完整的 4 个核心步骤:
第一步:定义图的状态(Define the State)
LangGraph 是基于“状态(State)”驱动的。每一次交互,数据都会保存在状态中并在节点之间传递。对于一个问答机器人,最核心的状态就是聊天记录(Messages)。
python
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
# 定义状态字典
class State(TypedDict):
# 使用 add_messages 这是一个 reducer,它的作用是把新的消息追加到现有消息列表中,而不是覆盖它们
messages: Annotated[list, add_messages]第二步:定义处理节点(Define the Node)
节点(Node)是图中真正执行动作的地方。对于简单的问答机器人,我们只需要一个节点:调用大语言模型(LLM)。该节点接收当前状态,把消息发给 LLM,并将 LLM 的回复返回以更新状态。
python
from langchain_openai import ChatOpenAI
# 1. 初始化大模型
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# 2. 定义节点函数
def chatbot(state: State):
# state["messages"] 包含了历史所有的对话内容
response = llm.invoke(state["messages"])
# 返回的结果会自动通过第一步定义的 add_messages 追加到状态中
return {"messages": [response]}第三步:构建并连接图(Build the Graph)
现在我们将状态和节点组合起来,定义数据的流向(边 Edge)。由于是简单的 Q&A 机器人,流程非常简单:开始 -> 大模型节点 -> 结束。
python
from langgraph.graph import StateGraph, START, END
# 1. 初始化图,并传入第一步定义的状态
graph_builder = StateGraph(State)
# 2. 将第二步定义的函数作为一个节点添加到图中,命名为 "chatbot"
graph_builder.add_node("chatbot", chatbot)
# 3. 定义边(流程走向)
graph_builder.add_edge(START, "chatbot") # 从 START 节点流向 chatbot 节点
graph_builder.add_edge("chatbot", END) # 从 chatbot 节点流向 END 节点
# 4. 编译图,使其变成可执行的 Runnable 对象
graph = graph_builder.compile()第四步:运行与测试(Run the Graph)
最后一步,我们构造用户输入,将其传入编译好的图中,并获取机器人的回答。
python
from langchain_core.messages import HumanMessage
# 1. 构造用户的提问(初始状态)
user_input = "你好,请用一句话解释什么是 LangGraph?"
initial_state = {"messages": [HumanMessage(content=user_input)]}
# 2. 运行图并流式输出结果
print(f"用户: {user_input}")
# 使用 stream 方法可以查看图中每个节点的输出
for event in graph.stream(initial_state):
for node_name, node_state in event.items():
if node_name == "chatbot":
# 打印机器人最新的一条回复
print(f"Bot: {node_state['messages'][-1].content}")总结(完整代码概览)
将以上 4 个步骤组合在一起,就是一段不到 30 行的完整且具备记忆扩展能力的 LangGraph 问答机器人代码:
python
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from langchain_core.messages import HumanMessage
# 1. State
class State(TypedDict):
messages: Annotated[list, add_messages]
# 2. Node
llm = ChatOpenAI(model="gpt-3.5-turbo")
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
# 3. Graph
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()
# 4. Run
user_input = "LangGraph是什么?"
for event in graph.stream({"messages": [HumanMessage(content=user_input)]}):
for node_name, value in event.items():
print(f"Bot: {value['messages'][-1].content}")为什么用 LangGraph 而不是直接调用 LLM?
虽然这个例子极其简单,但 LangGraph 为未来的扩展打下了基础。如果你想在这个机器人的基础上增加网络搜索功能、人类循环干预(Human-in-the-loop)或根据意图路由到不同模型,只需要在第 2 步增加更多的节点,在第 3 步修改图的连线(边)逻辑即可,非常具有扩展性。