 播面
播面 MongoDB的副本集和分片的区别?
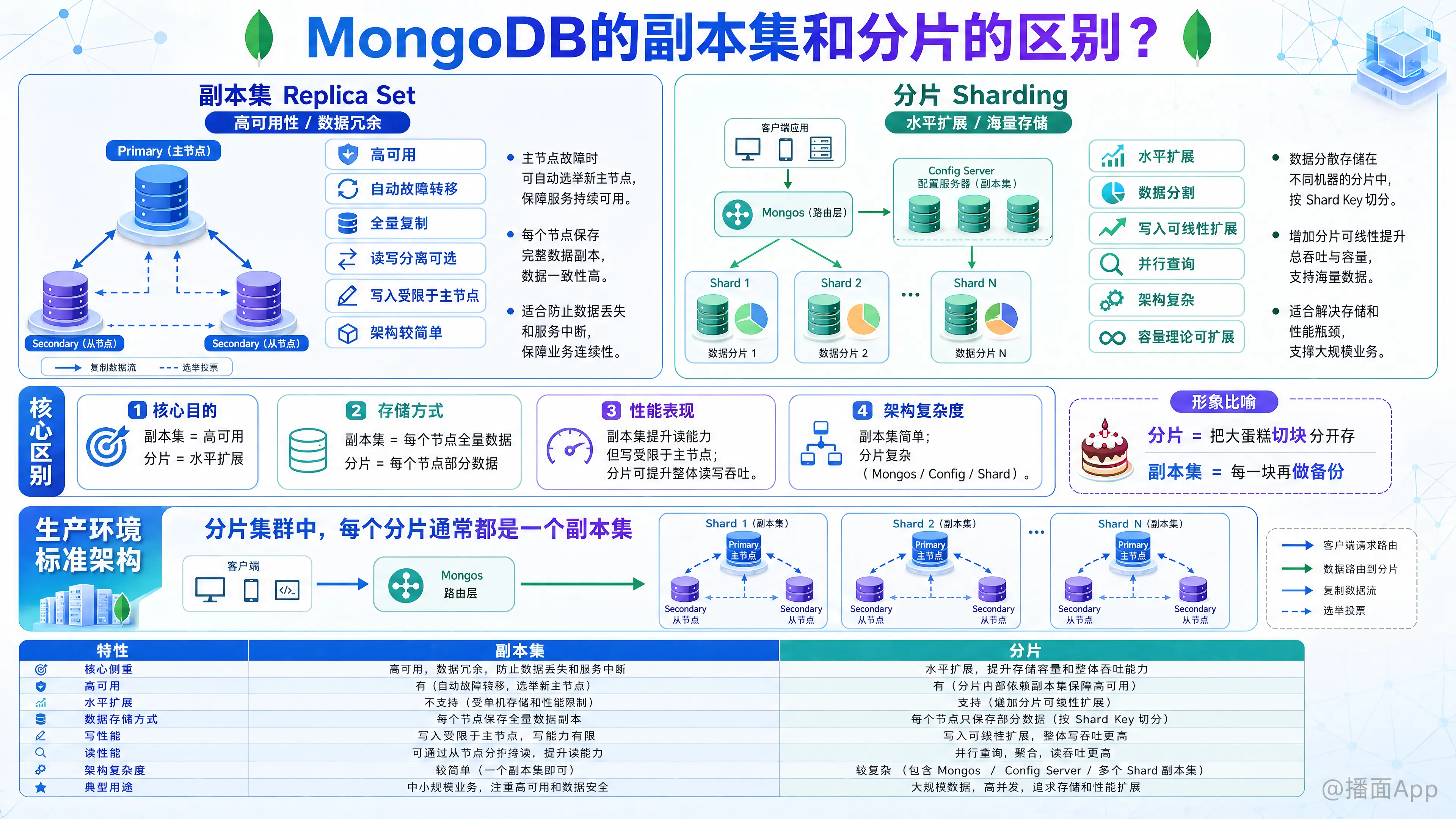
MongoDB 的 副本集 (Replica Set) 和 分片 (Sharding) 是 MongoDB 实现高性能架构的两个核心概念,它们解决的问题截然不同。
简单的一句话总结:副本集是为了“高可用性”(数据不丢、服务不停),分片是为了“水平扩展”(存得更多、写得更快)。
以下是详细的对比分析:
1. 核心目的不同
- 副本集 (Replica Set):
- 目标:高可用性 (High Availability) 和 数据冗余。
- 解决的问题: 防止硬件故障导致数据丢失或服务中断。如果主节点挂了,副本集会自动选举一个新的主节点,保证业务不中断。
- 分片 (Sharding):
- 目标:水平扩展 (Horizontal Scaling) 和 海量存储。
- 解决的问题: 单台服务器的磁盘不够用了(存储瓶颈),或者单台服务器的 CPU/内存处理不过来海量的并发写入了(性能瓶颈)。
2. 数据存储方式不同
- 副本集:全量复制
- 副本集中的每一个节点(Primary 和 Secondary)都保存着一份完整的数据拷贝。
- 如果有 3 个节点,数据就被存储了 3 次。
- 限制: 整个集群的存储上限受限于单台机器的磁盘容量。
- 分片:数据分割
- 分片是将海量数据按照一定的规则(Shard Key)切分成多块,分散存储在不同的机器(Shard)上。
- 每个分片只保存一部分数据。所有分片的数据加起来才是完整的数据集。
- 优势: 理论上存储容量可以无限扩展。
3. 读写性能表现不同
- 副本集:
- 写性能: 受限于单台主节点(Primary)的性能。因为所有写操作必须先在主节点执行,然后复制到从节点。增加节点不能提高写性能。
- 读性能: 默认读主节点。可以通过设置读偏好(Read Preference)从从节点读取来实现读写分离,从而提升读性能,但会有数据延迟问题。
- 分片:
- 写性能: 可以线性扩展。通过增加分片数量,将写入压力分摊到多台机器上,从而大幅提升系统的总写入吞吐量。
- 读性能: 并发读取能力极强,查询请求会被路由(Mongos)分发到对应的分片上并行处理。
4. 架构复杂度
- 副本集: 架构相对简单。通常由 1 个 Primary(主)和 N 个 Secondary(从)组成。客户端直接连接副本集。
- 分片: 架构非常复杂。包含三个主要组件:
- Mongos (路由): 接收客户端请求,负责分发。
- Config Server (配置服务器): 存储元数据(数据在哪台机器上)。
- Shard (分片): 实际存储数据的节点。
5. 它们的关系(重要!)
在生产环境中,这两者通常是结合使用的,而不是二选一。
生产环境的标准架构是:分片集群,其中每个分片都是一个副本集。
- 为什么要结合?
- 如果你只用分片不用副本集:如果某个分片服务器坏了,那一部分数据就彻底丢了。
- 如果你只用副本集不用分片:数据量达到几十 TB 时,单机存不下,且恢复数据极慢。
- 形象比喻:
- 分片就像是把一个巨大的蛋糕切成 10 块,分给 10 个人保管(为了拿得动)。
- 副本集就像是给这 10 块蛋糕的每一块都做了 2 个备份(为了防止保管蛋糕的人把蛋糕弄丢了)。
总结对比表
| 特性 | 副本集 (Replica Set) | 分片 (Sharding) |
|---|---|---|
| 核心侧重 | 高可用性、数据安全 | 高性能、海量存储、水平扩展 |
| 数据分布 | 每个节点都有全部数据 | 每个节点只有部分数据 |
| 写能力 | 受限于单机性能 (不可扩展) | 可通过增加机器线性扩展 |
| 存储容量 | 受限于单机磁盘容量 | 理论无上限 (取决于机器数量) |
| 故障恢复 | 自动故障转移 (Failover) | 单个分片故障可能导致部分数据不可用 (除非该分片也是副本集) |
| 适用场景 | 数据量中小,读多写少,要求数据不丢 | 海量数据 (TB/PB级),高并发写入 |
什么时候用哪个?
- 起步阶段: 总是先使用 副本集。它配置简单,能保证数据安全。对于绝大多数应用,3 节点的副本集足以支撑数千万级的数据量和不错的读写并发。
- 进阶阶段: 只有当遇到以下瓶颈时,才考虑 分片:
- 单机磁盘存不下了(例如超过 2TB)。
- 工作集(Working Set)超过了单机内存,导致频繁磁盘交换,性能急剧下降。
- 单机的写入速度已经达到物理极限,无法满足业务需求。