 播面
播面 MongoDB中如何选择一个好的片键?
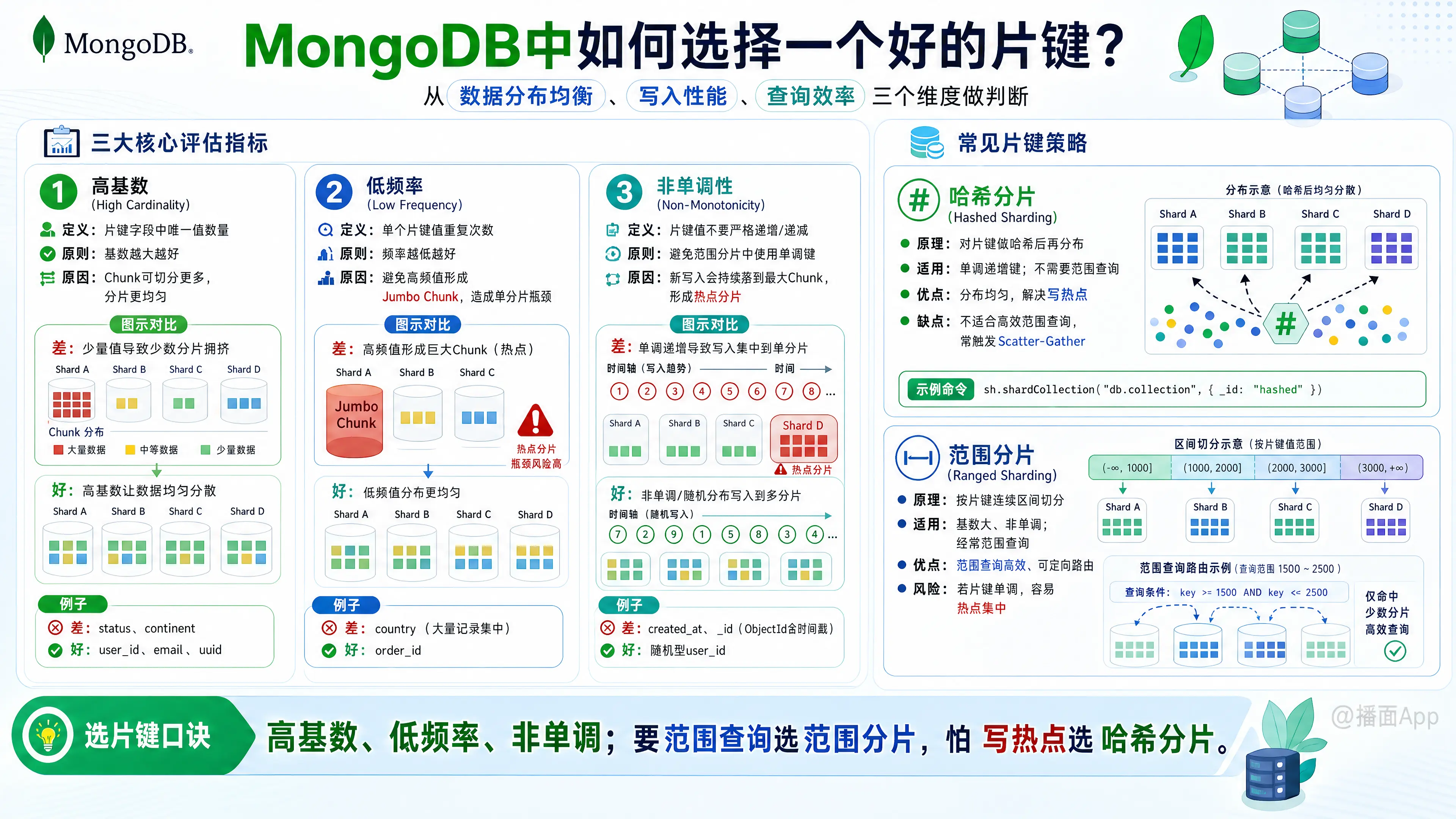
在MongoDB中选择一个好的片键(Shard Key)是至关重要的,因为它直接决定了集群的数据分布均衡性、写入性能以及查询效率。一旦选定,虽然新版本(5.0+)支持重新分片(Resharding),但这仍然是一个消耗巨大的操作,因此“一次选对”非常重要。
选择片键时,需要权衡三个核心指标:基数(Cardinality)、频率(Frequency)和单调性(Monotonicity)。
以下是选择好片键的详细指南:
一、 三大核心评估指标
1. 高基数 (High Cardinality)
- 定义:片键字段中包含的唯一值的数量。
- 原则:基数越大越好。
- 原因:MongoDB通过将数据切分为Chunk(数据块)来分布。如果基数太低(例如只有“男/女”两个值),那么最多只能生成几个Chunk,无论你有多少个分片服务器,数据都无法均匀分布,大部分服务器将处于空闲状态。
- 例子:
- ❌ 差:
status(只有 active, inactive 等几个值) - ❌ 差:
continent(只有7个值) - ✅ 好:
user_id,email,uuid
- ❌ 差:
2. 低频率 (Low Frequency)
- 定义:单个片键值在数据集中出现的重复次数。
- 原则:频率越低越好。
- 原因:如果某个特定的片键值出现频率极高(例如某个大V用户的
user_id产生了数百万条记录),会导致包含该值的 Chunk 变得巨大且无法分割(Jumbo Chunk)。这会导致该 Chunk 所在的的分片成为瓶颈。 - 例子:
- ❌ 差:
country(如果大部分用户都来自“中国”,那么“中国”这个值的Chunk会巨大) - ✅ 好:
order_id(每个订单号通常只出现一次或很少几次)
- ❌ 差:
3. 非单调性 (Non-Monotonically Change)
- 定义:片键值的增长是否是严格递增或递减的。
- 原则:避免在范围分片中使用单调键。
- 原因:如果使用时间戳或自增ID作为范围分片(Range Sharding)的片键,新写入的数据永远会落在数值最大的那个 Chunk 上。这意味着所有的写入压力都会集中在同一个分片(即“热点分片”),失去了分片分散写入压力的意义。
- 例子:
- ❌ 差(用于范围分片):
created_at,_id(ObjectId 包含时间戳) - ✅ 好(用于范围分片):
user_id(如果是随机生成的)
- ❌ 差(用于范围分片):
二、 常见的片键策略
根据上述指标,通常有三种主要的策略:
1. 哈希分片 (Hashed Sharding)
- 原理:MongoDB 计算片键字段的哈希值,并根据哈希值进行范围分布。
- 适用场景:
- 片键值是单调递增的(如
_id,timestamp)。 - 不需要对片键进行范围查询。
- 片键值是单调递增的(如
- 优点:数据分布非常均匀,完美解决单调递增导致的写入热点问题。
- 缺点:无法高效支持范围查询。例如
find({ x: { $gt: 100 } }),因为哈希后数值是乱序的,mongos 必须向所有分片广播查询(Scatter-Gather),效率低下。 - 配置示例:
sh.shardCollection("db.collection", { _id: "hashed" })
2. 范围分片 (Ranged Sharding)
- 原理:直接根据片键的值将数据切分为连续的范围。
- 适用场景:
- 片键基数大且非单调。
- 经常需要对片键进行范围查询(如
a > 10 and a < 20)。
- 优点:范围查询效率极高,mongos 知道数据在哪个分片,可以直接定位(Targeted Query)。
- 缺点:如果选了单调递增的字段,会造成严重的写入热点。
3. 复合分片 (Compound Sharding)
- 原理:使用多个字段作为片键。
- 适用场景:单一字段无法满足基数或频率要求,或者需要优化特定的查询模式。
- 常见组合模式:
- { 低基数 + 高基数 }:例如
{ region: 1, _id: 1 }。这允许你将数据按地区分组(利用局部性),同时利用_id保证 Chunk 的可分割性。 - { 粗粒度周期 + 单调键 }:例如
{ month: 1, timestamp: 1 }。写入时只会在当前的“月”分片上产生热点,但比纯时间戳要好一些,且利于按月归档。
- { 低基数 + 高基数 }:例如
三、 结合查询模式 (Query Isolation)
仅仅考虑数据分布是不够的,查询性能同样重要。
查询隔离(Targeted Queries):
- 最好的片键应该包含在你的大部分核心查询条件中。
- 如果查询包含片键,mongos 可以直接路由到特定分片(效率高)。
- 如果查询不包含片键,mongos 必须向所有分片发送请求(Scatter-Gather),这会随着分片数量增加而导致延迟显著增加。
排序性能:
- 如果使用了哈希分片,按该字段排序是低效的(因为数据在物理上是乱序的)。
- 如果使用了范围分片,按片键排序非常高效。
四、 决策流程图(Cheat Sheet)
在选择时,可以问自己以下问题:
这个字段的基数大吗?
- 否 -> ❌ 别用,或者把它作为复合片键的前缀。
- 是 -> 继续。
你会频繁对这个字段做范围查询吗(> < >= <=)?
- 是 -> 必须用范围分片。但要确保该字段不是单调递增的。如果是单调的,考虑复合片键。
- 否 -> 考虑哈希分片。
这个字段是单调递增的吗(如时间、自增ID)?
- 是 -> 必须用哈希分片(除非是复合片键的后缀)。
- 否 -> 可以用范围分片。
你的核心业务查询包含这个字段吗?
- 是 -> ✅ 这是一个好的候选片键。
- 否 -> ⚠️ 慎重。这会导致查询广播,消耗集群资源。
五、 经典案例分析
场景 A:用户系统
- 数据:用户资料,ID为UUID。
- 查询:主要是
db.users.find({ user_id: "..." })。 - 最佳片键:
{ user_id: "hashed" }。 - 理由:基数大,查询精确匹配,哈希能保证分布极其均匀。
场景 B:物联网(IoT)传感器日志
- 数据:包含
device_id和timestamp。 - 查询:经常查询某台设备在某个时间段的数据
find({ device_id: "A", timestamp: { $gt: ... } })。 - 最佳片键:
{ device_id: 1, timestamp: 1 }(复合范围分片)。 - 理由:
device_id提供了基数。- 将
device_id放在前面,保证了针对特定设备的查询能直接定位到特定分片。 timestamp在后,支持对该设备的时间范围查询。- 注意:如果
device_id是单调递增生成的,可能需要对device_id进行哈希,即{ device_id: "hashed", timestamp: 1 }(MongoDB 4.4+ 支持)。
场景 C:订单系统
- 数据:包含
order_id(自增) 和created_time。 - 查询:既有按ID查,也有按时间范围查报表。
- 最佳片键:这是一个权衡。
- 如果写入性能是瓶颈:使用
{ order_id: "hashed" }。 - 如果时间范围查询是瓶颈且写入量尚可:考虑
{ created_time: 1 },但要小心写入热点。 - 折中方案:应用层生成非单调的
order_id(如雪花算法+随机位),然后使用范围分片。
- 如果写入性能是瓶颈:使用
总结
一个完美的片键公式通常是:
高基数 + 低频率 + (非单调 OR 哈希) + 覆盖核心查询