 播面
播面 如何实现分页查询?当数据量很大时,skip() 和 limit() 会有什么性能问题?
这是一个非常经典且高频的后端面试题,也是实际开发中处理大数据量时必须面对的挑战。
以下我将分三个部分来回答:基本实现方式、性能问题分析、以及大数据量下的优化方案。
一、 基本的分页实现
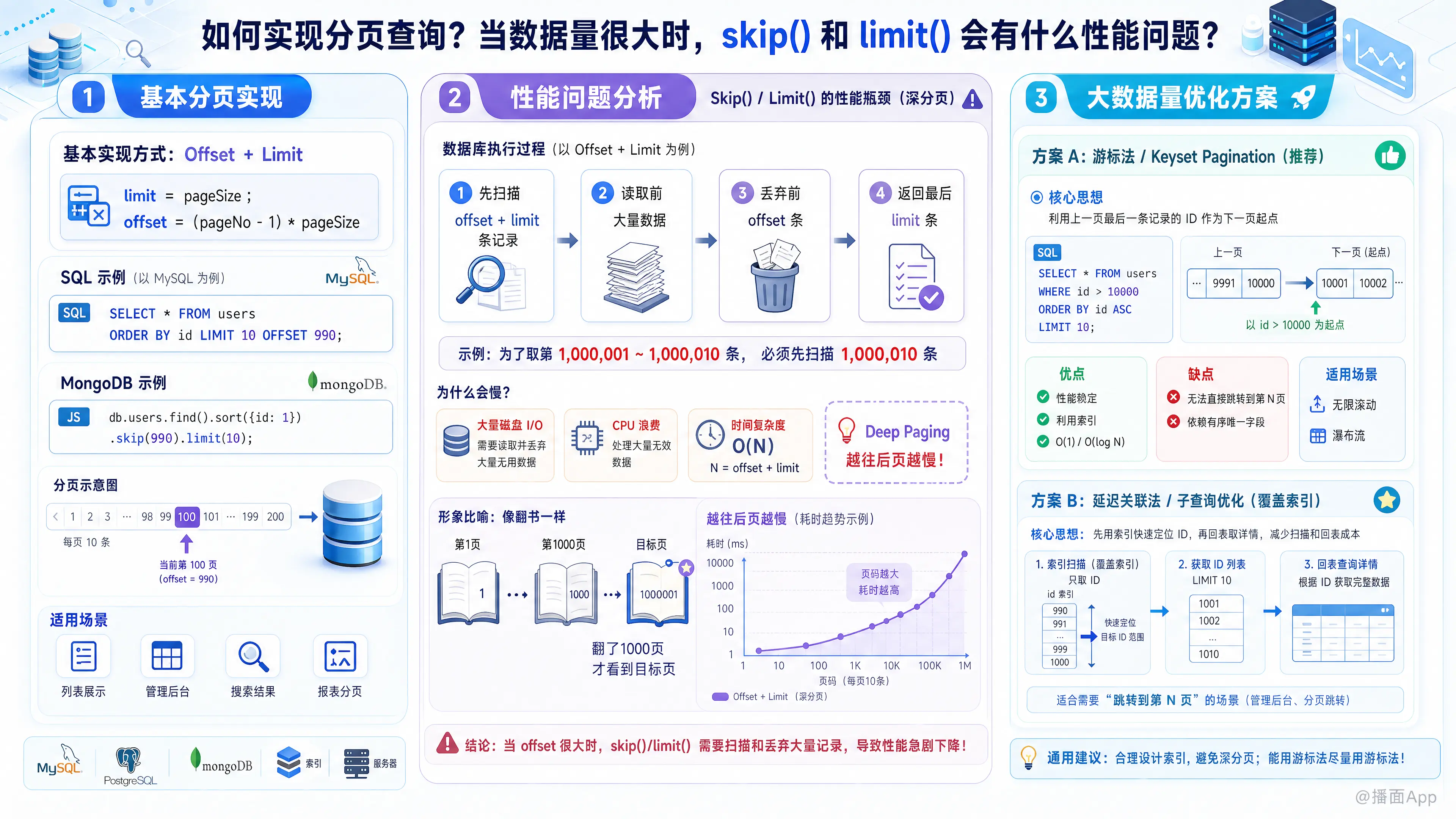
在绝大多数数据库(如 MySQL、PostgreSQL、MongoDB)中,最简单的分页通常是基于 Offset(偏移量) 和 Limit(限制条数) 实现的。
假设每页显示 pageSize 条数据,要查询第 pageNo 页的数据:
公式:
limit = pageSizeoffset = (pageNo - 1) * pageSize
SQL 示例 (MySQL):
-- 查询第 100 页,每页 10 条
SELECT * FROM users
ORDER BY id
LIMIT 10 OFFSET 990;MongoDB 示例:
db.users.find().sort({id: 1}).skip(990).limit(10);二、 Skip() 和 Limit() 的性能问题
当数据量较小(几千到几万条)时,这种方式没有问题。但当数据量达到百万、千万级,且需要查询靠后的页码(即“深分页”,Deep Paging)时,性能会急剧下降。
1. 为什么会慢?(底层原理)
数据库并不是直接“跳过”前 offset 条数据去取后面的数据。
执行过程是这样的:
- 数据库引擎(如 InnoDB)会先查询出
offset + limit条记录。 - 也就是为了取第 1,000,001 到 1,000,010 条数据,数据库必须先扫描并读取前 1,000,010 条数据。
- 然后,抛弃前 1,000,000 条数据。
- 最后返回剩下的 10 条。
2. 具体的性能瓶颈
- 大量的磁盘 I/O: 如果是
SELECT *,数据库可能需要回表(从索引跳回主表读取数据行),这会产生巨大的随机 I/O。 - CPU 浪费: 数据库花费了大量 CPU 时间去扫描和处理那些最终会被丢弃的数据。
- 时间复杂度: 这种分页的时间复杂度是 O(N),其中 N 是 offset 的大小。随着页码越往后,查询越慢。
形象的比喻:
这就像你在看书。如果你要看第 1000 页,skip/limit 的方式相当于让你必须从第 1 页开始,一页一页翻过前 999 页,才能看到第 1000 页的内容,而不是直接翻到第 1000 页。
三、 大数据量下的优化方案
针对深分页性能问题,主要有以下几种主流的优化策略:
1. 游标法 / Keyset Pagination(推荐用于无限滚动)
这是性能最好的方案,时间复杂度为 O(1) 或 O(log N)。
核心思想:
不使用 OFFSET 跳过数据,而是利用上一页最后一条数据的特征值(通常是自增 ID 或时间戳)作为查询条件,直接定位下一页的起点。
实现方式:
假设上一页最后一条数据的 ID 是 10000。
-- 获取下一页
SELECT * FROM users
WHERE id > 10000
ORDER BY id ASC
LIMIT 10;- 优点: 无论翻到多少页,性能都一样快,因为利用了索引直接定位。
- 缺点:
- 无法跳转: 只能“下一页”,不能直接跳转到第 100 页(因为不知道第 100 页的起始 ID 是多少)。
- 依赖连续性: 需要依赖一个有序且唯一的字段(如 ID)。
适用场景: 移动端的“瀑布流”、“无限滚动”加载。
2. 延迟关联法 / 子查询优化(覆盖索引)
如果你必须支持“跳转到第 N 页”的功能,可以使用这种方法来大幅提升性能。
核心思想:
利用覆盖索引(Covering Index)。先只查询 ID(因为 ID 在索引上,不需要回表读取数据行,速度很快),通过 OFFSET 找到目标 ID 后,再通过 INNER JOIN 去查询完整数据。
优化前(慢):
SELECT * FROM users LIMIT 10 OFFSET 1000000;优化后(快):
SELECT t1.*
FROM users t1
INNER JOIN (
-- 这里只查 ID,利用覆盖索引,不回表,速度快很多
SELECT id FROM users ORDER BY id LIMIT 10 OFFSET 1000000
) t2 ON t1.id = t2.id;- 原理: 内部子查询虽然也扫描了 100 万个索引节点,但因为索引很小且紧凑,且不需要读取数据文件,所以速度比全表扫描快得多。拿到 10 个 ID 后,再回表取 10 条完整数据,效率极高。
3. 记录 ID 范围(预计算)
如果数据 ID 是连续的(没有物理删除),可以计算出 ID 范围。
公式: id >= (pageNo - 1) * pageSize
SELECT * FROM users
WHERE id >= 1000000
LIMIT 10;- 缺点: 现实中很难保证 ID 绝对连续(因为会有删除操作),这会导致每页数量不一致。
4. 限制最大分页深度
从产品设计角度解决技术问题。
- 策略: 像百度、谷歌搜索一样,虽然显示有几百万条结果,但通常只允许你翻到第 70-100 页。
- 理由: 用户几乎不会查看 100 页以后的数据。如果用户真的需要查特定数据,应该引导他们使用更精确的搜索条件,而不是翻页。
5. 使用搜索引擎(Elasticsearch)
如果数据量达到亿级,且查询条件复杂,MySQL 可能不再适合做分页查询。
- Elasticsearch 的
search_after: 类似于数据库的游标法。 - Elasticsearch 的
Scroll API: 专门用于导出大量数据,但不适合实时用户分页。
总结
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Skip/Limit (Offset) | 数据量小,管理后台 | 实现简单,可随意跳转 | 数据量大时极慢 (深分页问题) |
| 游标法 (Seek Method) | App 信息流,无限滚动 | 性能极高,稳定 | 无法直接跳转到特定页码 |
| 延迟关联 (Subquery) | 必须支持页码跳转的大数据列表 | 比普通 Offset 快很多 | SQL 写法稍复杂 |
| 限制深度 | 公共搜索,C 端列表 | 彻底避免性能风险 | 牺牲了一部分用户体验 |
面试建议回答逻辑:
- 先说最简单的
limit offset。 - 指出其在深分页时的性能瓶颈(全表扫描、回表 IO)。
- 提出解决方案:如果是 App 下拉加载,用
where id > last_id;如果是 Web 端需要页码,用子查询覆盖索引优化;如果数据量极大,考虑 ES 或限制最大页码。