 播面
播面 Redis数据类型详解
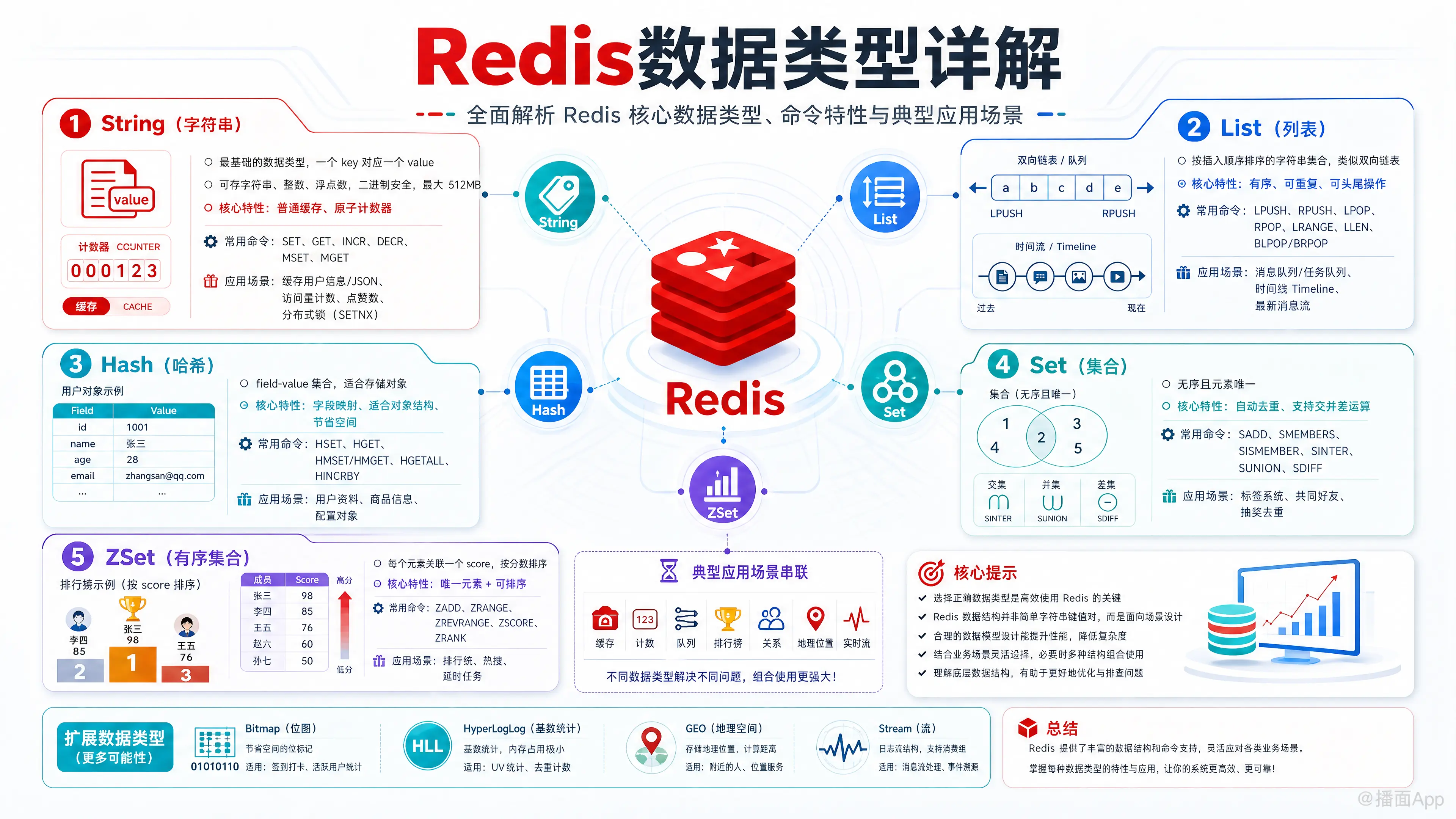
本文全面解析了Redis的核心数据类型(String, List, Hash, Set, ZSet等),详细阐述了它们的特性、命令和在缓存、消息队列、排行榜等场景下的具体应用,助你高效使用Redis。
Redis 官方提供了多种数据类型,它们不仅仅是简单的字符串键值对,而是专门为不同场景设计的高效数据结构。选择正确的数据类型是高效使用 Redis 的关键。
以下是 Redis 的核心数据类型:
1. String (字符串)
这是 Redis 最基础、最简单的数据类型。一个键(key)对应一个值(value)。
- 描述: Value 可以是字符串、整数或浮点数。Redis 会根据值的类型自动进行内部编码优化。它也是二进制安全的,意味着你可以存储任何数据,比如一张序列化后的图片或一个 Protobuf 对象。最大可以存储 512MB 的数据。
- 核心特性:
- 可以作为普通字符串缓存。
- 可以作为原子计数器(
INCR,DECR)。
- 常用命令:
SET key value: 设置键值。GET key: 获取键值。INCR key: 将 key 中储存的数字值增一(如果 key 不存在,则初始化为 0 再执行)。DECR key: 将 key 中储存的数字值减一。MSET key1 value1 key2 value2: 批量设置键值。MGET key1 key2: 批量获取键值。
- 应用场景:
- 缓存: 缓存用户信息、网页片段、JSON 对象等。
- 计数器: 网站访问量、文章点赞数、用户关注数。
- 分布式锁: 使用
SETNX(SET if Not eXists) 命令可以实现简单的分布式锁。
2. List (列表)
一个按照插入顺序排序的字符串元素集合。你可以把它想象成一个双向链表。
- 描述: 可以在列表的头部(左边)或尾部(右边)添加或移除元素。
- 核心特性:
- 有序: 元素按插入顺序排序。
- 可重复: 列表中的元素可以重复。
- 常用命令:
LPUSH key element1 [element2 ...]: 将一个或多个元素插入到列表头部。RPUSH key element1 [element2 ...]: 将一个或多个元素插入到列表尾部。LPOP key: 移除并获取列表的第一个元素。RPOP key: 移除并获取列表的最后一个元素。LRANGE key start stop: 获取列表指定范围内的元素。LLEN key: 获取列表的长度。BLPOP/BRPOP:LPOP/RPOP的阻塞版本,常用于消息队列。
- 应用场景:
- 消息队列/任务队列:
LPUSH生产消息,RPOP消费消息(或者反过来)。BRPOP可以实现阻塞式消费,避免了客户端轮询。 - 时间线 (Timeline): 微博、朋友圈等,最新的消息用
LPUSH插入,用LRANGE分页展示。 - 最新消息排行榜: 例如“最新发布的10篇文章”。
- 消息队列/任务队列:
3. Hash (哈希)
一个键值对(field-value)的集合,非常适合用来存储对象。
- 描述: 一个 key 对应一个包含多个字段(field)和值(value)的 map。
- 核心特性:
- 字段-值映射: 类似于编程语言中的
Map或Dictionary。 - 节省空间: 当字段数量较少时,内部采用
ziplist编码,非常节省内存。
- 字段-值映射: 类似于编程语言中的
- 常用命令:
HSET key field value: 将哈希表 key 中的字段 field 的值设为 value。HGET key field: 获取哈希表 key 中给定字段 field 的值。HMSET key field1 value1 [field2 value2 ...]: 同时将多个 field-value 对设置到哈希表中。HGETALL key: 获取在哈希表中指定 key 的所有字段和值。HINCRBY key field increment: 为哈希表 key 中的指定字段的整数值加上增量。
- 应用场景:
- 存储对象: 缓存用户信息(如用户ID、姓名、年龄、邮箱),每个用户ID作为一个 key,用户信息字段作为 field。这样可以只修改对象的某个属性,而无需读取和重写整个对象。
- 购物车: 以用户ID为 key,商品ID为 field,商品数量为 value。
4. Set (集合)
一个无序且元素唯一的字符串集合。
- 描述: 类似于数学中的集合,不允许有重复的元素。
- 核心特性:
- 无序: 元素没有特定的顺序。
- 唯一: 集合中的元素都是唯一的,重复添加无效。
- 常用命令:
SADD key member1 [member2 ...]: 向集合添加一个或多个成员。SREM key member1 [member2 ...]: 移除集合中一个或多个成员。SMEMBERS key: 返回集合中的所有成员。SISMEMBER key member: 判断 member 元素是否是集合 key 的成员。SINTER key1 [key2 ...]: 返回给定所有集合的交集。SUNION key1 [key2 ...]: 返回给定所有集合的并集。SDIFF key1 [key2 ...]: 返回给定所有集合的差集。
- 应用场景:
- 标签系统: 为一篇文章或一个用户打上多个标签。
- 共同好友/共同关注: 使用
SINTER可以轻松找出两个用户的共同好友。 - 抽奖系统: 将所有参与用户放入一个 Set,使用
SRANDMEMBER随机抽取中奖者。 - 点赞/收藏: 一个帖子的点赞用户列表,用 Set 可以保证一个用户只能点赞一次。
5. Sorted Set (ZSet / 有序集合)
和 Set 类似,但每个元素都会关联一个 double 类型的分数(score)。Redis 正是根据这个分数来为集合中的成员进行排序。
- 描述: 一个有序的、元素唯一的字符串集合。
- 核心特性:
- 唯一: 元素唯一,和 Set 一样。
- 有序: 每个元素都有一个分数,集合根据分数从小到大排序。
- 常用命令:
ZADD key score1 member1 [score2 member2 ...]: 向有序集合添加一个或多个成员,或者更新已存在成员的分数。ZREM key member1 [member2 ...]: 移除有序集合中的一个或多个成员。ZRANGE key start stop [WITHSCORES]: 按分数从小到大返回指定区间的成员。ZREVRANGE key start stop [WITHSCORES]: 按分数从大到小返回指定区间的成员。ZRANGEBYSCORE key min max: 按分数范围返回成员。ZSCORE key member: 返回有序集合中,成员的分数。
- 应用场景:
- 排行榜: 游戏积分榜、热门帖子榜、销售榜。分数(score)可以是积分、点赞数或销售额。
- 带权重的任务队列: 分数可以用作任务的优先级。
- 范围查找: 例如,查找工资在 5000 到 10000 之间的员工。
其他特殊数据类型
除了以上五种基本类型,Redis 还提供了一些面向特定场景的高级数据类型。
6. Bitmap (位图)
- 描述: 实际上是 String 类型的一种特殊用法,它允许你对字符串的位(bit)进行操作。
- 应用场景:
- 用户签到: 用一个 bit 表示用户某一天是否签到,一年365天只需要365个 bit。
- 用户在线状态: 记录海量用户的在线/离线状态。
- 布隆过滤器 (Bloom Filter) 的实现基础。
7. HyperLogLog (基数统计)
- 描述: 一种概率性数据结构,用于估算一个集合中不重复元素的数量(即基数)。
- 核心特性: 占用空间极小(固定 12KB),但估算结果有微小误差(标准误差约 0.81%)。
- 应用场景:
- 统计网站独立访客数 (UV): 统计每天访问网站的独立 IP 数量。
- 统计海量数据中的唯一元素个数。
8. Geospatial (GEO / 地理空间)
- 描述: 基于 Sorted Set 实现,专门用于存储地理位置信息(经度、纬度)。
- 核心特性: 可以计算两个位置之间的距离、查找指定半径范围内的元素等。
- 应用场景:
- 附近的人/物: 查找附近的餐厅、司机、酒店。
- 打卡功能: 记录用户地理位置。
9. Stream (流)
- 描述: Redis 5.0 引入的全新数据结构,是一个支持消费者组的、可持久化的、追加式的日志结构(Append-only Log)。
- 核心特性: 类似于 Kafka,但更轻量。支持消息的持久化、多播、消费确认(ACK)、阻塞读取等。
- 应用场景:
- 消息队列: 比 List 实现的消息队列功能更完善、更专业。
- 事件溯源 (Event Sourcing)。
- 实时数据流处理。
总结表格
| 数据类型 | 内部实现 (简述) | 特点 | 典型应用场景 |
|---|---|---|---|
| String | SDS (动态字符串) | 键值对,可存字符串、数字、二进制数据,支持原子增减 | 缓存、计数器、分布式锁 |
| List | Quicklist (ziplist链表) | 有序、可重复 | 消息队列、时间线、最新列表 |
| Hash | Ziplist / Hashtable | 无序键值对集合 (field-value) | 存储对象(如用户信息)、购物车 |
| Set | Intset / Hashtable | 无序、唯一 | 标签、共同好友、抽奖、点赞 |
| Sorted Set | Ziplist / Skiplist + Hashtable | 有序(按score)、唯一 | 排行榜、带权重的任务 |
| Bitmap | String (位操作) | 极省空间,操作位 | 用户签到、在线状态 |
| HyperLogLog | String (概率算法) | 极省空间,估算基数,有误差 | 统计独立访客数 (UV) |
| Geospatial | Sorted Set (Geohash) | 存储经纬度,范围查询 | 附近的人、位置服务 |
| Stream | Radix Tree (基数树) | Append-only日志、支持消费者组 | 专业消息队列、事件流 |