 播面
播面 Redis与Memcached全面对比分析
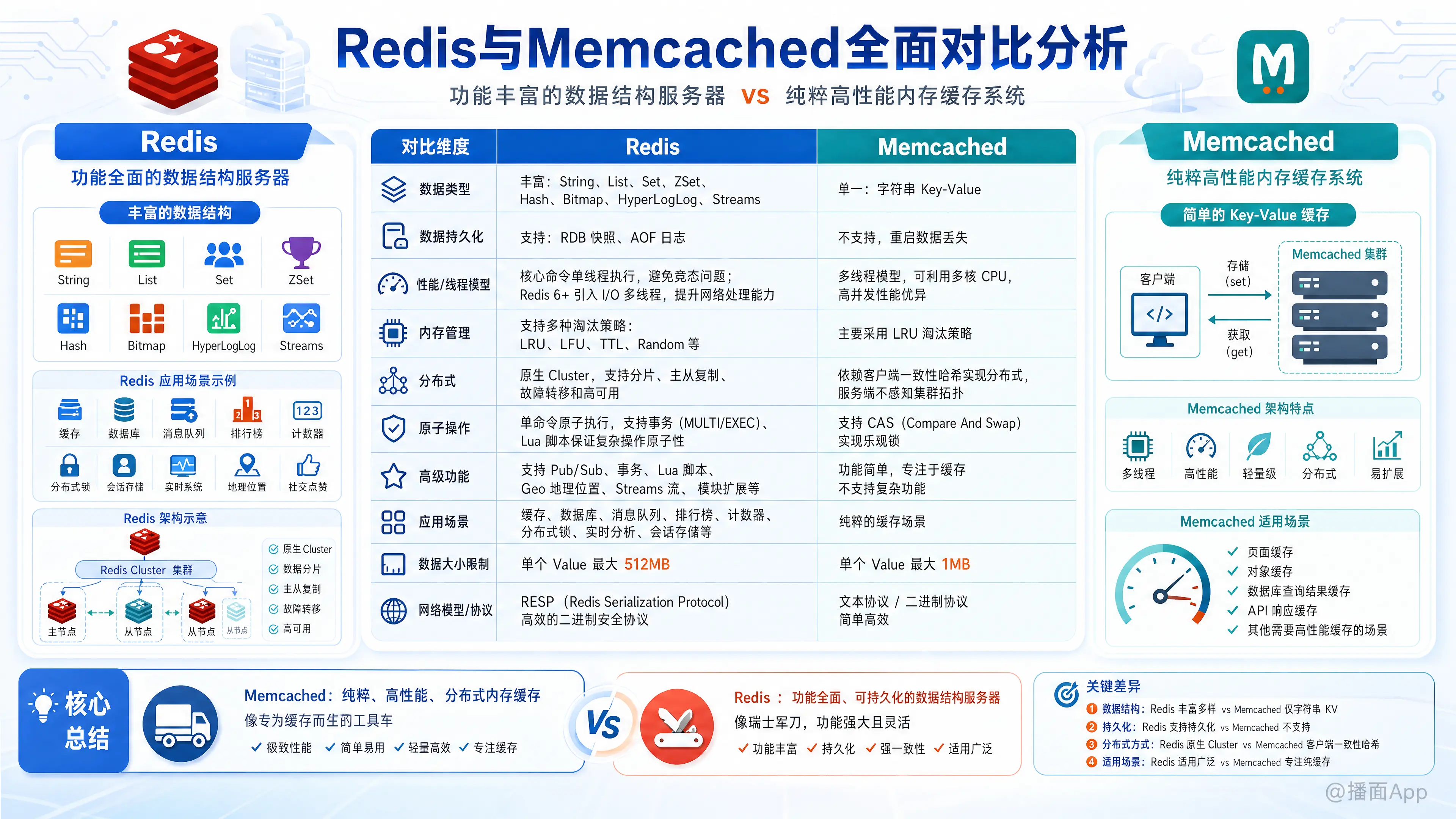
本文对比了Redis和Memcached。Redis是功能丰富、可持久化的数据结构服务器;Memcached是纯粹的高性能内存缓存。文章从多维度剖析了二者的核心区别与适用场景,帮助您做出技术选型。
这是一个非常经典的技术面试和选型问题。Redis 和 Memcached 都是高性能的、基于内存的键值存储系统,但它们在设计理念、功能和适用场景上有显著的区别。
下面我将从多个维度对它们进行详细的对比。
一、核心总结(一句话概括)
- Memcached:一个纯粹的、高性能的、分布式的内存缓存(Cache)系统。它像一个专为缓存而生的“工具车”,速度快,功能单一。
- Redis:一个功能丰富的内存数据结构服务器(In-Memory Data Structure Server)。它不仅能做缓存,还能作为数据库、消息队列等。它像一把“瑞士军刀”,功能全面且强大。
二、详细对比表格
| 特性 / 维度 | Redis | Memcached |
|---|---|---|
| 数据类型 | 丰富:String、List、Set、Sorted Set、Hash、Bitmaps、HyperLogLogs、Streams 等 | 单一:仅支持简单的 Key-Value 存储(字符串) |
| 数据持久化 | 支持:提供 RDB(快照)和 AOF(日志追加)两种持久化方式,数据可恢复 | 不支持:数据完全存储在内存中,服务重启或宕机后数据全部丢失 |
| 性能/线程模型 | 单线程(核心命令处理),避免了锁竞争和上下文切换的开销。Redis 6.0 后引入了多线程处理 I/O,但命令执行仍是单线程,保证原子性。 | 多线程,可以利用多核 CPU 处理并发请求,在简单的读写场景下性能可能更高。 |
| 内存管理 | 更精细:提供多种内存淘汰策略(如 LRU, LFU, volatile-ttl, random 等) | 简单:使用 LRU(Least Recently Used,最近最少使用)算法进行内存淘汰。 |
| 分布式 | 原生支持:自 3.0 版本后提供 Redis Cluster 方案,服务端自动进行数据分片、主从复制和故障转移。 | 原生不支持:分布式能力需要由客户端实现,通过一致性哈希等算法将 Key 分布到不同的 Memcached 服务器上。 |
| 原子操作 | 支持:所有单个命令都是原子性的,还支持 MULTI/EXEC 事务和 Lua 脚本来执行多个命令的原子操作。 |
部分支持:仅支持 CAS(Check-and-Set)这样的原子操作,用于处理并发更新。 |
| 高级功能 | 非常丰富:发布/订阅(Pub/Sub)、事务、Lua 脚本、地理空间(Geospatial)、Streams(流)等。 | 基本没有:功能非常简单,专注于缓存。 |
| 应用场景 | 缓存、数据库、消息队列、排行榜、计数器、分布式锁、社交网络、实时系统等。 | 纯粹的缓存,如缓存数据库查询结果、页面、API 调用结果等。 |
| 数据大小限制 | Value 最大可达 512MB | Value 最大 1MB |
| 网络模型 | 自定义协议(RESP) | 文本协议或二进制协议 |
三、关键差异详解
1. 数据结构:这是最核心的区别
- Memcached 只能存储字符串。如果你想存储一个结构化的对象(比如一个用户信息),你需要先将其序列化(如转为 JSON 字符串)再存入,取出时再反序列化。这增加了应用层的复杂性和开销。
- Redis 提供了丰富的数据结构,这让它能应对更复杂的场景,并且效率更高。
- Hash: 天然适合存储对象,无需序列化,可以单独更新对象的某个字段。
- List: 可以实现队列或栈,用作简单的消息队列。
- Set/Sorted Set: 可以用于去重、实现排行榜、标签系统等。
- 这些操作都是在服务端原子性完成的,比在客户端获取整个数据、修改后再存回去的方式高效得多。
2. 持久化能力:决定了它们能否作为数据库
- Memcached 是易失性的(Volatile)。它被设计为纯缓存,不关心数据的丢失。如果服务挂了,缓存数据就没了,应用需要能从后端数据源(如 MySQL)重新加载数据。
- Redis 支持持久化。这意味着即使 Redis 服务器重启,数据也能从磁盘恢复。这使得 Redis 不仅可以做缓存,还可以在某些场景下作为轻量级的数据库使用。
3. 性能和线程模型
- 很多人认为“多线程一定比单线程快”,但在 Redis 的场景下不完全正确。
- Memcached 的多线程模型在多核服务器上,处理大量简单的 Get/Set 请求时,理论上吞吐量会更高。
- Redis 的单线程模型(指处理命令的线程)避免了线程切换和锁的开销,使得每个命令的执行都非常高效且原子。对于内存操作来说,CPU 通常不是瓶颈,瓶颈在于网络 I/O。Redis 6.0 之后引入的多线程主要用于处理网络 I/O,进一步提升了吞吐量,但其核心命令执行依然是单线程,这保留了其简单和原子性的优点。
4. 分布式集群
- Memcached 的集群是“无中心”的,服务器之间互不通信。数据的分布完全由客户端库来决定。这种方式简单、易于扩展,但当某个节点失效时,需要客户端处理(或者依赖像
memcached-repcached这样的补丁)。 - Redis Cluster 是一个“有中心”的集群方案(虽然是去中心化的架构),服务器节点之间会相互通信,维护整个集群的状态。它可以自动进行数据分片、主从选举和故障转移,对客户端更透明,运维更方便。
四、如何选择?(应用场景)
选择 Memcached 的场景:
- 纯缓存需求:只需要一个简单、快速的 Key-Value 缓存,用于存储数据库查询结果、渲染后的页面片段等。
- 数据量小且为字符串:缓存的数据都是简单的字符串,并且每个值的大小不超过 1MB。
- 对数据丢失不敏感:能够接受缓存服务器宕机后所有数据丢失,并有机制从后端数据库重新加载。
- 追求极致的简单读写性能:在多核环境下,如果你的应用主要是海量的简单 Get/Set 操作,Memcached 的多线程模型可能会带来一些优势。
选择 Redis 的场景:
- 需要复杂数据结构:需要实现排行榜、计数器、好友列表、消息队列等功能。
- 需要数据持久化:希望缓存数据在服务重启后能快速恢复,或者把它当作一个轻量级的数据库来使用。
- 需要原子操作:比如需要对一个计数器进行原子性的增减操作 (
INCR,DECR)。 - 需要高级功能:需要使用发布/订阅、事务、Lua 脚本等高级特性来构建更复杂的应用。
- 构建分布式系统组件:利用 Redis 实现分布式锁、Session 共享等。
总结
总的来说,如果你只需要一个简单、高性能的缓存,且能够接受其功能的局限性,Memcached 是一个轻量、不错的选择。
但在当今的互联网应用中,Redis 凭借其丰富的数据结构、持久化能力和强大的生态系统,已经成为了事实上的标准。它不仅能完美地胜任缓存工作,还能帮你轻松解决更多复杂的问题。因此,在没有特殊理由的情况下,优先选择 Redis 通常是更稳妥和富有远见的选择。