 播面
播面 如何生成全局唯一的 ID?(雪花算法、数据库号段模式等)
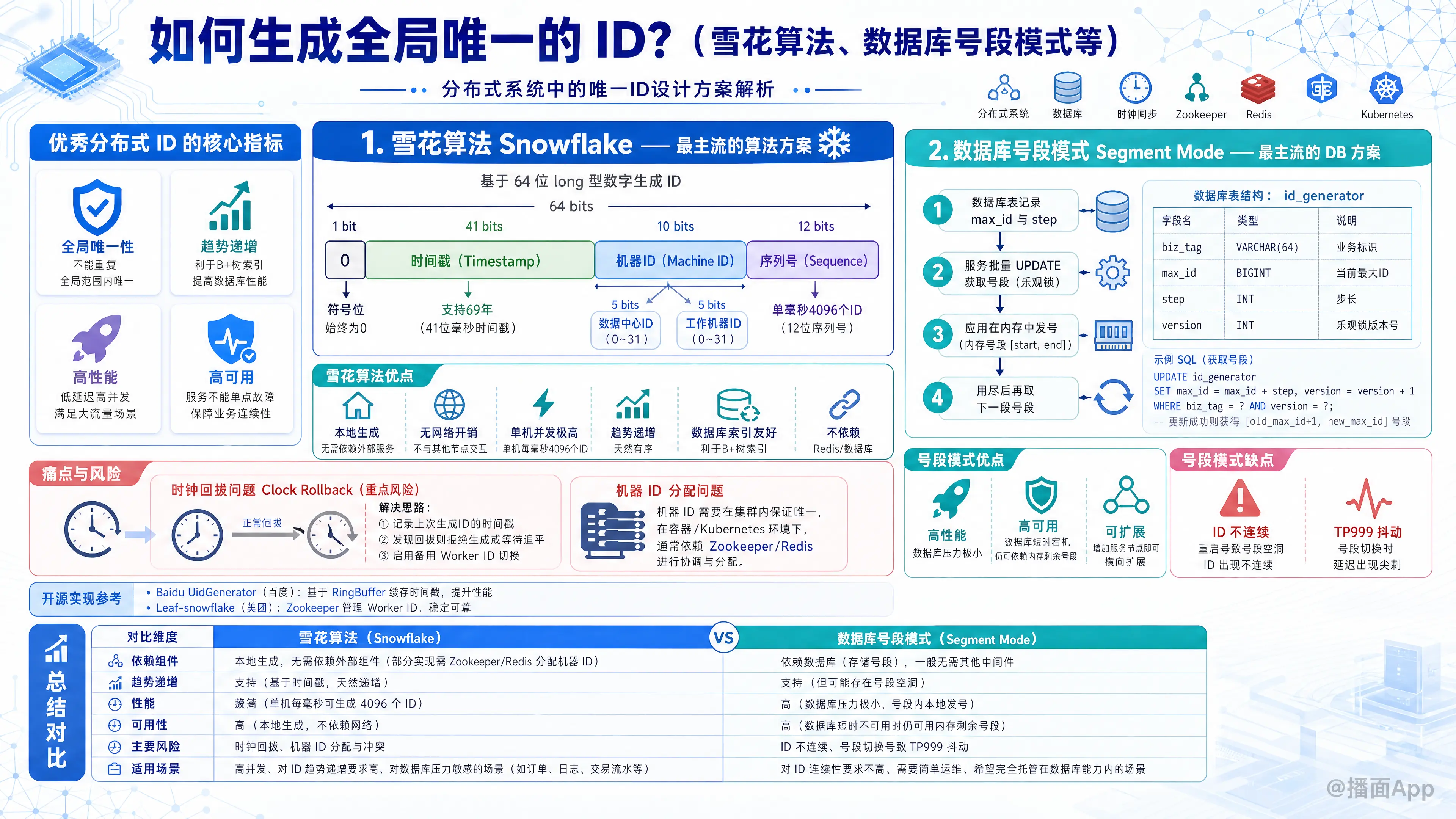
生成全局唯一 ID(Distributed ID)是分布式系统中非常常见且关键的需求。一个优秀的分布式 ID 通常需要满足以下核心指标:
- 全局唯一性:不能出现重复。
- 趋势递增:通常用于数据库主键,利于 B+ 树索引性能(避免页分裂)。
- 高性能:生成 ID 的延迟要低,并发要高。
- 高可用:ID 生成服务不能挂,否则整个业务瘫痪。
以下是目前业界主流的几种方案及其优缺点深度解析:
1. 雪花算法 (Snowflake) —— 最主流的算法方案
Twitter 开源的算法,核心思想是利用 64位 long 型 的数字来存储 ID。
结构组成 (64 bit)
- 1 bit:不使用(符号位,始终为0)。
- 41 bits:毫秒级时间戳(可以使用 69 年)。
- 10 bits:机器 ID(5位数据中心 ID + 5位工作机器 ID),支持 1024 个节点。
- 12 bits:毫秒内的序列号,支持同一毫秒内生成 4096 个 ID。
优点
- 高性能:本地生成,无网络消耗,单机并发极高(理论上每秒几百万)。
- 趋势递增:基于时间戳,保证了 ID 是随时间递增的,对数据库索引友好。
- 不依赖第三方组件:不需要依赖 Redis 或数据库。
缺点 & 痛点
- 时钟回拨问题 (Clock Rollback):这是雪花算法最大的坑。如果服务器时间被回调(比如 NTP 校准),可能会导致 ID 重复。
- 解决方案:记录上一次生成的时间戳,如果发现当前时间小于上一次时间,则拒绝生成(抛异常)或等待时间追平;或者启用备用 Worker ID。
- 机器 ID 分配:在分布式容器环境(如 Kubernetes)中,如何动态分配唯一的 Worker ID 是个工程问题(通常依赖 Zookeeper/Redis 协调)。
开源实现参考
- Baidu UidGenerator:解决了时钟回拨问题,使用 RingBuffer 缓存。
- 美团 Leaf-snowflake:依赖 Zookeeper 管理 Worker ID。
2. 数据库号段模式 (Segment Mode) —— 最主流的 DB 方案
这是对传统数据库 auto_increment 的优化版。不再每次获取 ID 都请求数据库,而是批量获取。
原理
- 数据库中有一张表,记录当前的
max_id和step(步长,例如 1000)。 - 应用服务启动或 ID 用尽时,去数据库执行
UPDATE,把max_id更新为max_id + step。 - 应用服务拿到这 1000 个 ID 的范围(例如 1000~2000),在内存中慢慢发号。
- 用完后,再次请求数据库获取下一个号段。
数据库表设计示例
sql
CREATE TABLE `id_generator` (
`biz_tag` varchar(128) NOT NULL, -- 业务标识,如 order, user
`max_id` bigint(20) NOT NULL, -- 当前最大 ID
`step` int(11) NOT NULL, -- 步长
`version` int(20) NOT NULL, -- 乐观锁版本号
PRIMARY KEY (`biz_tag`)
);优点
- 高性能:数据库压力极小(一次请求管很久)。
- 高可用:即使数据库短时间宕机,内存中剩余的号段还能撑一阵子。
- 可扩展:扩容方便,增加发号服务节点即可。
缺点
- ID 不连续:如果服务重启,内存中未发完的 ID 会丢失,导致 ID 空洞(通常业务可接受)。
- TP999 抖动:当号段用完去 DB 取新号段时,会有一次网络 IO,可能导致该次请求耗时变长。
优化:双 Buffer 机制 (美团 Leaf 核心优化)
为了解决“TP999 抖动”问题,在当前号段用到 10%~50% 时,异步线程提前去数据库把下一个号段取回来放入备用 Buffer。这样主线程切换号段时完全基于内存,无感知。
3. Redis 生成方案
利用 Redis 的原子操作 INCR 或 INCRBY。
原理
bash
INCR order_id_seq优点
- 性能优于数据库:Redis 基于内存,吞吐量高。
- 有序递增:严格递增,没有空洞。
缺点
- 运维成本:需要维护 Redis 集群的高可用。
- 持久化风险:
- RDB 模式:Redis 宕机可能会回滚数据,导致 ID 重复。
- AOF 模式:性能有损耗,且重启恢复慢。
- 网络瓶颈:每次生成都需要网络请求(可以通过类似号段模式的
INCRBY批量获取来优化)。
4. UUID (Universally Unique Identifier)
原理
基于时间、网卡 MAC 地址、随机数等生成的 128 位字符串。
优点
- 最简单:代码一行搞定,完全本地生成,无任何依赖。
- 全球唯一。
缺点 (极度不推荐作为 MySQL 主键)
- 无序:UUID 是无序字符串,导致 B+ 树索引频繁发生页分裂 (Page Split),写入性能极差。
- 太长:128 位(通常存为 36 字符的 String),占用空间大,且导致二级索引变大,降低内存缓存命中率。
- 可读性差:无法携带业务含义。
总结与选型建议
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| UUID | 简单、无依赖 | 无序、太长、性能差 | 生成 Token、文件名、链路追踪 ID(勿用于 DB 主键) |
| 数据库号段模式 | 高可用、高性能、趋势递增 | ID 不连续、依赖 DB | 绝大多数互联网业务的主键生成(推荐) |
| 雪花算法 | 极高性能、不依赖 DB | 强依赖时钟、时钟回拨问题 | 超高并发、对 ID 吞吐量要求极高的场景 |
| Redis | 实现简单、严格递增 | 引入中间件复杂度、持久化风险 | 需要严格连续递增的场景(如发票号) |
工业界推荐做法:
- 如果不想引入复杂架构,且并发量适中:使用 数据库号段模式(手写一个简单的或使用美团 Leaf-segment)。
- 如果并发极高,或者不希望依赖数据库:使用 雪花算法(推荐使用百度 UidGenerator 或美团 Leaf-snowflake 这种优化过的版本,不要直接用原始算法,以免踩时钟回拨的坑)。