 播面
播面 用户输入前缀,如何快速提示搜索关键词(Trie 树/Elasticsearch)?
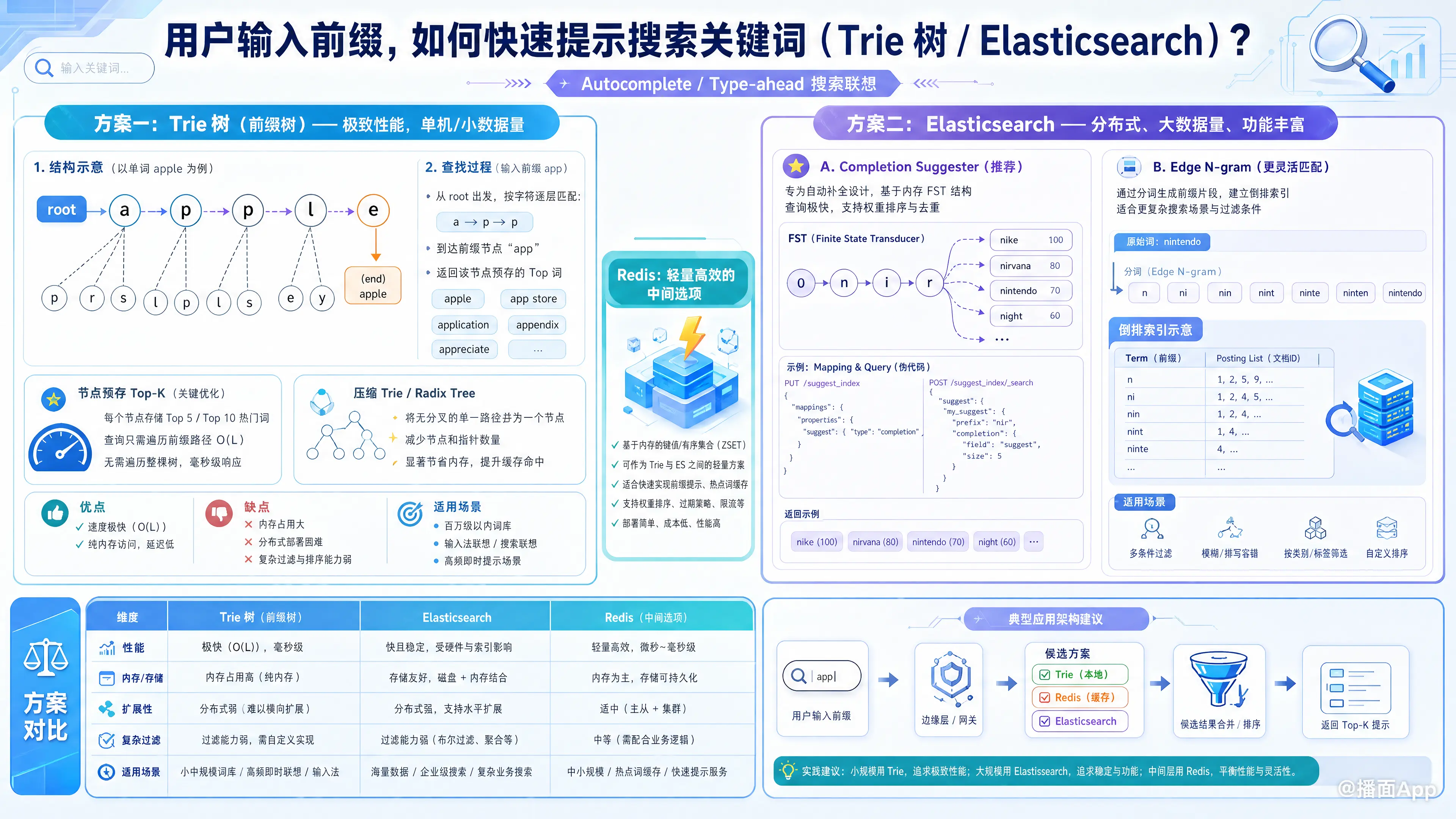
实现“用户输入前缀,快速提示搜索关键词”(通常称为 Autocomplete 或 Type-ahead)是搜索系统的核心功能之一。
针对你的问题,Trie 树和 Elasticsearch 是两种最主流的技术路线,分别适用于不同的场景。此外,Redis 也是一个非常轻量且高效的中间选项。
以下是详细的方案对比与实现逻辑:
方案一:Trie 树 (前缀树) —— 极致性能,单机/小数据量
Trie 树是一种专门处理字符串匹配的数据结构,利用字符串的公共前缀来减少查询时间。
1. 原理
- 结构:根节点为空,每个节点代表一个字符。从根节点到某一节点的路径即为该节点对应的字符串。
- 查找:输入前缀
app,直接沿着a->p->p往下走,到达节点后,遍历该节点下的所有子树即可找到所有以app开头的词(如apple,app store)。
2. 优化策略(关键)
朴素的 Trie 树在查找“热门词”时效率不够高(需要遍历子树)。为了做到毫秒级响应,必须进行以下优化:
- 节点预存 Top-K:
在构建树或更新热度时,每个节点直接存储经过该节点且热度最高的 Top 5 或 Top 10 个词。- 效果:当用户输入
app到达p节点时,不需要遍历子树,直接返回该节点挂载的 Top 10 列表。时间复杂度为 (L为前缀长度),与词库大小无关。
- 效果:当用户输入
- 压缩 Trie (Radix Tree):如果路径上没有分叉(如
app后面只有le),可以合并节点以节省内存。
3. 适用场景
- 优点:速度极快(微秒级),纯内存操作。
- 缺点:
- 内存占用大(Java 对象头开销大,建议用 C++ 或专门的紧凑结构)。
- 分布式困难(通常需要每台机器加载全量 Trie,或者按首字母 Sharding)。
- 不支持复杂的过滤(如“只搜类目A下的词”)。
- 场景:词库规模在百万级以内,对延迟要求极高(如输入法联想、高频即时搜索)。
方案二:Elasticsearch (ES) —— 分布式、大数据量、功能丰富
ES 是工业界最通用的方案,它提供了两种主要实现方式:Completion Suggester 和 Edge N-gram。
1. Completion Suggester (推荐)
这是 ES 专门为自动补全设计的组件。
- 原理:ES 在内存中构建一个 FST (Finite State Transducer)。FST 类似于 Trie 树,但更节省空间且支持输出(权重)。
- 实现:json
// Mapping 定义 { "mappings": { "properties": { "suggest": { "type": "completion" // 关键类型 }, "title": { "type": "keyword" } } } } // 查询 { "suggest": { "song-suggest": { "prefix": "nir", // 用户输入 "completion": { "field": "suggest", "size": 5 // 返回数量 } } } } - 特点:查询极快,支持权重(Weight)排序,支持去重。
2. Edge N-gram (基于倒排索引)
如果你需要支持中间匹配(如输入 "phone" 提示 "iPhone"),或者需要复杂的过滤条件。
- 原理:在索引阶段,将 "apple" 切分为
a,ap,app,appl,apple存入倒排索引。 - 特点:灵活性高,但索引体积会膨胀,查询速度略慢于 Completion Suggester。
3. 适用场景
- 优点:
- 分布式,可横向扩展支持海量数据(亿级)。
- 支持复杂的上下文过滤(Context Suggester),例如:在“电子产品”分类下搜“a”。
- 支持模糊匹配(Fuzzy)。
- 缺点:
- Completion Suggester 极其消耗堆内存(Heap Memory),因为 FST 常驻内存。
- 数据更新后,FST 重建有一定成本(虽然 ES 优化了,但不如倒排索引实时性好)。
- 场景:电商搜索、全站搜索、数据量大且需要复杂排序逻辑。
方案三:Redis (ZSet / ZRangeByLex) —— 轻量级折中方案
如果不想引入 ES 那么重,又不想自己写 Trie 树代码,Redis 是绝佳选择。
实现逻辑
利用 Redis 的 Sorted Set (ZSet) 的字典序特性。
- 存储:将所有关键词作为 Member 存入 ZSet,Score 均设为 0(或者利用 Score 做热度排序,但利用字典序查找需要特定技巧)。
- 查询:使用
ZRANGEBYLEX命令。- 假设用户输入
app。 - 命令:
ZRANGEBYLEX my_keywords [app [app\xff LIMIT 0 10 - 原理:查找 ASCII 码在
app和app+\xff(不可见字符,代表最大字节)之间的元素。
- 假设用户输入
适用场景:中等规模数据,已有 Redis 设施,开发成本最低。
总结与选型建议
| 特性 | Trie 树 (自研/库) | Elasticsearch (Completion) | Redis (ZRangeByLex) |
|---|---|---|---|
| 响应速度 | 🚀 极快 (微秒级) | ⚡ 快 (毫秒级) | ⚡ 快 (毫秒级 + 网络开销) |
| 数据规模 | 小/中 (受限于单机内存) | 大 (分布式扩展) | 中 (受限于 Redis 内存) |
| 功能复杂度 | 低 (仅前缀匹配) | 高 (支持拼音、纠错、过滤) | 低 (仅前缀匹配) |
| 开发维护成本 | 高 (需处理并发、内存) | 中 (配置即可) | 低 (现成命令) |
| 内存消耗 | 高 (节点对象开销) | 极高 (FST 堆内存) | 中 |
最佳实践架构
对于高并发的大型互联网应用,通常采用 多级缓存 + 混合架构:
- 前端/客户端缓存:用户输入过的词,浏览器/App 本地缓存,下次输入直接展示。
- 服务端 Trie 缓存:对于极其热门的 Top 1000 前缀(如 "a", "b", "ip"),直接在应用服务器内存中构建小的 Trie 树或 HashMap,挡掉 80% 的高频流量。
- 后端 Elasticsearch:对于长尾词、冷门词或需要复杂过滤的请求,穿透到 ES 集群查询。
- 异步更新:用户的点击行为通过日志收集,异步计算热度,定期(如每小时)更新 Trie 树和 ES 中的权重。
一句话建议:
如果是起步阶段或通用搜索,直接用 Elasticsearch 的 Completion Suggester;如果是追求极致性能的输入法或高频词提示,使用 带有 Top-K 缓存的 Trie 树。