 播面
播面 系统中有大量红点未读消息,如何高效存储和统计?
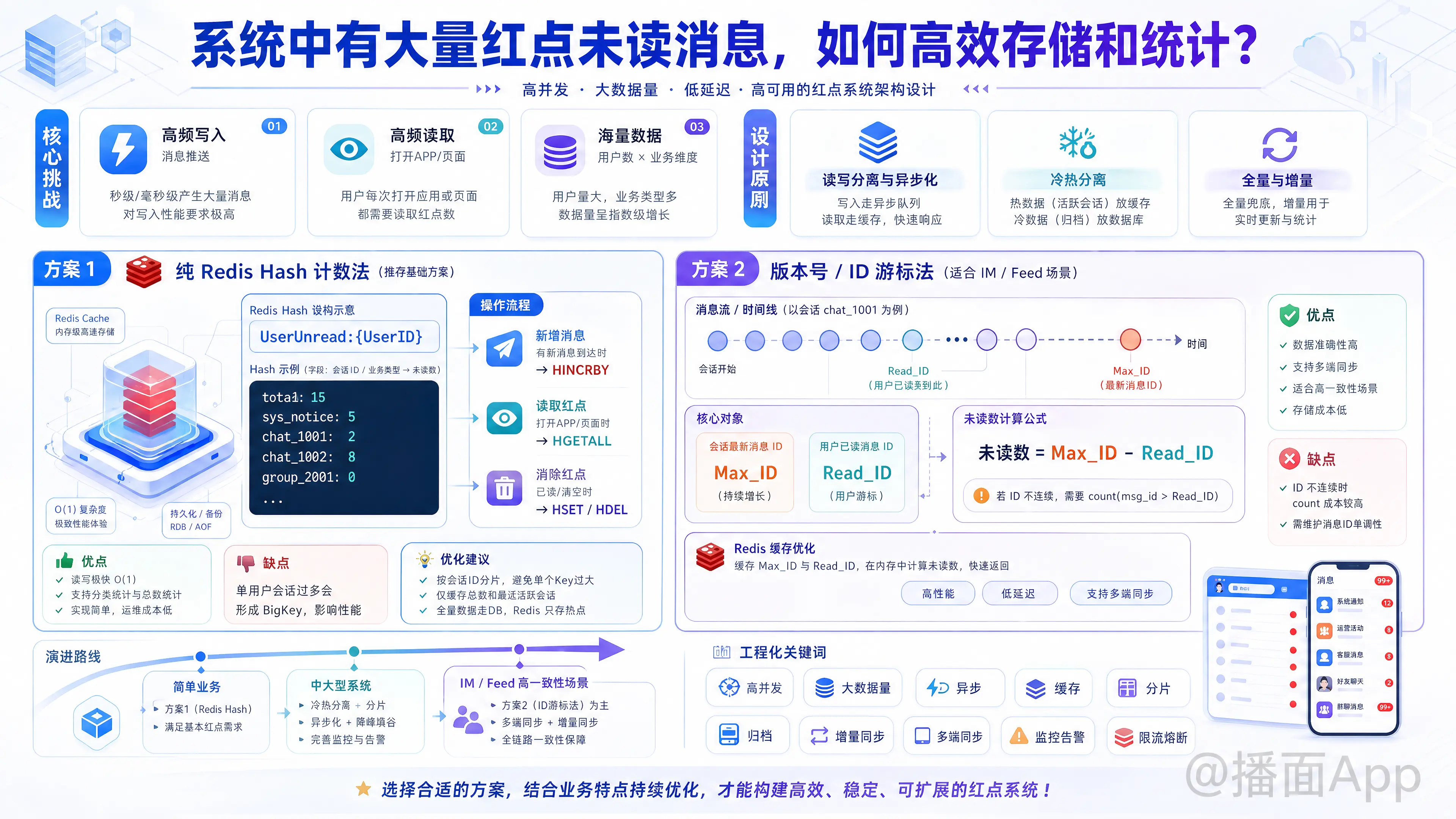
处理系统中海量红点(未读消息)的存储与统计,是一个典型的高并发、大数据量的业务场景。其核心挑战在于:写入频繁(消息推送)、读取极高频(每次打开APP/页面都要查)、数据量大(用户数 业务维度)。
以下是针对不同业务场景和量级的高效存储与统计方案,按从简单到复杂的演进路线进行分析:
一、 核心设计原则
- 读写分离与异步化:红点产生(写)通常由消息触发,统计(读)由用户行为触发。
- 冷热分离:活跃用户的红点数据在缓存(Redis),不活跃用户下沉到数据库或归档。
- 全量与增量:客户端本地缓存未读数,服务端只推增量变化或仅在初始化时拉取全量。
二、 方案选型与数据结构
方案 1:纯 Redis Hash 计数法(适用于大多数中大型系统)
这是最通用且性能最好的方案。利用 Redis 的 Hash 结构,以用户 ID 为 Key,业务类型(或会话 ID)为 Field,未读数为 Value。
Redis Key 设计:
UserUnread:{UserID}Hash 结构:
json{ "total": 15, // 总未读数(可选,为了快速读取) "sys_notice": 5, // 系统通知未读数 "chat_1001": 2, // 与用户1001的聊天未读数 "chat_1002": 8 // 与用户1002的聊天未读数 }操作流程:
- 新增消息:
HINCRBY UserUnread:123 chat_1001 1,同时更新total。 - 读取红点:
HGETALL UserUnread:123(获取该用户所有维度的红点)。 - 消除红点:
HSET UserUnread:123 chat_1001 0(或直接HDEL),同时扣减total。
- 新增消息:
优点:
- 读写极快(O(1))。
- 天然支持分类统计和总数统计。
缺点:
- 如果单个用户关联的会话极多(如大V有几万个私信会话),Hash 会变成 BigKey,导致阻塞。
- 优化:对于由成千上万个会话组成的红点,不要全放一个 Hash,需按会话 ID 进行 Hash Tag 分片,或者仅在 Redis 存“总数”和“最近活跃会话”,全量数据走 DB。
方案 2:版本号/ID 游标法(适用于 IM 聊天、Feed 流)
对于有序的消息流(如微信聊天、微博关注流),单纯存“数字”容易导致数据不一致(如消息被撤回、多端同步问题)。此时应存储“读取位置”。
存储模型:
- 会话最新消息 ID (
Max_ID):存储在全局会话表。 - 用户已读消息 ID (
Read_ID):存储在User_Session_Relation表。
- 会话最新消息 ID (
计算逻辑:
未读数 = Max_ID - Read_ID(如果是连续自增 ID)。- 如果 ID 不连续(如雪花算法),则需要查询:
SELECT count(*) FROM msg_table WHERE session_id = x AND msg_id > Read_ID。
优化(Redis 缓存):
- 在 Redis 中缓存每个会话的
Max_ID和用户的Read_ID。 - 计算未读数时,直接在内存中做减法(前提是 ID 必须是严格连续自增的序列号
Sequence ID,而非 UUID)。
- 在 Redis 中缓存每个会话的
优点:数据准确性高,支持多端同步(已读位置同步)。
缺点:如果 ID 不连续,Count 操作成本高。
方案 3:Redis Bitmap / Bloom Filter(适用于极大规模、仅展示“有/无”红点)
如果系统只需要展示“有没有红点”(一个小圆点),不需要展示具体数字(如“99+”),或者用户量级达到亿级,为了节省内存:
Bitmap:
- Key:
UnreadStatus:{BizType} - Offset:
UserID - Value: 1 (有未读), 0 (无未读)
- 场景:判断全站 1 亿用户谁有“系统通知”未读。占用空间极小(1 亿用户仅需 ~12MB)。
- Key:
Bloom Filter:
- 用于快速判断“该用户是否可能有未读消息”。如果布隆过滤器说没有,那就一定没有,直接不查库。
三、 应对“海量”的架构优化
当数据量达到千万、亿级,单纯靠 Redis 可能会遇到内存瓶颈或重启恢复慢的问题。
1. 多级缓存策略
- L1 进程内缓存(Local Cache):对于极热点数据(如全站公告红点),在应用服务器本地缓存,减少 Redis 访问。
- L2 Redis 缓存:存储活跃用户的红点计数。
- L3 持久化存储(MySQL/HBase/Cassandra):
- Redis 只是 Cache,不是 Source of Truth。
- 所有红点变化必须异步写入 DB。
- Redis 内存淘汰策略设为 LRU,不活跃用户的红点数据被踢出,再次访问时从 DB 加载回 Redis。
2. 聚合与削峰(Merge Requests)
- 场景:用户瞬间收到 10 条消息。
- 策略:不要对 Redis 发起 10 次
INCR操作。在 Service 层或消息队列消费端进行聚合,合并为一次INCRBY 10操作,减少网络 IO。
3. 只有“正数”才存储
- 策略:如果未读数为 0,直接从 Redis 中删除该 Key 或 Field,不要存
key: 0。这能节省大量内存,因为绝大多数历史会话的未读数都是 0。
4. “99+” 截断策略
- 策略:在存储或返回给前端时,如果数值超过 99(或 999),就不再精确计数。
- 意义:对于用户来说,1000 条未读和 100 条未读带来的焦虑感是一样的。后端可以设置上限,当计数器到达阈值后,停止
INCR操作,直到用户执行“清除/已读”操作。
四、 典型业务场景的综合方案
场景 A:系统通知/公告(1 对 N)
- 特点:一条消息发给所有用户。
- 方案:不存每个用户的未读数。
- 存储全局最新公告 ID (
Global_Last_ID)。 - 用户表存储该用户最后读取的公告 ID (
User_Last_Read_ID)。 - 用户请求时,比较
Global_Last_ID > User_Last_Read_ID即为有红点。
- 存储全局最新公告 ID (
场景 B:IM 聊天 / 私信(1 对 1 或 小群)
- 方案:Redis Hash + Sequence ID。
- Redis 存
User:{uid}:Unread->{"session_A": 5, "session_B": 1}。 - 每次发消息,Redis 原子累加。
- 客户端拉取列表时,直接返回 Redis 数据。
- 为了保证数据一致性,定期(如每晚或用户登录时)用 DB 中的
Count(Msg > LastReadTime)矫正 Redis。
- Redis 存
场景 C:Feed 流更新提醒(如朋友圈新动态)
- 方案:时间戳/推拉结合。
- 通常只提示“有新动态”,不提示具体数字。
- Redis 存一个
HasNewContent:UserID= 1。 - 用户点击后置为 0。
五、 总结建议
- 数据结构:首选 Redis Hash,Key 为用户,Field 为业务类型。
- 内存优化:只存 >0 的数据;冷热分离,不活跃用户数据落库。
- 高并发写:使用 MQ 异步写入,合并更新请求。
- 一致性:Redis 作为读视图,DB 作为兜底,客户端做最终展示逻辑(如 99+)。
代码逻辑伪代码示例:
python
# 1. 收到新消息 (Producer)
def on_new_message(user_id, session_id):
# 异步推送到 Redis
redis.hincrby(f"unread:{user_id}", session_id, 1)
redis.hincrby(f"unread:{user_id}", "total", 1)
# 异步持久化到 DB (可选,或定时刷盘)
kafka.send("update_unread_db", {user_id, session_id, count: +1})
# 2. 用户获取红点 (Consumer)
def get_unread_counts(user_id):
# 尝试从 Redis 读
data = redis.hgetall(f"unread:{user_id}")
if not data:
# 缓存击穿/冷数据,从 DB 加载并重建缓存
data = load_from_db_and_cache(user_id)
# 格式化返回,处理 99+
return format_counts(data)
# 3. 用户点击会话 (Clear)
def clear_unread(user_id, session_id):
# 获取当前该会话未读数
count = redis.hget(f"unread:{user_id}", session_id)
if count > 0:
redis.hdel(f"unread:{user_id}", session_id)
redis.hincrby(f"unread:{user_id}", "total", -count)
# 同步更新 DB 已读时间/ID
db.update_last_read(user_id, session_id, now())