 播面
播面 如何基于 GeoHash 实现“查找附近 5 公里的人”?
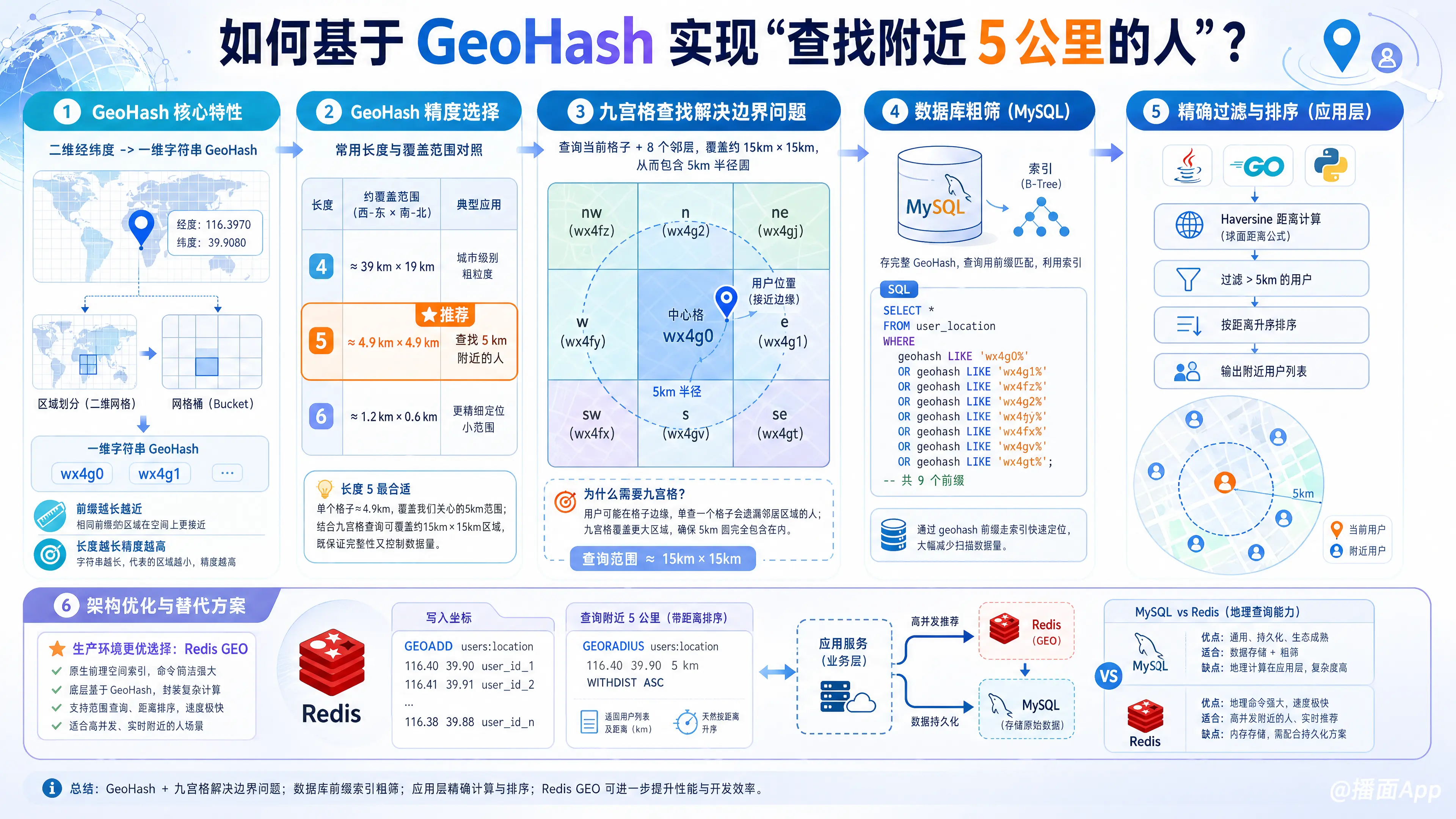
基于 GeoHash 实现“查找附近 5 公里的人”是一个非常经典的地理位置服务(LBS)面试题和实战场景。
核心思路可以概括为:将二维的经纬度映射为一维的字符串(GeoHash),利用字符串的前缀匹配特性快速筛选出大致范围内的用户,最后通过精确计算距离进行过滤。
以下是详细的实现步骤和逻辑:
1. 理解 GeoHash 的核心特性
- 区域划分:GeoHash 将地球划分为一个个矩形(Bucket)。
- 前缀特性:两个 GeoHash 字符串的公共前缀越长,代表这两个点在地理位置上越接近。
- 精度与长度:字符串越长,表示的矩形区域越小(精度越高)。
2. 确定 GeoHash 的精度(长度)
首先,我们需要选择一个合适的 GeoHash 长度,使其覆盖的区域大小略大于或接近 5 公里。
根据 GeoHash 的精度对照表(近似值,随纬度变化):
- 长度 4:约 39km × 19km
- 长度 5:约 4.9km × 4.9km
- 长度 6:约 1.2km × 0.6km
结论:选择 长度 5 是最合适的。虽然单个长度为 5 的格子(约 5km 宽)可能无法完全覆盖以用户为圆心的 5km 半径,但我们可以通过查询“周围的格子”来解决这个问题。
3. 核心算法步骤
第一步:计算当前用户的 GeoHash
假设用户坐标为 (lat, lon),将其转换为长度为 5 的 GeoHash 字符串,例如 wx4g0。
第二步:解决“边界问题”(关键点)
问题:如果用户刚好站在一个格子的边缘,他附近的人可能在隔壁的格子里,但隔壁格子的 GeoHash 前缀可能完全不同(例如 wx4g0 和 wx4fb)。
解决方案:九宫格查找。
不仅查询用户当前所在的格子,还要计算出该格子周围的 8 个邻居格子。
- 中心格子:
wx4g0 - 周围 8 个格子:
wx4g1,wx4g2, ... 等(通过算法计算得出)。
这样,我们就得到了 9 个 GeoHash 字符串。这 9 个格子拼起来的区域大约是 ,绝对包含了用户周围 5km 的圆形区域。
第三步:数据库查询(粗筛)
在数据库中,用户表应该有一个 geohash 字段,并建立了索引(通常是 B-Tree 索引,支持最左前缀匹配)。
SQL 伪代码如下:
SELECT * FROM user_location
WHERE
geohash LIKE 'wx4g0%' OR
geohash LIKE 'wx4g1%' OR
... (共9个LIKE条件)注意:为了性能,实际存储时通常存完整的 GeoHash(如长度 12),查询时用 LIKE '前缀%' 利用索引。
第四步:内存计算与精细过滤
数据库返回的数据是位于这 9 个矩形区域内的所有用户(可能包含距离超过 5km 的角落用户)。
在应用程序代码(Java/Go/Python等)中遍历这些结果:
- 利用 Haversine 公式(或球面距离公式)计算当前用户与查询出的每个用户的精确距离。
- 剔除距离 > 5km 的用户。
- 按距离进行排序。
4. 架构优化与替代方案
虽然上述基于 MySQL + GeoHash 算法的方案可行,但在高并发场景下,直接查数据库效率较低。
方案 A:使用 Redis (推荐)
Redis 自 3.2 版本起内置了 GEO 类型,底层实现正是 GeoHash,但它封装了所有复杂的计算。
实现命令:
- 存储:
GEOADD users:location 116.40 39.90 user_id_1 - 查询:
GEORADIUS users:location 116.40 39.90 5 km WITHDIST ASC
优点:
- 速度极快(基于内存)。
- 自动处理了 GeoHash 的精度、边界问题和距离排序。
- 开发成本极低。
方案 B:数据库索引优化
如果必须用 MySQL:
- 不要用
LIKE多个 OR,可能会导致索引失效或效率低。 - 可以将 GeoHash 转换为 Base32 编码后的整数 或者是 Hilbert Curve(希尔伯特曲线) 整数,将二维查询转化为一维的
BETWEEN范围查询,效率更高。
5. 总结
基于 GeoHash 实现“附近 5 公里”的完整流程:
- 选精度:定为 Length = 5。
- 找邻居:计算中心点 + 8 个周边格子的 GeoHash 前缀。
- 查数据:在数据库中通过
LIKE '前缀%'筛选出这 9 个格子内的用户(利用索引)。 - 算距离:在代码层计算精确距离,过滤掉 > 5km 的点。
- 做排序:按距离排序返回。
最佳实践:直接使用 Redis GEO 模块,它内部实现了上述所有逻辑且性能更优。