 播面
播面 如何设计验证码验证机制来防止机器流量?
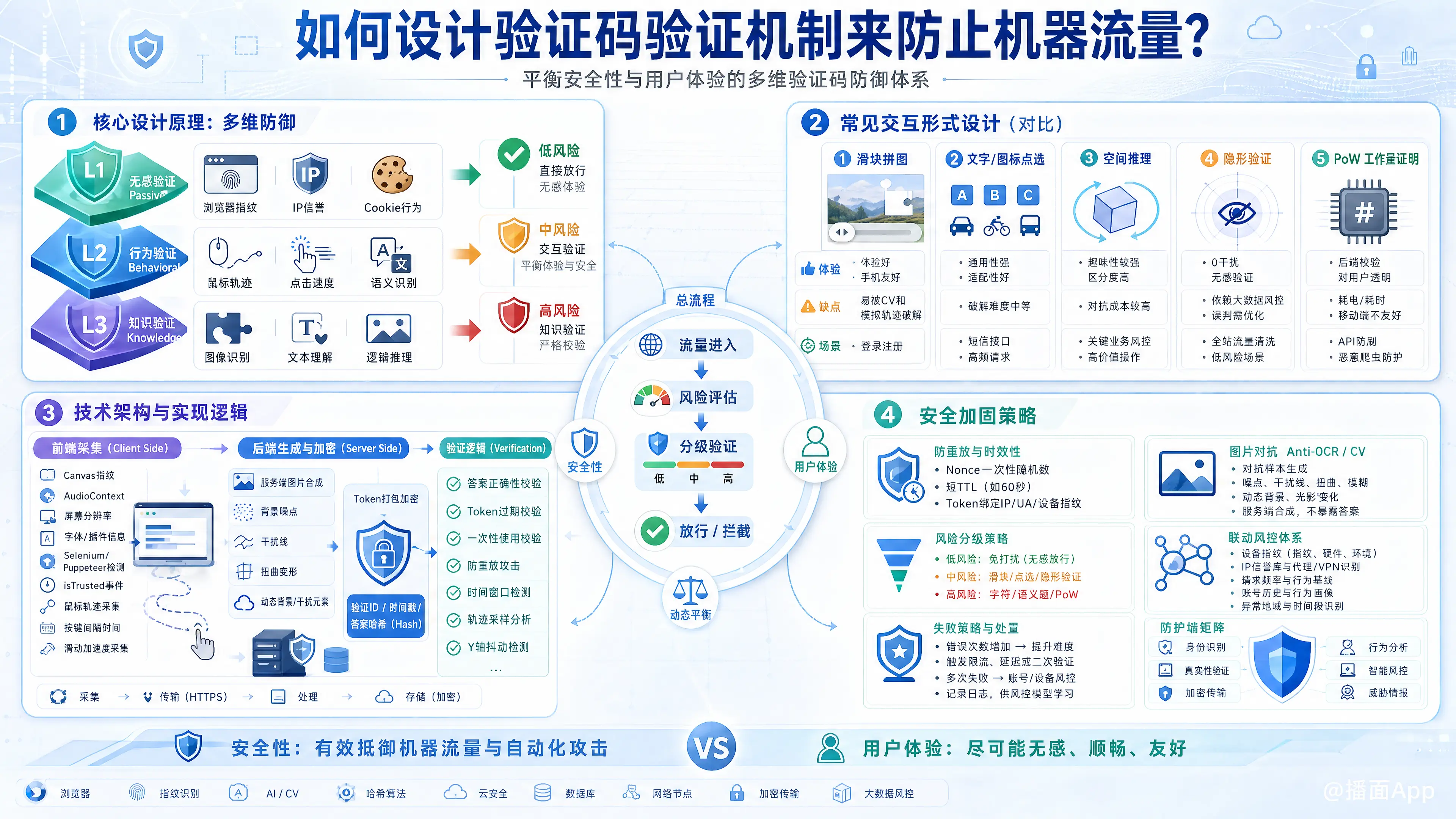
设计一个高效的验证码(CAPTCHA)系统,核心在于平衡安全性(拦截机器)与用户体验(不干扰真人)。现代验证码不仅仅是一张扭曲的图片,而是一套包含行为分析、环境检测和交互验证的综合防御体系。
以下是设计一个防机器流量验证码机制的完整指南,分为核心原理、交互形式、技术架构和安全加固四个部分。
一、 核心设计原理:多维防御
不要只依赖单一的验证方式,应采用“纵深防御”策略:
- 无感验证(Passive): 优先通过浏览器指纹、IP信誉、Cookie行为判断是否为真人。如果是低风险用户,直接放行,无需验证码。
- 行为验证(Behavioral): 如果有风险,弹出滑块或点选,收集鼠标轨迹、点击速度等生物特征。
- 知识验证(Knowledge): 如果风险极高,才使用传统的字符识别或语义理解(如“请选出所有的红绿灯”)。
二、 常见的交互形式设计
根据场景选择合适的验证方式:
| 类型 | 描述 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 滑块拼图 | 拖动滑块将拼图对齐 | 体验较好,手机端友好 | 容易被CV(计算机视觉)和模拟轨迹破解 | 登录、注册、一般操作 |
| 文字/图标点选 | 按顺序点击文字或特定图标 | 破解难度中等,干扰性适中 | 用户需思考,体验稍差 | 短信接口、高频请求 |
| 空间推理 | 旋转图片至正向、物体匹配 | AI破解难度较高 | 交互新颖,但可能困惑用户 | 关键业务风控 |
| 隐形验证 (Invisible) | 后台静默收集数据 | 用户体验极佳(0干扰) | 依赖大数据风控能力 | 全站流量清洗 |
| PoW (工作量证明) | 让客户端计算哈希值 | 增加攻击者CPU成本 | 对正常用户设备耗电有影响 | API接口防刷 |
三、 技术架构与实现逻辑
一个健壮的验证码系统需要包含以下流程:
1. 前端采集 (Client Side)
前端不仅负责展示UI,更重要的是采集“非机器人”特征:
- 环境指纹: Canvas指纹、AudioContext、屏幕分辨率、字体列表、插件列表(检测Selenium/Puppeteer等自动化工具特征)。
- 生物行为: 鼠标移动轨迹(机器通常是直线,人是曲线)、点击压力、按键间隔时间、滑动加速度。
- 事件监听: 监听
isTrusted属性,检测是否由脚本触发的事件。
2. 后端生成与加密 (Server Side)
绝对不要在前端生成验证码答案!
- 图片生成: 背景噪点、干扰线、扭曲变形。图片必须在服务端合成,只下发最终图片(不要下发背景图+缺口图让前端拼合,容易被还原)。
- Payload加密: 将验证ID、时间戳、答案哈希等信息加密打包成Token下发给前端。
3. 验证逻辑 (Verification)
当用户提交验证时,后端进行校验:
- 基础校验: 答案是否正确?Token是否过期?Token是否被重复使用(防重放攻击)?
- 轨迹分析(核心):
- 时间检测: 从加载到完成的时间是否过短(<0.5秒通常是机器)?
- 轨迹采样: 检查鼠标/手指轨迹数组。如果是完美的直线或数学函数曲线,判定为机器。
- Y轴抖动: 真人拖动滑块时,鼠标在Y轴上会有微小的抖动,机器通常没有。
四、 安全加固策略 (防破解关键)
这是区分“玩具级验证码”和“工业级验证码”的关键:
1. 防重放与时效性
- Nonce (一次性随机数): 每个验证码Token只能验证一次,验证后立即失效。
- 短TTL: 验证码图片/Token有效期设为短时间(如60秒),过期强制刷新。
2. 图片对抗 (Anti-OCR/CV)
- 对抗样本: 在图片中加入人眼不可见但能干扰AI模型的微小噪点(Adversarial Perturbation)。
- 动态缺口: 滑块缺口的位置、形状必须完全随机。
- 语义混淆: 例如要求“点击所有能飞的东西”,而不是简单的“点击鸟”,增加AI理解难度。
3. 混淆与加密
- 前端代码混淆: 对采集指纹的JS代码进行高度混淆(Obfuscation),防止攻击者逆向分析采集逻辑。
- 参数加密: 提交的轨迹数据必须加密(如AES),防止攻击者直接伪造请求包。
4. 蜜罐技术
- 在HTML中隐藏一些对人眼不可见(
opacity: 0或z-index: -1)的输入框。 - 如果这些输入框被填写了数据,说明是脚本自动填写的,直接封禁。
5. 频率限制 (Rate Limiting)
- 即使验证码通过,如果同一IP/设备ID在短时间内通过次数过多,依然触发风控(可能是打码平台/人工刷单)。
五、 架构设计示例 (滑块验证码)
初始化:
- 客户端请求验证码。
- 服务端生成背景图和缺口图,记录缺口X坐标。
- 服务端生成唯一
trace_id,将AES(trace_id + X坐标 + timestamp)作为Token返回前端。
交互:
- 用户拖动滑块。
- 前端JS记录鼠标移动坐标数组
[(x1,y1,t1), (x2,y2,t2)...]。
提交:
- 客户端提交
Token+最终X坐标+加密后的轨迹数组。
- 客户端提交
服务端验证:
- 解密Token,校验时间戳是否过期。
- 校验
最终X坐标与 Token中的X坐标误差是否在允许范围内(如 ±2px)。 - AI模型/规则引擎介入: 分析轨迹数组。如果轨迹过于平滑、速度均匀或无抖动,判定为Bot。
六、 总结与建议
如果你是个人开发者或小团队:
强烈建议不要自己造轮子。与专业的黑产(OCR破解、打码平台)对抗需要庞大的数据和AI能力。
- 推荐方案: 接入成熟的第三方服务,如 Cloudflare Turnstile(免费、隐私友好)、Google reCAPTCHA v3(无感)、hCaptcha 或国内的 极验 (Geetest)、数美。
如果你必须自研(出于合规或特殊需求):
- 重后端,轻前端: 核心逻辑放在后端。
- 上指纹: 必须结合浏览器指纹识别。
- 动态调整: 监控通过率,一旦发现突增,立即更换图片库或加密算法。