 播面
播面 ZeRO (Zero Redundancy Optimizer) 的三个阶段(Stage 1, 2, 3)分别切分了什么?
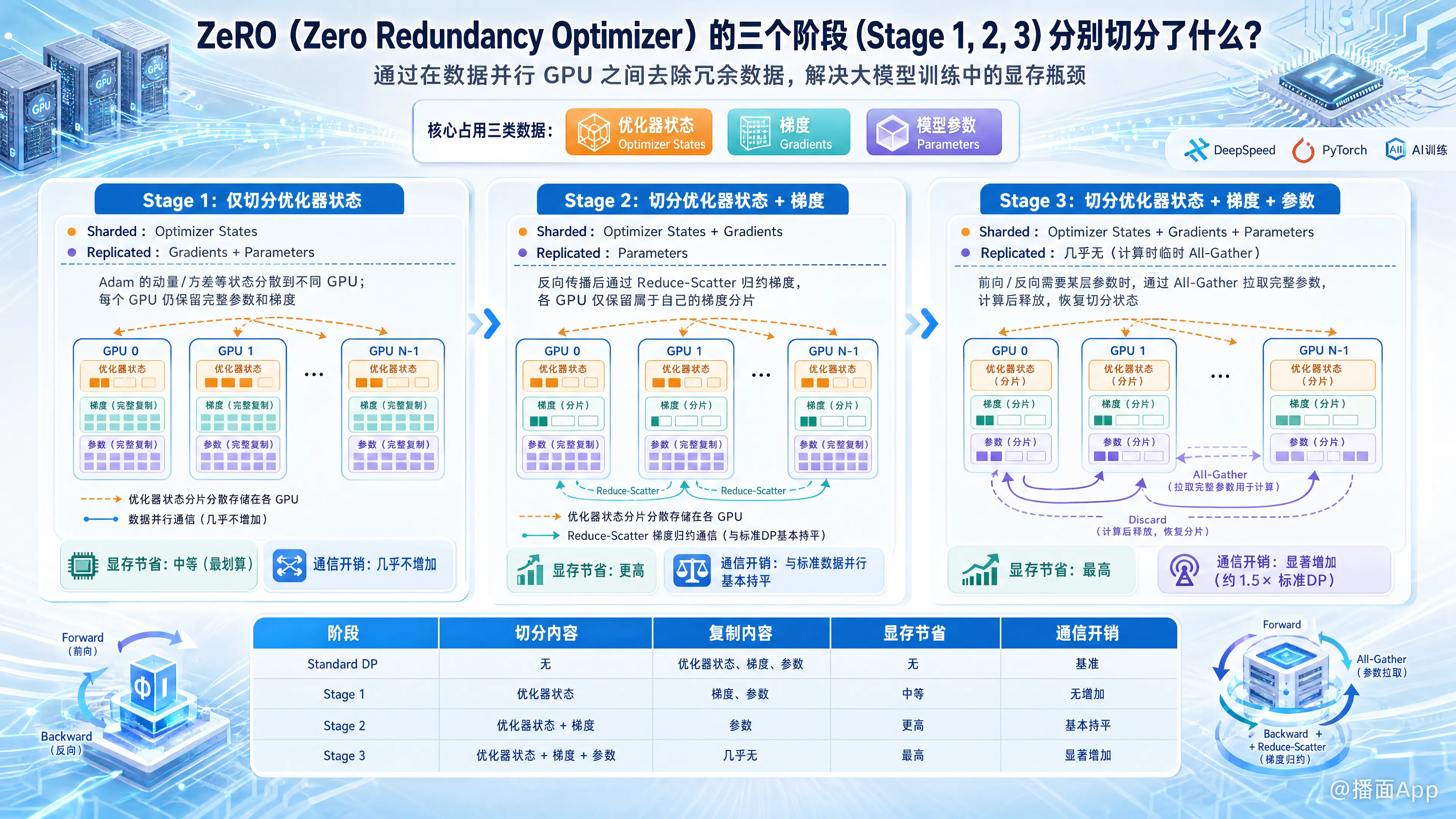
ZeRO (Zero Redundancy Optimizer) 是 DeepSpeed(以及后来的 PyTorch FSDP)的核心技术,旨在解决大模型训练中的显存瓶颈。它通过在数据并行(Data Parallelism)的各个 GPU 之间去除冗余数据来节省显存。
在大模型训练中,显存主要被三类数据占用:优化器状态 (Optimizer States)、梯度 (Gradients) 和 模型参数 (Parameters)。
ZeRO 的三个阶段分别切分(Shard/Partition)了以下内容:
简短总结
- Stage 1: 仅切分 优化器状态。
- Stage 2: 切分 优化器状态 + 梯度。
- Stage 3: 切分 优化器状态 + 梯度 + 模型参数。
详细解析
为了理解这三个阶段,假设我们使用 Adam 优化器 和 混合精度训练 (Mixed Precision),模型参数量为 。
1. ZeRO Stage 1:切分优化器状态 (Partitioning Optimizer States)
- 切分内容:仅将 Optimizer States(如 Adam 的动量 momentum 和方差 variance)分散存储在不同的 GPU 上。
- 保留内容:每个 GPU 仍然保留完整的 模型参数 和 梯度。
- 原理:在使用 Adam 优化器时,优化器状态占用的显存通常是模型参数的 2-3 倍(甚至更多)。因此,只切分这一部分就能带来巨大的显存节省(约节省 4 倍显存),且不会增加额外的通信开销。
2. ZeRO Stage 2:切分梯度 (Partitioning Gradients)
- 切分内容:同时将 Optimizer States 和 Gradients 分散存储。
- 保留内容:每个 GPU 仍然保留完整的 模型参数。
- 原理:在反向传播计算梯度时,每个 GPU 计算出梯度后,通过
Reduce-Scatter操作,将不同部分的梯度归约到对应的 GPU 上进行更新,而不是像传统数据并行那样每个 GPU 都持有完整梯度。 - 效果:相比 Stage 1,进一步节省了梯度的显存(约节省 8 倍显存),通信开销与标准数据并行基本持平。
3. ZeRO Stage 3:切分模型参数 (Partitioning Parameters)
- 切分内容:将 Optimizer States、Gradients 和 Model Parameters 全部切分。
- 保留内容:每个 GPU 只持有一部分参数、一部分梯度和一部分优化器状态。
- 原理:
- 存储时:参数是切分的。
- 计算时:在进行前向传播(Forward)和反向传播(Backward)时,当需要某层参数时,通过
All-Gather通信从其他 GPU 获取完整参数,计算完后立即释放(Discard),恢复到切分状态。
- 效果:显存占用降到最低(显存占用与 GPU 数量成线性反比),可以训练极其巨大的模型。
- 代价:由于每次计算都需要拉取参数,通信开销会显著增加(约为标准数据并行的 1.5 倍)。
对比图表
| ZeRO 阶段 | 切分内容 (Sharded) | 复制内容 (Replicated) | 显存节省程度 | 通信开销 |
|---|---|---|---|---|
| Standard DP | 无 | 优化器状态, 梯度, 参数 | 无 | 基准 |
| Stage 1 | 优化器状态 | 梯度, 参数 | 中等 (最划算) | 无增加 |
| Stage 2 | 优化器状态 + 梯度 | 参数 | 高 | 无增加 |
| Stage 3 | 优化器状态 + 梯度 + 参数 | 无 | 极高 (最大化) | 增加 (约+50%) |
一句话建议:
通常情况下,Stage 2 是性价比最高的选择(显存节省多且速度快);如果显存依然不够,才使用 Stage 3。