 播面
播面 什么是算子融合(Operator Fusion)?
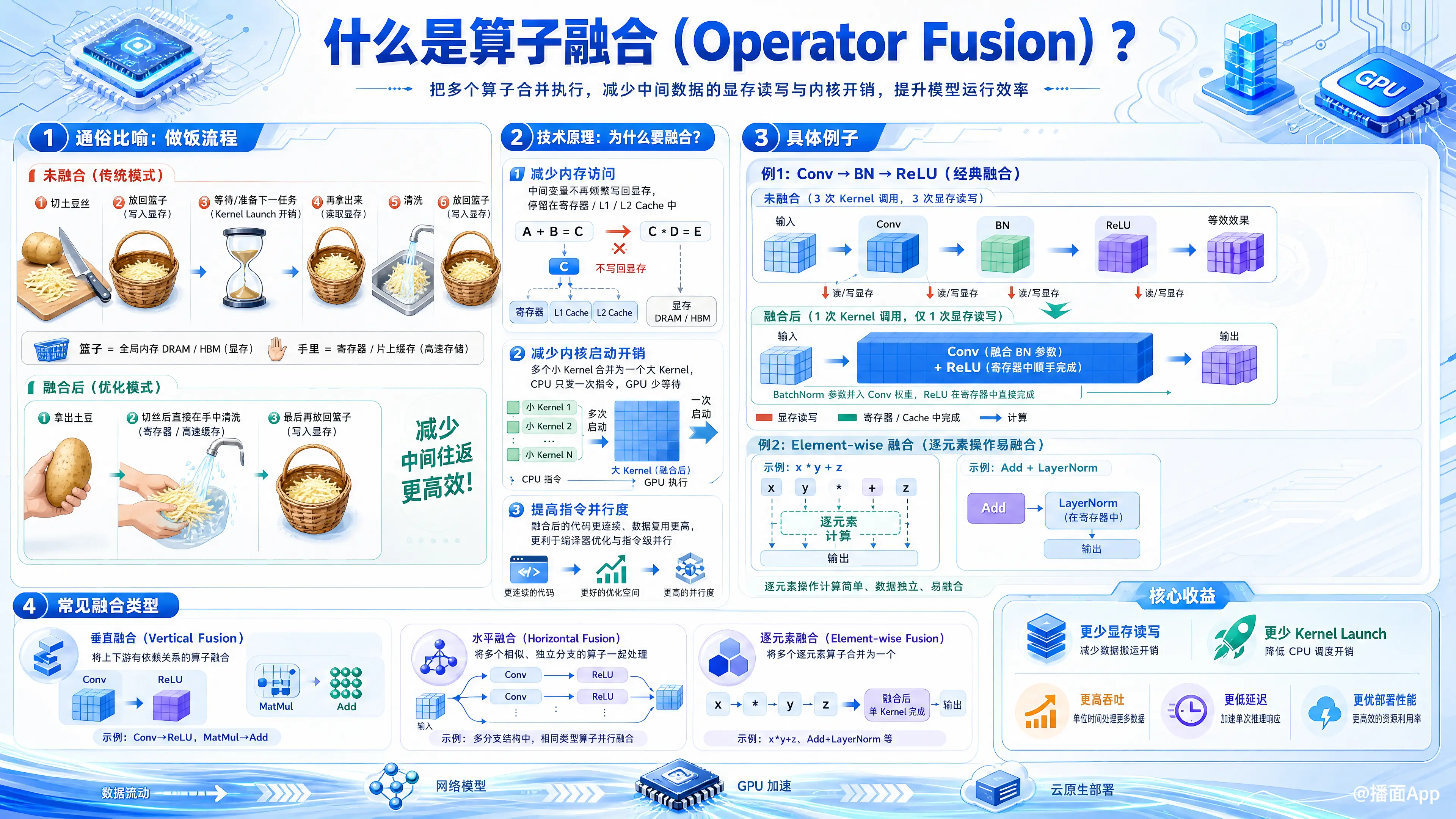
算子融合(Operator Fusion) 是深度学习模型部署和推理优化中非常关键的一种技术。
简单来说,它的核心思想是:将神经网络中的多个连续的简单计算操作(算子),合并成一个大的计算操作(内核/Kernel),以便一次性完成计算。
为了让你更直观地理解,我们可以从“通俗比喻”、“技术原理”、“具体例子”和“优缺点”四个方面来拆解。
1. 通俗比喻:做饭的流程
想象你在厨房切菜(处理数据):
- 任务 A:把土豆切成丝。
- 任务 B:把土豆丝洗一下。
没有算子融合(传统模式):
- 你把土豆从篮子里拿出来,切成丝。
- 把切好的土豆丝放回篮子里(写入显存)。
- 你休息一下,准备下一个任务(Kernel Launch 开销)。
- 你再把土豆丝从篮子里拿出来(读取显存)。
- 洗土豆丝。
- 放回篮子。
使用了算子融合(优化模式):
- 你把土豆拿出来,切成丝,手里拿着直接洗一下(在寄存器/高速缓存中完成,不放回篮子)。
- 最后处理完再放回篮子。
区别: 省去了中间把土豆丝“放回篮子”又“拿出来”的过程。在计算机中,这个“篮子”就是读写速度较慢的全局内存(DRAM/HBM),而“手里”就是速度极快的寄存器或片上缓存。
2. 技术原理:为什么要融合?
在深度学习(尤其是 GPU 计算)中,性能瓶颈通常不在于“计算有多快”,而在于“数据搬运有多慢”。算子融合主要解决了以下三个问题:
减少内存访问(Memory Access):
- 问题: 显存(HBM/GDDR)的读写速度远低于 GPU 核心的计算速度。如果执行
A + B = C然后C * D = E,中间变量C通常会被写回显存,然后再读出来。 - 解决: 融合后,
C存在 GPU 的寄存器或 L1/L2 缓存中,直接进行下一步计算,无需往返显存。这是算子融合带来的最大性能提升。
- 问题: 显存(HBM/GDDR)的读写速度远低于 GPU 核心的计算速度。如果执行
减少内核启动开销(Kernel Launch Overhead):
- 问题: 每次 GPU 执行一个算子(Kernel),CPU 都需要下达指令来启动它。这个启动过程是有时间成本的(几微秒)。如果有成千上万个微小的算子,CPU 光是发号施令就累死了,GPU 却在等指令。
- 解决: 把 10 个小算子合并成 1 个大算子,CPU 只需要发一次启动指令。
提高指令并行度:
- 合并后的代码往往能让编译器进行更深层次的指令优化。
3. 具体的例子
经典的 Conv + BN + ReLU 融合
在卷积神经网络(CNN)中,最常见的模式是:Convolution(卷积) -> BatchNorm(归一化) -> ReLU(激活函数)
- 未融合前: 需要 3 次 GPU Kernel 调用,数据要读写显存 3 次。
- 融合后:
BatchNorm是线性变换,可以将其参数(均值、方差)直接融合进Convolution的权重矩阵中(数学上的合并)。ReLU是简单的判断x > 0 ? x : 0,可以在卷积计算完输出结果的一瞬间,顺便在寄存器里做掉。- 结果: 最终只运行 1 个 Kernel,看起来就像只做了一个卷积,但效果等同于三个算子。
Element-wise(逐元素)融合
比如 Transformer 中的 Add + LayerNorm,或者简单的 x * y + z。这些操作都是对对应位置的元素进行计算,非常容易合并成一个循环来执行。
4. 常见的融合类型
- 垂直融合(Vertical Fusion):
- 将序列上前后依赖的算子合并。例如:
Conv -> ReLU,MatMul -> Add。
- 将序列上前后依赖的算子合并。例如:
- 水平融合(Horizontal Fusion):
- 将输入相同、操作相同但相互独立的算子合并。例如:一个输入同时传给三个不同的 1x1 卷积核,可以合并成一个大的卷积核计算。
5. 谁在做算子融合?
你通常不需要自己手写 CUDA 代码来做融合,现在的深度学习框架和编译器会自动帮你做:
- PyTorch 2.0 (
torch.compile) / TensorFlow (XLA): 深度学习框架自带的编译器,会在运行时自动分析图结构并进行融合。 - NVIDIA TensorRT: 工业界最常用的推理加速引擎,其核心能力之一就是极其激进的算子融合策略。
- TVM / MLIR: 开源的深度学习编译器,专注于跨硬件的算子融合和代码生成。
总结
算子融合就是通过减少中间数据的内存读写和减少GPU任务启动次数,来让深度学习模型跑得更快的核心技术。它是“用计算换带宽”思想的典型体现。