 播面
播面 Token-level Streaming对系统有什么挑战?
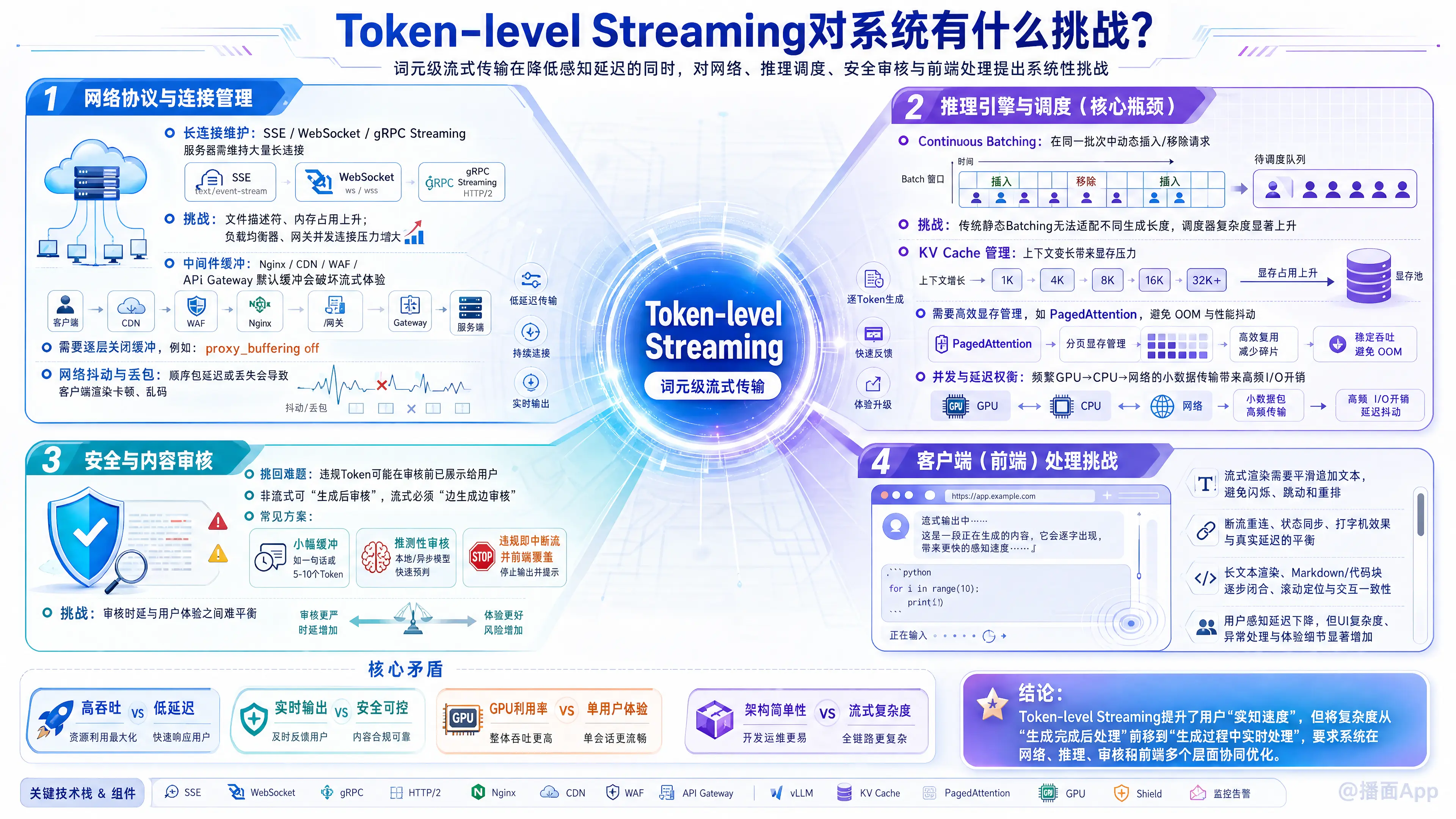
Token-level Streaming(词元级流式传输)是大语言模型(LLM)应用中提升用户体验的关键技术,它允许服务端每生成一个 Token 就立即推送到客户端,而无需等待整个回复生成完毕。
虽然这极大地降低了用户的感知延迟(Perceived Latency),但也给系统架构、网络传输、推理调度和安全审核带来了多维度的挑战。以下是具体的挑战分析:
1. 网络协议与连接管理的挑战
- 长连接维护(Persistent Connections):
- 传统的 REST API 是短连接(请求-响应即断开)。流式传输通常依赖 Server-Sent Events (SSE)、WebSocket 或 gRPC Streaming。这意味着服务器必须为每个并发用户维持一个长连接,直到生成结束。
- 挑战: 这会显著增加服务器的文件描述符(File Descriptors)和内存消耗,对负载均衡器(Load Balancer)和网关(Gateway)的并发连接数限制提出了更高要求。
- 中间件缓冲(Buffering)问题:
- 许多企业级架构中包含 Nginx、CDN、WAF(防火墙)或 API 网关。这些中间件默认可能会开启“缓冲模式”,即攒够一定大小的数据包再转发。
- 挑战: 如果中间件缓冲了数据,流式传输就会失效,用户会看到“卡顿很久,然后突然弹出一大段文字”的现象。需要逐层配置关闭缓冲(如 Nginx 的
proxy_buffering off)。
- 网络抖动与丢包:
- 在流式传输中,数据包是按顺序到达的。如果网络不稳定导致中间某个包丢失或延迟,客户端的渲染就会卡顿,甚至导致解码错误(乱码)。
2. 推理引擎与调度的挑战(核心瓶颈)
这是 LLM 系统后端最硬核的挑战,主要涉及如何在“高吞吐”和“低延迟”之间做平衡。
- Continuous Batching(持续批处理/动态批处理):
- GPU 资源昂贵,必须通过 Batching(批处理)来提高利用率。但在流式场景下,不同请求的生成长度不同(有的刚开始,有的快结束)。
- 挑战: 传统的静态 Batching 必须等一批里最长的那个生成完才能释放资源。系统必须实现 Continuous Batching(如 vLLM, Orca 机制),允许在一个 Batch 中动态插入新请求或移除已完成的请求。这极大地增加了调度器的代码复杂度。
- KV Cache 管理(显存压力):
- 为了流式生成下一个 Token,模型需要保留之前所有 Token 的 Key-Value 状态(KV Cache)。
- 挑战: 随着上下文变长,KV Cache 占用显存巨大。系统需要高效的显存管理机制(如 PagedAttention),否则容易出现 OOM(显存溢出)或因频繁换页导致性能下降。
- 并发与延迟的权衡:
- 为了流式输出,推理引擎必须频繁地将数据从 GPU 显存拷贝到 CPU 内存再发送网络。虽然单次数据量小,但频率极高,这会带来额外的 I/O 开销。
3. 安全与内容审核(Safety & Moderation)
这是流式传输最棘手的业务挑战。
- “撤回”难题:
- 在非流式模式下,系统生成完所有内容后,先过一遍敏感词过滤器,没问题再发给用户。
- 在流式模式下,Token 是实时发出的。如果模型生成到第 50 个 Token 时突然输出了违规内容(如仇恨言论、PII 泄露),此时前 49 个 Token 已经展示在用户屏幕上了。
- 挑战: 系统需要实现“流式审核”或“推测性审核”。通常的做法是小幅缓冲(比如攒够一句话或 5-10 个 Token 再发),以便有时间进行快速审核;或者在检测到违规时强制中断流并覆盖前端显示(但这体验很差)。
4. 客户端(前端)处理的挑战
- Markdown 与代码块渲染闪烁:
- LLM 常输出 Markdown 格式。在流式传输中,语法符号可能被截断。例如,代码块的
```还没闭合,或者加粗的**只发了一半。 - 挑战: 前端渲染器需要具备容错能力,能够解析“不完整的 Markdown”,否则用户会看到页面布局剧烈跳动(Jitter)或原始的语法符号。
- LLM 常输出 Markdown 格式。在流式传输中,语法符号可能被截断。例如,代码块的
- 结构化数据(JSON)解析:
- 如果要求 LLM 返回 JSON 格式,流式传输过来的 JSON 字符串在结束前是不合法的(Invalid JSON)。
- 挑战: 前端无法直接
JSON.parse,需要使用专门的流式 JSON 解析器(如json-repair或增量解析库)来尝试从残缺的字符串中提取字段。
5. 可观测性与监控(Observability)
传统的 HTTP 监控指标(如 QPS、平均响应时间)在流式场景下不够用了。
- 新指标的引入:
- 系统必须监控 TTFT (Time To First Token):首字延迟,决定用户是否觉得系统响应快。
- TPOT (Time Per Output Token):生成速度,决定用户阅读时的流畅度。
- Latency vs. Throughput:需要同时监控这两者,防止为了优化首字延迟而牺牲了整体吞吐量。
- Trace 追踪困难:
- 一个流式请求可能持续几十秒甚至几分钟,跨越多个微服务。如果中间断流,定位是网络问题、推理超时还是客户端主动断开,比传统请求更复杂。
总结
Token-level Streaming 对系统最大的挑战在于从“批处理思维”向“流式思维”的转变。
- 架构层:需要支持长连接和无缓冲传输。
- 算法层:需要实现复杂的 Continuous Batching 和显存管理。
- 业务层:需要在实时性与内容安全性之间做艰难的取舍。