 播面
播面 什么是 Warm-up?为什么在推理服务中很关键?
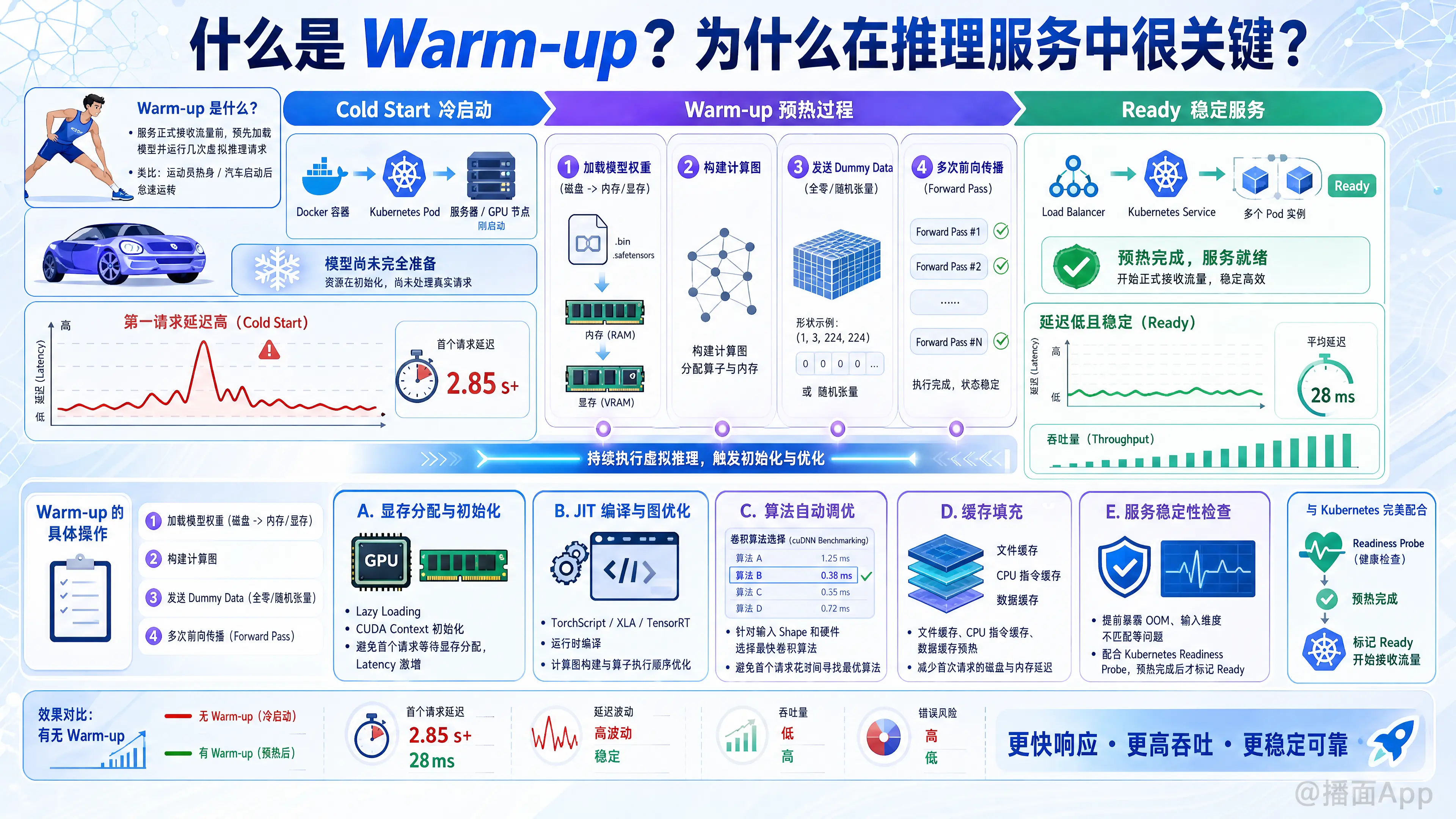
在人工智能和深度学习的推理服务(Inference Service)语境下,Warm-up(预热) 是指在服务正式对外接收用户流量之前,预先加载模型并运行若干次“虚拟”推理请求的过程。
简单来说,就像运动员比赛前要热身、汽车冬天启动后要怠速运转一样,推理服务也需要“热身”才能达到最佳性能状态。
以下是关于 Warm-up 的详细解释,以及为什么它在推理服务中至关重要:
什么是 Warm-up?
当一个推理服务(例如部署在 Docker 容器或 Kubernetes Pod 中的 PyTorch/TensorFlow 模型)刚刚启动时,虽然进程已经运行,但模型并未完全准备好以最高效率处理请求。
Warm-up 的具体操作通常包括:
- 加载模型权重: 将模型文件从磁盘读入内存/显存。
- 构建计算图: 框架解析模型结构。
- 发送 Dummy Data(假数据): 使用与真实请求形状(Shape)和类型(Type)一致的全零或随机张量,通过模型进行几次前向传播(Forward Pass)。
为什么 Warm-up 在推理服务中很关键?
如果不进行预热,服务启动后的前几个请求(First Request)通常会非常慢,这种现象称为冷启动(Cold Start)延迟。Warm-up 的核心目的就是消除这种延迟,确保服务一上线就能提供稳定的低延迟响应。
具体原因涉及以下几个技术层面:
1. 显存分配与初始化 (Memory Allocation)
- 懒加载机制: 许多深度学习框架(如 PyTorch, TensorFlow)和 CUDA 驱动采用“懒加载”(Lazy Loading)策略。即:虽然你加载了模型,但具体的显存(VRAM)分配往往要等到第一次真正执行计算时才发生。
- CUDA Context 初始化: 在 GPU 上运行模型需要初始化 CUDA Context,这是一个耗时的操作。
- 影响: 如果没有预热,第一个用户的请求将不得不等待显存分配和 Context 初始化完成,导致响应时间(Latency)激增,甚至超时。
2. JIT 编译与图优化 (Compilation & Optimization)
- 即时编译 (JIT): 许多现代推理引擎(如 TorchScript, XLA, TensorRT)会在运行时进行 JIT 编译。第一次运行时,框架会将高级代码编译成针对特定硬件优化的机器码或内核(Kernel)。
- 计算图构建: 框架需要构建执行图,确定算子的执行顺序。
- 影响: 编译和构图过程非常消耗 CPU/GPU 资源和时间。预热可以将这一过程提前完成。
3. 算法自动调优 (Auto-tuning / Benchmarking)
- cuDNN Benchmarking: NVIDIA 的 cuDNN 库在执行卷积操作时,有多种算法实现(例如 GEMM, FFT, Winograd 等)。框架通常会在第一次运行时,针对当前的输入尺寸(Input Shape)和硬件环境,测试所有算法并选择最快的一个(这被称为 Auto-tuning)。
- 影响: 这个搜索最优算法的过程非常慢。如果不预热,第一个请求不仅要计算,还要花时间去“寻找最快的计算方法”。
4. 缓存填充 (Caching)
- 操作系统层面的文件缓存(Page Cache)、CPU 的指令缓存和数据缓存,在服务刚启动时都是冷的。预热有助于将关键数据和指令加载到高速缓存中。
5. 服务稳定性检查 (Health Check)
- 提前暴露问题: 有时候模型加载进来了,但一运行就会因为显存不足(OOM)或输入维度不匹配而崩溃。
- 配合负载均衡: 在 Kubernetes 等环境中,Warm-up 通常配合
Readiness Probe使用。只有当预热完成,服务才会被标记为“Ready”,负载均衡器才会将流量转发给它。这避免了服务刚启动就因为处理不过来而导致请求失败。
举个例子
假设你部署了一个图像识别服务:
无预热:
- 服务启动。
- 用户 A 发送图片 -> 系统开始初始化 CUDA、分配显存、编译计算图、寻找最优卷积算法 -> 耗时 3 秒 -> 返回结果。
- 用户 B 发送图片 -> 系统已就绪 -> 耗时 0.1 秒 -> 返回结果。
- 结果:用户 A 体验极差,甚至可能导致客户端超时报错。
有预热:
- 服务启动。
- 脚本自动发送 5 张空白图片 -> 系统内部完成初始化、编译、调优(耗时 3 秒)。
- 服务标记为“就绪”,开始对外暴露端口。
- 用户 A 发送图片 -> 系统已就绪 -> 耗时 0.1 秒 -> 返回结果。
- 结果:所有用户都获得了极速响应。
总结
在推理服务中,Warm-up 是用启动时间的延长换取运行时性能的稳定。它将原本会发生在第一个用户身上的“惩罚”(高延迟)转移到了服务启动阶段,是生产环境部署 AI 模型(特别是大模型、GPU 模型)的标准最佳实践。