 播面
播面 推理服务如何应对流量抖动和冷启动问题?
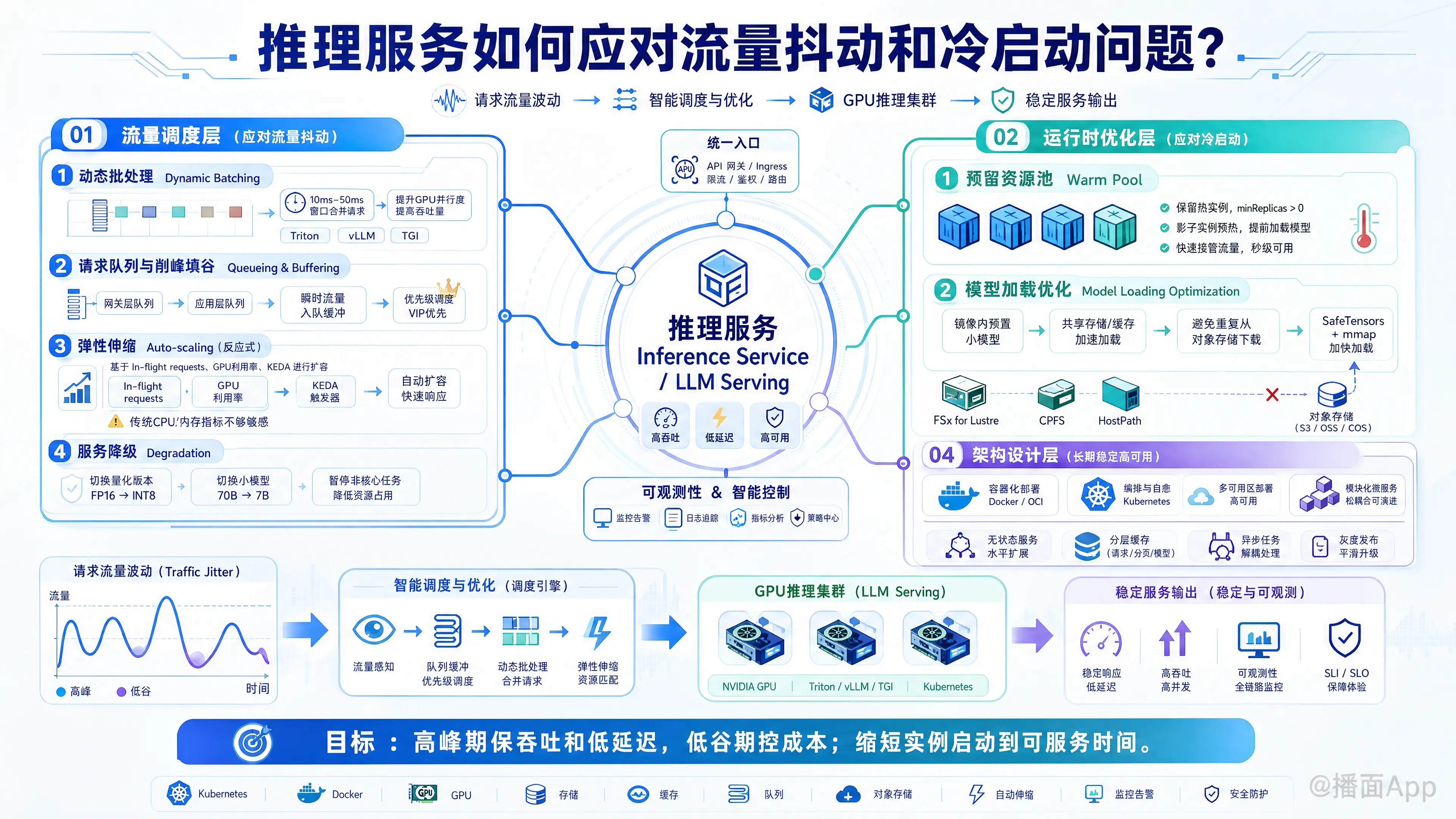
推理服务(Inference Service),特别是针对大语言模型(LLM)或深度学习模型的服务,在面对流量抖动(Traffic Jitter/Spikes)和冷启动(Cold Start)时,面临着巨大的挑战。这主要是因为模型加载慢、显存占用大、计算资源昂贵。
以下是工业界通用的解决方案,分为流量调度层、运行时优化层、资源管理层和架构设计层四个维度进行详细解析:
一、 应对流量抖动 (Handling Traffic Jitter)
流量抖动指的是请求量在短时间内剧烈波动。目标是在高峰期保证吞吐量和低延迟,在低谷期节省成本。
1. 动态批处理 (Dynamic Batching)
这是 GPU 推理服务最核心的抗抖动手段。
- 原理:服务端不立即处理单个请求,而是设置一个极短的时间窗口(如 10ms-50ms),将该窗口内到达的多个请求合并成一个 Batch 发送给 GPU。
- 优势:GPU 擅长并行计算,Batch Size 越大(在显存允许范围内),单位成本越低,吞吐量越高。
- 工具:NVIDIA Triton Inference Server、vLLM(Continuous Batching)、TGI (Text Generation Inference)。
2. 请求队列与削峰填谷 (Queueing & Buffering)
- 多级队列:在网关层(Nginx/Gateway)和应用层设置队列。当流量瞬间暴涨超过处理能力时,将请求暂存入队列,而不是直接拒绝或导致服务崩溃。
- 优先级调度:区分 VIP 用户或核心业务,优先处理高优先级请求,普通请求在队列中等待或降级。
3. 弹性伸缩 (Auto-scaling) - 反应式
- 基于并发数的伸缩 (KEDA):传统的 CPU/Memory 指标对 GPU 推理不敏感。应使用 KEDA (Kubernetes Event-driven Autoscaling) 监控正在处理的请求数 (In-flight requests) 或 GPU 利用率。一旦指标超过阈值,立即扩容 Pod。
- 扩容速度:虽然是反应式的,但配合下文的“冷启动优化”,可以加快扩容速度。
4. 服务降级 (Degradation)
在流量极端不可控时,为了保住主服务可用性:
- 降低精度:临时切换到量化版本(如从 FP16 切到 INT8)或更小的模型(如从 70B 切到 7B)。
- 非核心功能熔断:暂停非关键的推理任务(如后台的日志分析、推荐刷新)。
二、 应对冷启动 (Handling Cold Start)
冷启动是指新实例启动到能处理请求之间的时间,通常包括:节点调度 -> 镜像拉取 -> 容器启动 -> 模型权重下载 -> 模型加载进显存。对于 LLM,这个过程可能长达数分钟。
1. 预留资源池 (Warm Pool / Over-provisioning)
- 原理:始终保持一定数量的“热”实例(Warm Instances),即使没有流量也不缩容到 0(或者保留最小副本数 minReplicas > 0)。
- 影子实例:在流量上涨趋势初现时,提前启动影子实例进行预热,待流量真正到来时直接切换。
2. 模型加载优化 (Model Loading Optimization)
这是缩短冷启动时间的关键:
- 镜像内预置模型:将模型权重直接打入 Docker 镜像(适合小模型)。
- 共享存储与缓存:对于大模型,使用高性能共享存储(如 AWS FSx for Lustre, 阿里云 CPFS)或 HostPath 挂载,避免每次从 S3/OSS 下载。
- 使用 mmap (内存映射):使用
SafeTensors格式替代 PyTorch 的.bin(Pickle)。SafeTensors 支持mmap,可以将模型文件直接映射到内存,极大减少加载时间(几乎是瞬间完成 CPU 侧加载,只需等待数据搬运到 GPU)。 - 流式加载:边下载边加载,而不是等下载完再加载。
3. 容器与运行时优化
- 镜像加速:使用 stargz 或 Nydus 等技术实现容器镜像的按需加载 (Lazy Loading),无需下载完整个镜像即可启动容器。
- 显存预分配优化:某些框架启动时会预申请所有显存,导致初始化慢。可以通过配置让其按需申请或快速初始化。
4. 预测性伸缩 (Predictive Scaling)
- 原理:利用时间序列算法(如 Prophet、LSTM)分析历史流量规律(如每天中午 12 点是高峰)。
- 操作:在预测的高峰到来前 5-10 分钟,提前触发扩容动作,完成冷启动。
三、 综合架构方案 (Architecture Patterns)
1. Serverless 推理架构 (Knative + GPU)
利用 Knative 等 Serverless 框架实现 Scale-to-Zero。
- 应对冷启动:配合“保留实例”策略,只有超出保留实例的流量才触发冷启动。
- 应对抖动:Knative 自带的 Queue Proxy 可以缓冲突发流量。
2. 分离式架构 (Disaggregated Serving) - 针对 LLM
- Prefill-Decode 分离:将 LLM 推理分为 Prefill(首字生成,计算量大)和 Decode(后续生成,IO 密集)两个阶段,部署在不同的机器组上。
- KV Cache 卸载:当显存不足或需要迁移请求时,将 KV Cache 卸载到 CPU 内存,避免重新计算,从而平滑应对流量波动。
3. 异构计算路由
- 当 GPU 资源耗尽时,将部分对延迟不敏感的请求路由到 CPU 集群(虽然慢,但能跑通),或者路由到不同型号的 GPU(如 A100 满了转到 A10)。
总结:最佳实践清单
| 问题 | 核心策略 | 关键技术点 |
|---|---|---|
| 微小抖动 | 动态批处理 | Continuous Batching (vLLM), Triton Server |
| 剧烈抖动 | 队列缓冲 & 降级 | Gateway Queue, Quantization (INT8), Fallback to smaller models |
| 冷启动 (资源) | 预留热池 | MinReplicas > 0, Warm Pool |
| 冷启动 (速度) | 加速加载 | SafeTensors (mmap), Local SSD Cache, Lazy Pulling |
| 长尾/周期性 | 预测性伸缩 | CronHPA, AI-based Prediction |
通过组合“动态批处理”来吞噬瞬间峰值,利用“预测性伸缩”来对抗由于冷启动带来的扩容滞后,并使用“SafeTensors + 共享缓存”从物理上缩短模型加载时间,是目前构建高可用推理服务的标准答案。