 播面
播面 多模型共存(Multi-model Serving)会带来哪些复杂度?
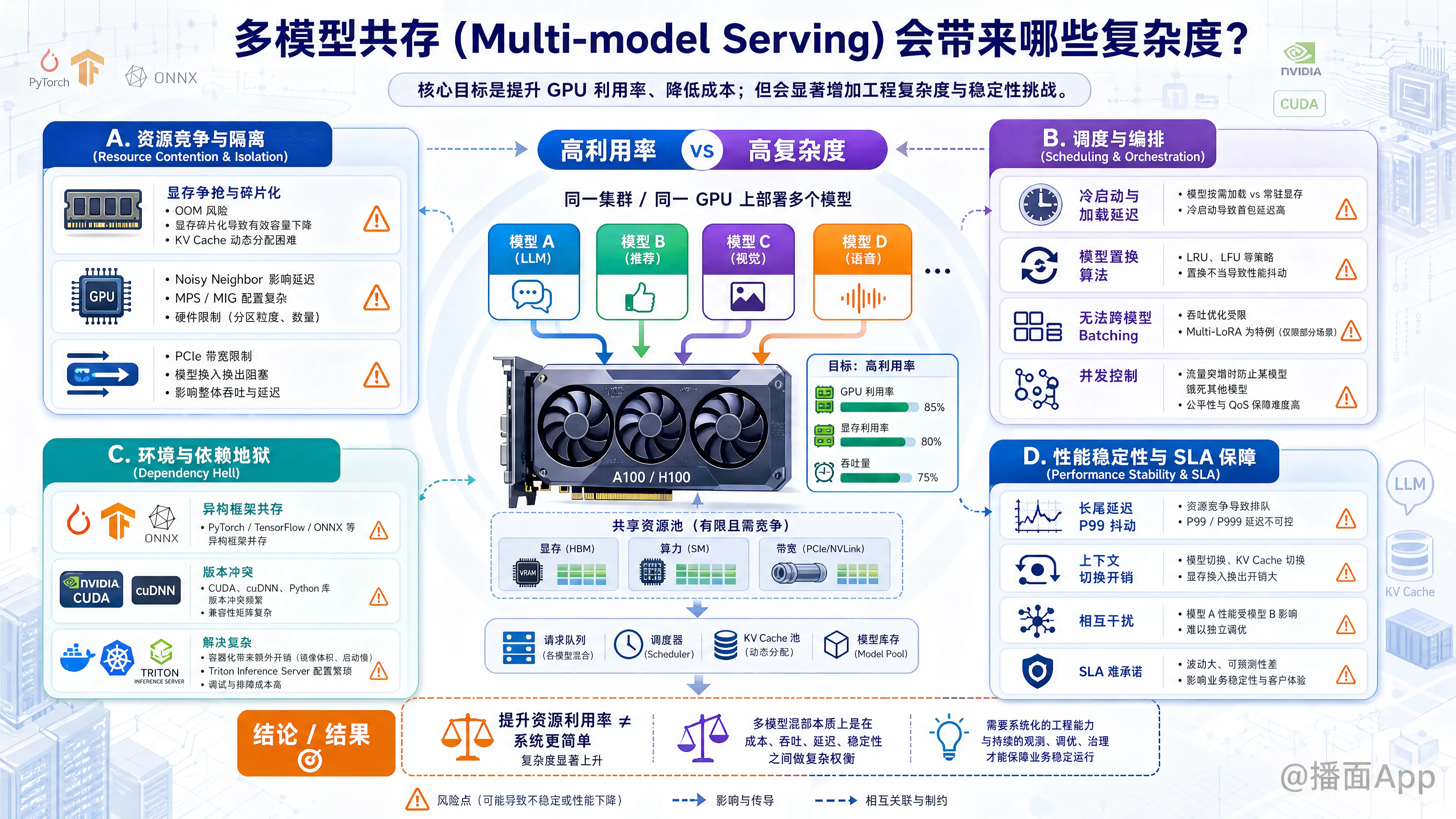
多模型共存(Multi-model Serving)是指在同一个推理服务集群、甚至同一张 GPU 卡上同时部署和运行多个不同的模型。这种做法的核心目的是提高硬件利用率(特别是 GPU)并降低成本,但它同时也引入了极大的工程复杂度和稳定性挑战。
以下是多模型共存带来的主要复杂度,按领域分类:
1. 资源竞争与隔离(Resource Contention & Isolation)
这是最核心的物理瓶颈。
- 显存(VRAM)争抢与碎片化:
- OOM 风险: 多个模型同时加载或推理时,很容易耗尽显存导致 Out Of Memory (OOM) 崩溃。
- 碎片化: 频繁加载和卸载不同大小的模型会导致显存碎片化,即使剩余总显存足够,也可能因为缺乏连续空间而无法加载新模型。
- KV Cache 管理(针对 LLM): 对于大语言模型,推理时的 KV Cache 是动态增长的。多个模型共存时,如何预留和动态分配 KV Cache 空间是一个极难的调度问题。
- 算力(Compute)争抢(Noisy Neighbor 问题):
- 如果一个模型正在进行高强度的矩阵运算,另一个模型的推理请求可能会被阻塞或延迟显著增加。
- 虽然 NVIDIA 提供了 MPS (Multi-Process Service) 或 MIG (Multi-Instance GPU) 技术,但配置复杂且有硬件限制(MIG 仅支持特定高端卡,且切分粒度固定)。
- 带宽瓶颈:
- PCIe 带宽: 当频繁在 CPU 内存和 GPU 显存之间交换模型权重(Model Swapping)时,PCIe 带宽会成为瓶颈,阻塞推理数据传输。
2. 调度与编排(Scheduling & Orchestration)
如何决定何时运行哪个模型,以及模型放在哪里,变得非常复杂。
- 冷启动与加载延迟(Cold Start):
- 如果模型不在显存中,需要从磁盘或对象存储加载。这个过程可能需要几秒到几十秒。如何在“保持模型常驻(浪费显存)”和“按需加载(高延迟)”之间做权衡?
- 需要实现复杂的模型置换算法(如 LRU、LFU),决定在显存不足时踢出哪个模型。
- 无法跨模型 Batching:
- 推理加速的一个关键手段是 Batching(将多个请求合并处理)。但不同模型的结构、权重不同,无法直接合并 Batch。这导致在多模型场景下,很难利用 Batching 带来的吞吐量提升。
- 特例: 除非是 Multi-LoRA 架构(共享 Base Model,只切换 LoRA 权重),否则算力利用率可能不升反降。
- 并发控制:
- 需要实现精细的队列管理。如果模型 A 的流量突增,不能让它饿死模型 B 的请求。
3. 环境与依赖地狱(Dependency Hell)
- 框架异构性:
- 你可能需要同时服务 PyTorch 模型、TensorFlow 模型、ONNX 模型。
- 不同的模型可能依赖不同版本的 CUDA、cuDNN 或 Python 库(例如一个需要
transformers==4.30,另一个需要4.38)。 - 解决方案复杂: 通常需要容器化(每个模型一个容器),但这又增加了资源开销和通信成本;或者使用 Triton Inference Server 这种支持多后端的框架,但配置依然繁琐。
4. 性能稳定性与 SLA 保障
- 长尾延迟(Tail Latency):
- 在单模型服务中,P99 延迟通常比较稳定。但在多模型混部中,由于资源竞争和上下文切换(Context Switching),P99 延迟极易出现抖动。
- 很难对客户承诺严格的 SLA(服务等级协议),因为模型 A 的性能受模型 B 的行为影响。
- 上下文切换开销:
- GPU 在不同 CUDA Kernel 之间切换是有开销的。如果模型切换过于频繁,GPU 可能花费大量时间在“切换”而非“计算”上。
5. 运维与可观测性(Ops & Observability)
- 故障定位困难:
- 当服务崩溃或变慢时,很难判断是哪个模型导致的。是模型 A 的输入太长爆了显存?还是模型 B 的死循环占用了 CUDA Core?
- 监控粒度:
- 传统的 GPU 监控(如
nvidia-smi)是卡级别的。在多模型共存时,你需要模型级别的显存和算力监控,这通常需要深度定制推理服务器才能获取。
- 传统的 GPU 监控(如
- 版本管理爆炸:
- 管理 1 个模型的 3 个版本很简单;管理 50 个不同模型的各自版本、灰度发布、回滚,需要非常强大的 MLOps 平台支持。
6. 大模型时代的特有挑战(LLM Specifics)
- 权重体积巨大: 以前的 ResNet 只有几百 MB,现在的 LLM 动辄几十 GB。模型交换(Swapping)的成本变得极高,几乎不可接受。
- Multi-LoRA 架构: 为了解决上述问题,业界倾向于“共享基座 + 多个 LoRA 适配器”。这虽然解决了显存问题,但带来了新的复杂度:定制化的 CUDA Kernel(需要支持在一个 Batch 中计算不同的 LoRA 权重),如 S-LoRA 或 Punica 等技术的实现难度很高。
总结
多模型共存本质上是在做“GPU 操作系统”的工作:你需要像操作系统管理进程一样,去管理模型的加载、内存分配、时间片调度和隔离。
如果不解决这些复杂度,通常会出现:“省了 GPU 的钱,亏了工程师的命,丢了用户的体验”。