 播面
播面 大模型训练中中的同步训练和异步训练各自的问题是什么?
在大模型训练(如GPT、Llama等)的分布式场景中,同步训练(Synchronous Training)和异步训练(Asynchronous Training)是两种核心的参数更新策略。
目前,主流的大模型训练(LLM)几乎全部采用同步训练(配合各种优化技术),而异步训练更多用于推荐系统或联邦学习等特定场景。
以下是这两种模式各自面临的核心问题:
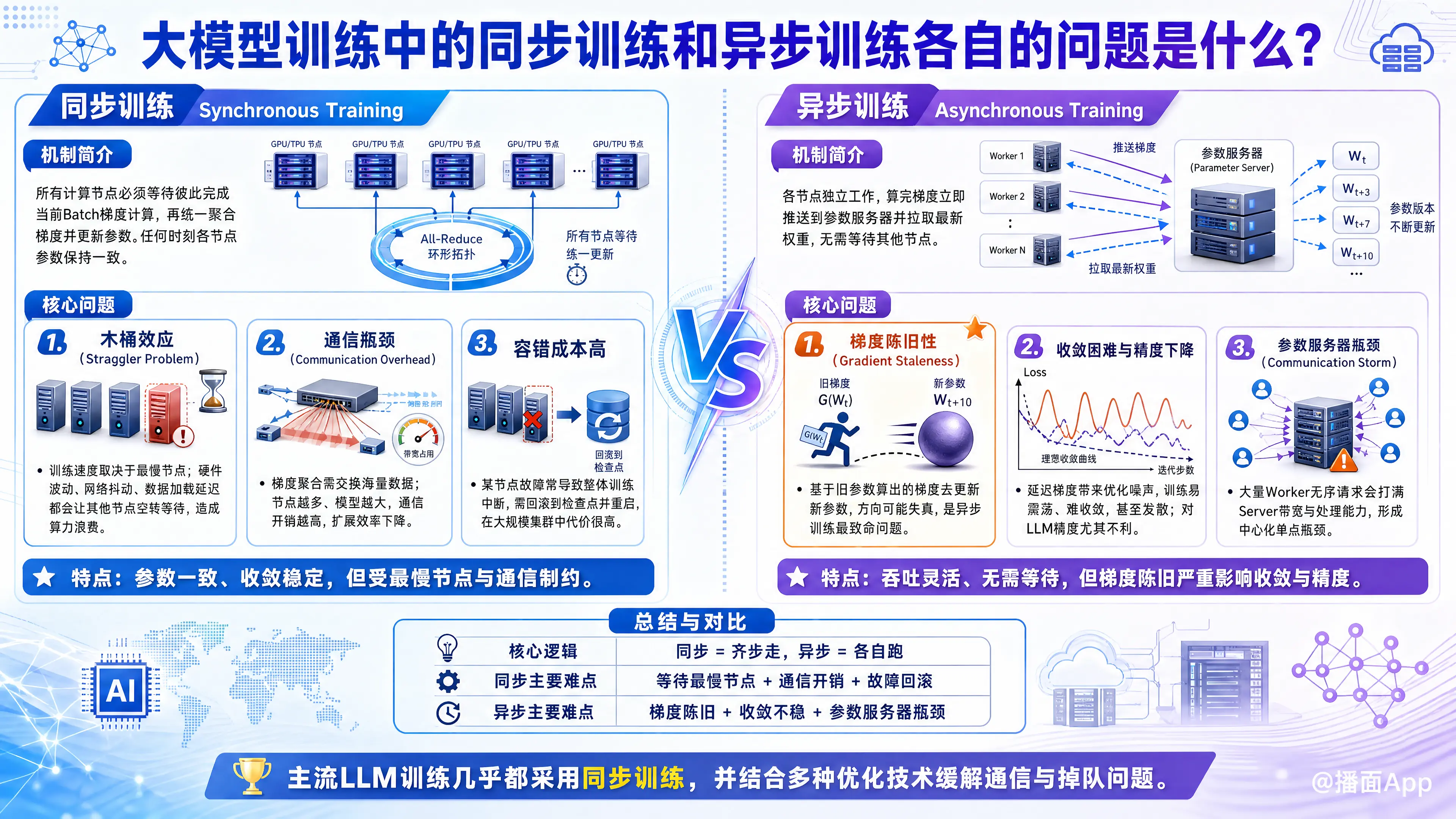
一、 同步训练 (Synchronous Training)
机制简介: 所有计算节点(GPU/TPU)必须等待彼此完成当前批次(Batch)的梯度计算,然后统一进行梯度聚合(All-Reduce),更新参数后,才能进入下一个步骤。所有节点在任何时刻持有的模型参数都是完全一致的。
核心问题:
木桶效应(Straggler Problem / 掉队者问题)
- 描述: 整个系统的训练速度取决于最慢的那个节点。
- 原因: 硬件性能波动(热降频)、网络抖动、操作系统干扰、甚至某个GPU的数据加载稍慢,都会导致该节点计算延迟。
- 后果: 如果有1000张卡,只要有一张卡慢了1秒,其他999张卡都要空转等待这1秒。在大规模集群中,这种等待时间会造成巨大的算力浪费。
通信瓶颈(Communication Overhead)
- 描述: 在梯度聚合阶段,所有节点需要同时交换海量数据。
- 后果: 随着节点数量增加,通信开销会急剧上升。对于大模型,参数量极大(千亿级),梯度数据量巨大,如果网络带宽(如InfiniBand)不足,通信时间可能超过计算时间,导致扩展效率(Scaling Efficiency)下降。
容错成本高
- 描述: 如果训练过程中某个节点崩溃(Fail),整个训练任务通常会中断,需要回滚到上一个检查点(Checkpoint)并重启。
- 后果: 在千卡或万卡集群中,硬件故障是常态。频繁的重启和回滚会严重拖慢训练进度。
二、 异步训练 (Asynchronous Training)
机制简介: 各个计算节点独立工作。节点计算完梯度后,立即推送到参数服务器(Parameter Server)更新权重,并拉取最新的权重继续计算,不需要等待其他节点。
核心问题:
梯度陈旧性(Gradient Staleness / 延迟梯度)
- 这是最致命的问题。
- 描述: 假设节点A拉取了参数 开始计算。在它计算期间,节点B和C已经完成了计算并更新了模型,模型参数变成了 。当节点A计算完梯度 并试图更新模型时,它实际上是用基于“旧参数”算出的梯度去更新“新参数”。
- 后果: 梯度的方向可能已经不再适用于当前的参数位置。这会导致优化方向错误,增加训练的噪声。
收敛困难与精度下降
- 描述: 由于上述的“梯度陈旧”问题,模型很难收敛到最优解。
- 后果: 对于对精度要求极高的大语言模型(LLM),异步训练往往导致Loss无法下降到理想水平,或者训练过程极不稳定(Loss震荡),甚至发散。
参数服务器瓶颈(Communication Storm)
- 描述: 异步训练通常依赖中心化的参数服务器(Parameter Server)。
- 后果: 所有Worker节点都在无序地向Server发送请求。当Worker数量巨大时,Server端的网络带宽和处理能力会瞬间被打满,成为单点瓶颈。
总结与对比
| 特性 | 同步训练 (Synchronous) | 异步训练 (Asynchronous) |
|---|---|---|
| 核心逻辑 | 齐步走,所有人等最慢的 | 自由跑,各跑各的 |
| 最大优点 | 数学严格性好,收敛稳定,精度高 | 吞吐量高,无等待时间,硬件利用率高 |
| 最大痛点 | 木桶效应(受限于慢节点),算力闲置 | 梯度陈旧(Staleness),难以收敛 |
| 大模型现状 | 绝对主流 (配合3D并行、ZeRO等优化) | 极少用于稠密LLM训练,多用于推荐系统 |
为什么大模型现在都用同步训练?
尽管同步训练有“木桶效应”,但通过以下技术已得到极大缓解,且保证模型收敛是第一要务:
- 高性能网络: 使用NVLink和InfiniBand/RoCE解决通信瓶颈。
- 梯度累积(Gradient Accumulation): 减少通信频率。
- 确定性: 同步训练的行为是可复现的,这对于Debug极其昂贵的大模型训练至关重要。
相反,异步训练带来的精度损失在LLM领域通常是不可接受的,因为训练一次的成本高达数百万美元,没人敢冒模型不收敛的风险。