 播面
播面 参数服务器(Parameter Server)架构的优缺点是什么?
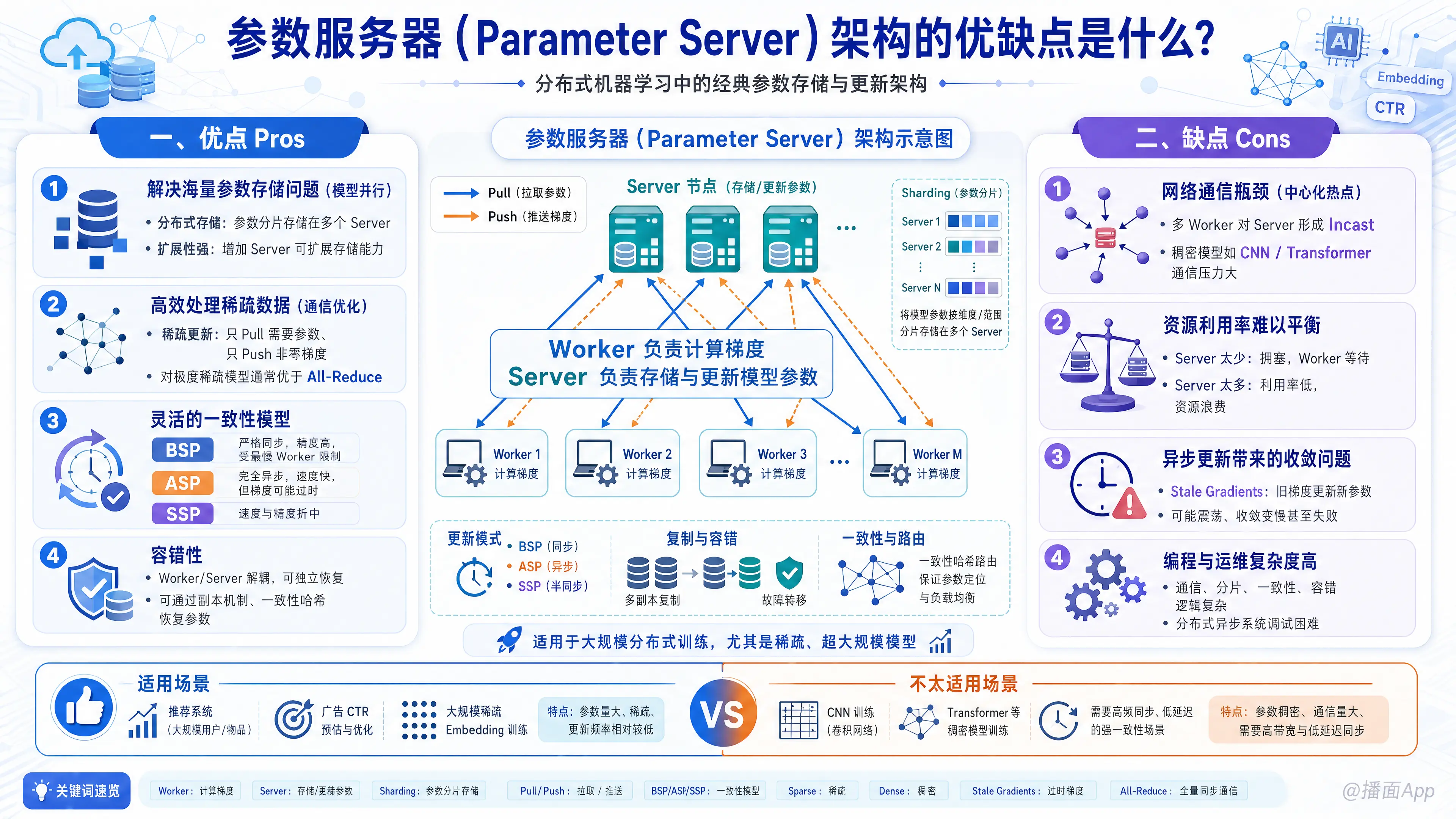
参数服务器(Parameter Server, PS) 是一种用于分布式机器学习的经典架构,主要解决大规模模型训练中的参数存储和更新问题。在这种架构中,集群节点被分为两类:Worker(工作节点) 负责计算梯度,Server(服务节点) 负责存储和更新模型参数。
以下是参数服务器架构的主要优缺点分析:
一、 优点 (Pros)
1. 解决海量参数存储问题(模型并行)
- 分布式存储: 当模型参数量非常大(例如推荐系统中的大规模 Embedding 层,参数量可达万亿级),单机的内存无法容纳时,PS 架构可以将参数分片(Sharding)存储在多个 Server 节点上。
- 扩展性强: 可以通过增加 Server 节点的数量来线性扩展模型参数的存储能力。
2. 高效处理稀疏数据(通信优化)
- 稀疏更新: 在推荐系统、广告点击率预测(CTR)等场景中,特征往往非常稀疏(Sparse)。Worker 只需要从 Server 拉取(Pull)当前计算需要的参数,并只推送(Push)非零的梯度。这大大减少了网络通信量。
- 相比 All-Reduce 的优势: 对于极度稀疏的模型,PS 架构通常比 Ring All-Reduce 架构更高效,因为后者通常需要传输完整的模型梯度。
3. 灵活的一致性模型(Consistency Models)
PS 架构允许在“计算速度”和“模型精度”之间做权衡,支持多种同步协议:
- BSP (Bulk Synchronous Parallel): 严格同步,精度高,但速度受限于最慢的 Worker(木桶效应)。
- ASP (Asynchronous Parallel): 完全异步,速度最快,Worker 之间互不等待,但可能导致梯度过时(Staleness),影响收敛。
- SSP (Stale Synchronous Parallel): 折中方案,允许一定程度的步数差异(Staleness),既保证了速度又限制了误差。
4. 容错性(Fault Tolerance)
- 独立恢复: 由于 Server 和 Worker 是解耦的,如果某个 Worker 挂掉,可以由调度器重启或忽略;如果 Server 挂掉,可以通过一致性哈希或副本机制(Replication)恢复参数,而不必重启整个训练任务。
二、 缺点 (Cons)
1. 网络通信瓶颈(中心化热点)
- 多对一流量(Incast): 在 PS 架构中,所有的 Worker 都要和 Server 通信。当 Worker 数量很多或模型参数非常密集(Dense)时,Server 节点的网络带宽会成为系统的瓶颈。
- 通信开销大: 对于像 CNN(卷积神经网络)或 Transformer 这种稠密模型,每次迭代都需要传输大量参数,PS 架构的通信压力往往大于优化的 All-Reduce 架构。
2. 资源利用率难以平衡
- 角色分配难题: 用户需要手动指定多少个节点做 Server,多少个做 Worker。
- 如果 Server 太少,网络堵塞,Worker 计算完后需排队等待 Push/Pull,导致算力浪费。
- 如果 Server 太多,Server 的 CPU 利用率可能很低,导致资源浪费。
- 相比之下,All-Reduce 架构中每个节点角色对等,不存在这种资源配比的烦恼。
3. 异步更新带来的收敛问题
- 梯度失效(Stale Gradients): 在使用 ASP 或 SSP 模式时,Worker 计算梯度的参数版本可能已经落后于 Server 上的最新参数。使用旧参数计算出的梯度去更新新参数,会导致模型震荡、收敛变慢,甚至无法收敛。
4. 编程与运维复杂度
- 系统复杂: 需要处理复杂的通信逻辑、参数分片策略、一致性控制以及故障恢复逻辑。
- 调试困难: 分布式异步系统中的 Bug 往往难以复现和调试。
三、 总结与适用场景
| 特性 | 参数服务器 (PS) | Ring All-Reduce |
|---|---|---|
| 适用模型 | 稀疏模型 (推荐系统、LR、SVM、超大 Embedding) | 稠密模型 (CV、NLP、BERT、GPT) |
| 通信模式 | 点对点 (Worker <-> Server) | 环状/树状 (节点间互传) |
| 瓶颈 | Server 的网络带宽 | 环中任何一个慢节点 |
| 硬件要求 | 通用以太网即可,但带宽要大 | 最好有高带宽低延迟网络 (如 NVLink, InfiniBand) |
一句话总结:
参数服务器架构是处理超大规模稀疏模型(如万亿参数推荐系统)的首选,但在处理计算密集型、参数稠密的深度学习模型(如大语言模型训练)时,通常不如 Ring All-Reduce 架构高效。不过,现代的架构(如 BytePS)正在尝试融合两者的优点。