 播面
播面 什么是 All-Reduce?它在分布式训练中起什么作用?
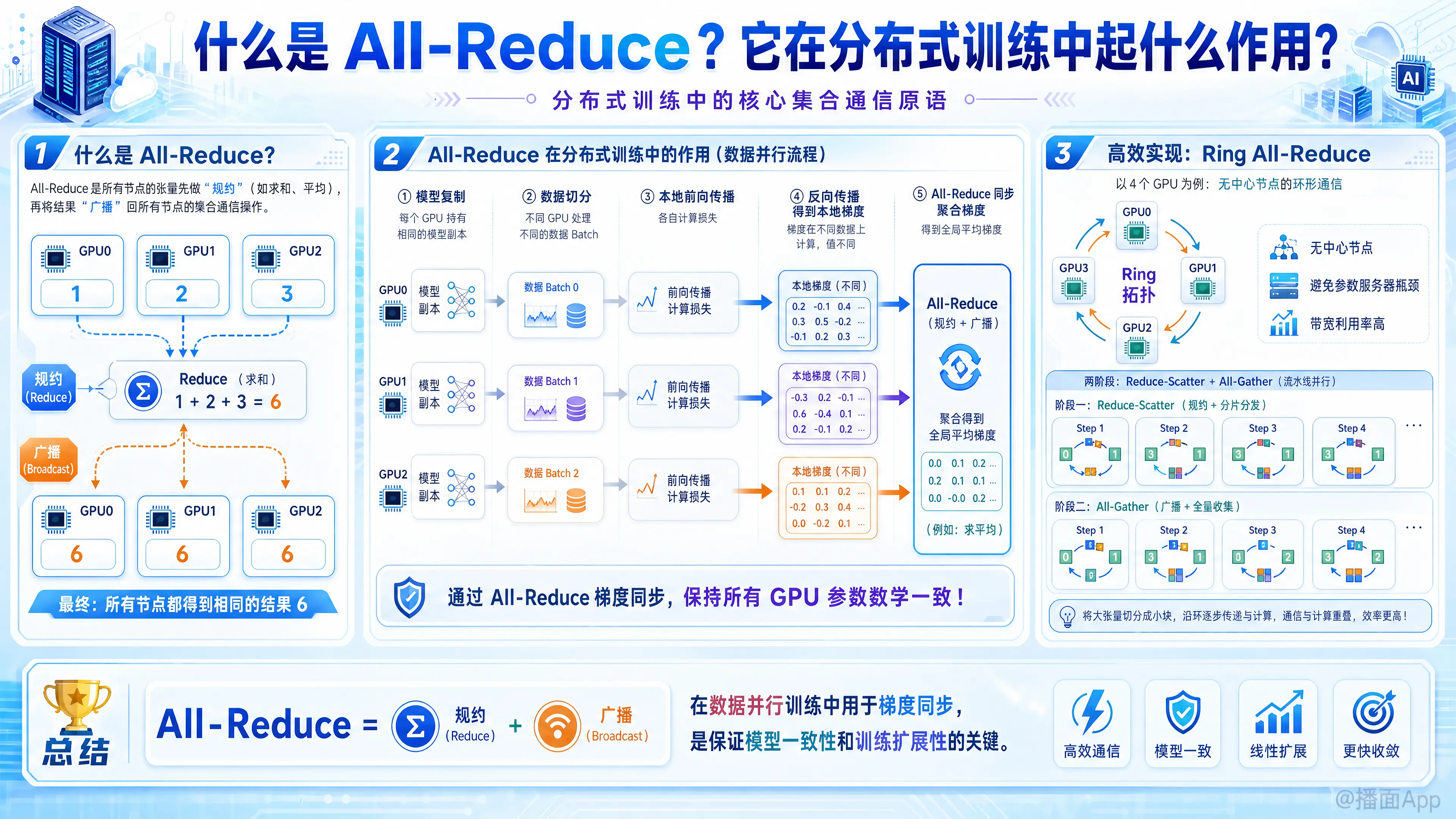
All-Reduce 是高性能计算(HPC)和分布式深度学习中非常核心的一个集合通信(Collective Communication)原语。
简单来说,它的作用是:将不同节点(GPU/机器)上的数据进行“规约”(比如求和、求平均),然后将结果“广播”给所有节点,使得所有节点最终都持有完全相同的结果。
下面我将从概念定义、在分布式训练中的作用、以及它是如何实现的三个方面为你详细解释。
1. 什么是 All-Reduce?
为了理解 All-Reduce,我们可以把它拆解为两个步骤(虽然实际算法通常是流水线进行的,不一定严格分步):
- Reduce(规约): 收集所有节点的数据,并进行某种运算(通常是 Sum 求和,也可以是 Max, Min, Product 等)。此时,结果只保存在某一个主节点上。
- Broadcast(广播): 将计算好的结果分发回所有的节点。
举个简单的例子(求和):
假设有 3 个 GPU,它们各自持有一个数值:
- GPU 0: 持有数据
1 - GPU 1: 持有数据
2 - GPU 2: 持有数据
3
执行 All-Reduce (Sum) 操作后:
- 计算过程:
1 + 2 + 3 = 6 - 最终状态:
- GPU 0: 持有数据
6 - GPU 1: 持有数据
6 - GPU 2: 持有数据
6
- GPU 0: 持有数据
2. All-Reduce 在分布式训练中起什么作用?
在深度学习中,All-Reduce 最主要的应用场景是 数据并行(Data Parallelism) 训练。
背景:数据并行是如何工作的?
当模型很大或者数据量很大时,单张 GPU 显存放不下或训练太慢,我们需要多张 GPU 一起练。
- 模型复制: 每一张 GPU 上都保存一份完全相同的模型副本(权重 Weights 一样)。
- 数据切分: 一个大的 Batch 数据被切分成几份(Micro-batches),分发给不同的 GPU。
- 前向/反向传播: 每张 GPU 根据自己分到的数据,独立计算 Loss,并计算出梯度(Gradients)。
问题:梯度不同步
因为每张 GPU 看到的训练数据不同,所以它们计算出的梯度也是不同的。
如果不做处理,直接用各自的梯度更新权重,那么不同 GPU 上的模型参数就会变得不一样,模型就“分裂”了,无法收敛。
All-Reduce 的作用:梯度同步
为了保证所有 GPU 上的模型始终一致,我们需要用所有数据的平均梯度来更新权重。这就是 All-Reduce 出场的时候:
- 收集梯度: 当所有 GPU 完成反向传播计算出本地梯度后,触发 All-Reduce 操作。
- 聚合梯度: All-Reduce 会将所有 GPU 上的梯度加起来(Sum)。
- 同步结果: All-Reduce 保证每张 GPU 最终都拿到了完全一样的梯度总和。
- 更新权重: 每张 GPU 拿着这个总和(通常除以 GPU 数量得到平均值),去更新自己的模型参数。
总结:All-Reduce 确保了在分布式训练的每一步迭代中,所有 GPU 都能获得全局视角的梯度信息,从而保持模型参数的数学一致性。
3. 它是如何高效实现的?(Ring All-Reduce)
如果只是简单地让所有 GPU 把数据发给一个“中央服务器”(Parameter Server),算完再发回来,那么这个中央服务器的带宽会成为巨大的瓶颈。
为了解决这个问题,工业界(如 NVIDIA 的 NCCL 库,百度的 DeepSpeech 等)通常采用 Ring All-Reduce(环状 All-Reduce) 算法。
Ring All-Reduce 的核心思想:
- 将 GPU 逻辑上连成一个环(Ring)。
- 没有中心节点,每个 GPU 只和它的左邻居和右邻居通信。
- Scatter-Reduce 阶段: 数据分块,在环里传递,每转一圈,每个 GPU 都会包含部分数据的最终和。
- All-Gather 阶段: 将计算好的部分和在环里再转一圈,让所有 GPU 得到完整的数据。
优势:
Ring All-Reduce 是带宽最优(Bandwidth Optimal)的算法。无论有多少个 GPU,每个 GPU 的通信量是恒定的(与 GPU 数量无关,只与数据量有关),这使得它非常适合大规模集群训练。
总结
- 是什么: 一种让所有节点协同计算并共享结果的通信操作。
- 干什么: 在分布式训练中,用于同步不同 GPU 上的梯度。
- 为什么重要: 它是现代大规模深度学习(如训练 GPT、Llama 等大模型)能够并行加速且保证模型收敛的基石。常用的库如 NVIDIA NCCL、MPI、Gloo 都在底层实现了它。