 播面
播面 Data Parallel、Model Parallel、Pipeline Parallel 的区别和适用场景
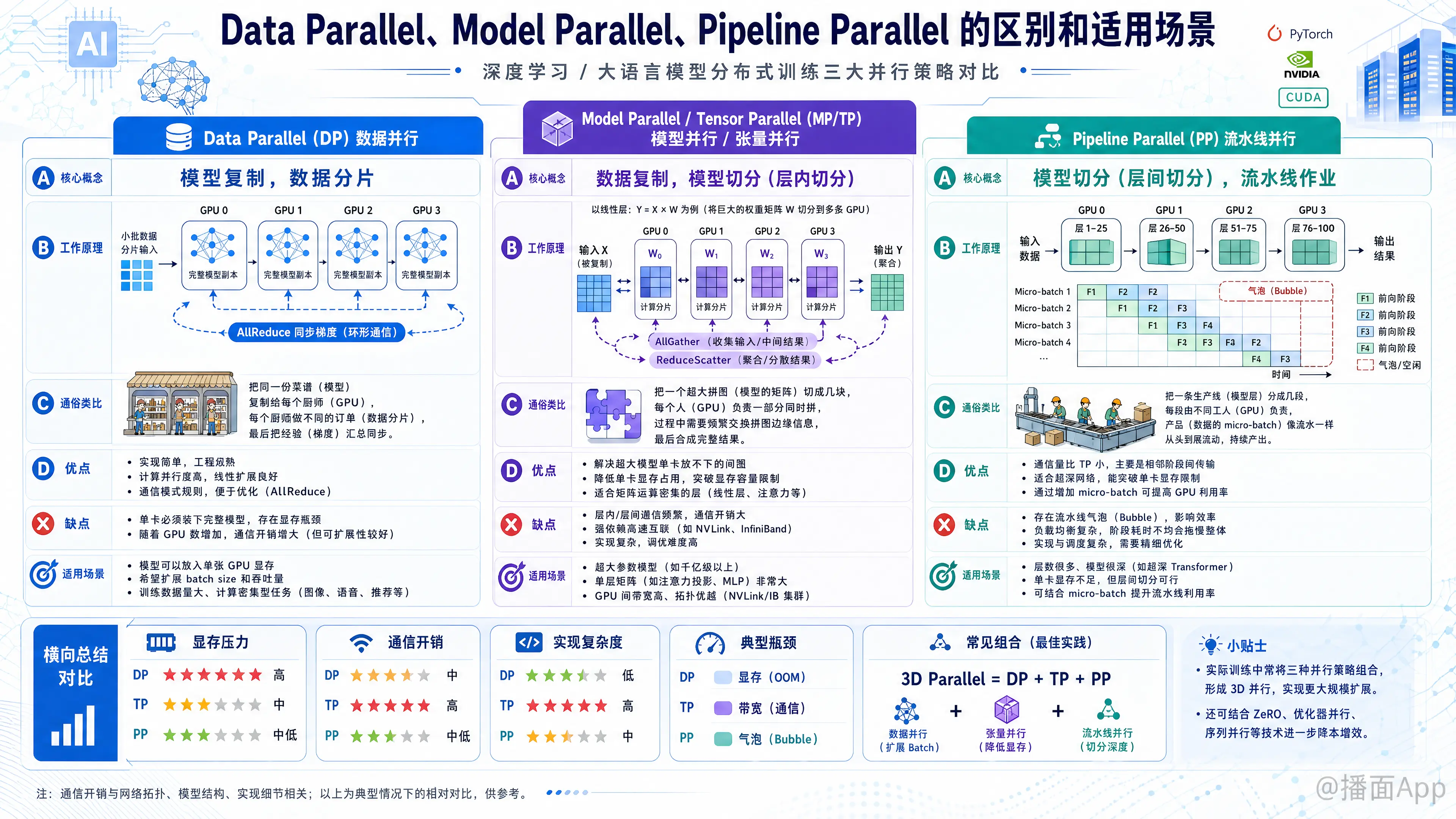
在深度学习(尤其是大语言模型 LLM)的训练中,单张 GPU 的显存和计算能力往往无法满足需求。为了解决这个问题,我们使用分布式训练技术。
Data Parallel (DP)、Model Parallel (MP) 和 Pipeline Parallel (PP) 是三种最主流的并行策略。
以下是它们的详细对比、工作原理及适用场景:
1. Data Parallel (DP) - 数据并行
核心概念: “模型复制,数据分片”。
原理:
- 假设你有 张 GPU。
- 模型复制: 每一张 GPU 上都保存一份完整的模型副本。
- 数据切分: 将一个 Batch 的数据切分成 份(Mini-batches),每张 GPU 处理一份不同的数据。
- 同步: 每张 GPU 独立计算梯度,然后通过通信(AllReduce)将所有 GPU 的梯度进行平均,最后更新所有 GPU 上的权重,保证下一轮迭代时大家的模型参数是一致的。
通俗类比:
老师(Server)发给 4 个学生(GPU)一模一样的课本(模型)。老师把 100 道题(Data)分成 4 份,每人做 25 道。做完后,大家把答案汇总,统一修正认知。优点: 实现简单,通信主要发生在反向传播之后(梯度同步),计算效率较高。
缺点: 显存瓶颈。每张卡必须能装下整个模型。如果模型大到单卡存不下,DP 就无法使用。
2. Model Parallel (MP) / Tensor Parallel (TP) - 模型并行/张量并行
注意:广义的 Model Parallel 包含 TP 和 PP,但通常狭义上指 Tensor Parallel (TP)。
核心概念: “数据复制,模型切分(层内切分)”。
原理:
- 当模型太大,单卡存不下时,我们将模型的某一层(Layer)的参数矩阵(Tensor)切开,分散到多张 GPU 上。
- 例如一个巨大的矩阵乘法 ,GPU1 计算 的上半部分,GPU2 计算 的下半部分。
- 通信: 在每一层的计算过程中,GPU 之间都需要频繁通信来合并结果(AllGather/ReduceScatter)。
通俗类比:
这道题太难了(矩阵太大),一个人算不过来。两个学生(GPU)坐在一起,你算前一半公式,我算后一半公式,每算一步我们都要对一下答案(通信),然后才能算下一步。优点: 解决了单卡存不下大模型的问题;减少了单卡的显存占用。
缺点: 通信开销极大。因为每一层计算都需要同步,所以要求 GPU 之间有极高带宽的连接(如 NVLink),否则通信会拖慢计算速度。
3. Pipeline Parallel (PP) - 流水线并行
核心概念: “模型切分(层间切分),流水线作业”。
原理:
- 将模型的不同层(Layers)分配给不同的 GPU。
- 例如:模型共 100 层,GPU1 负责第 1-25 层,GPU2 负责 26-50 层,以此类推。
- 数据从 GPU1 进去,算完后输出传给 GPU2,GPU2 接着算……直到 GPU4 输出结果。
- 气泡问题(Bubble): 朴素的 PP 会导致 GPU 空闲(GPU2 等 GPU1 时是闲着的)。为了解决这个问题,通常引入 Micro-batches,让数据像流水线一样源源不断地进入,减少空闲时间。
通俗类比:
汽车组装流水线。工人 A(GPU1)装轮胎,传给工人 B(GPU2)装车门。A 装完一个轮胎马上装下一辆车的轮胎,不需要等 B 装完车门。优点: 通信量比 TP 小很多(只在 GPU 边界传输 Activation),适合跨节点(不同机器之间)的模型并行。
缺点: 实现复杂;存在“流水线气泡”(Bubble),即在启动和结束阶段总有 GPU 在空转,无法达到 100% 利用率。
总结对比表
| 特性 | Data Parallel (DP) | Tensor Parallel (TP) | Pipeline Parallel (PP) |
|---|---|---|---|
| 切分对象 | 切分数据 (Batch) | 切分模型参数 (Tensor/Layer内) | 切分模型层数 (Layer间) |
| 模型副本 | 每卡一份完整模型 | 多卡拼成一个完整层 | 多卡拼成一个完整模型 |
| 单卡显存压力 | 高 (需存完整模型) | 低 (存部分参数) | 低 (存部分层) |
| 通信频率 | 低 (仅在反向传播后) | 极高 (每层都要通信) | 中 (层与层交界处通信) |
| 通信量 | 大 (传输梯度) | 极大 (传输中间结果) | 小 (传输激活值) |
| 硬件要求 | 通用网络即可 | 需高带宽 (NVLink) | 通用网络或机内互联 |
| 主要瓶颈 | 显存容量 | 通信带宽 | 流水线气泡 (空闲时间) |
适用场景指南
模型较小,单卡能装下:
- 首选:Data Parallel (DP/DDP)。
- 这是最快、最高效的方法。增加 GPU 数量可以直接增加 Batch Size,加快训练速度。
模型较大,单卡装不下,但显存超出的不多:
- 首选:Pipeline Parallel (PP) 或 ZeRO (一种优化的 DP)。
- PP 适合在节点之间(不同服务器)进行模型切分,因为通信量较小。
模型极大(如 GPT-3, Llama 70B+),单卡完全装不下:
- 必须使用混合并行(3D Parallelism)。
- 通常的组合策略是:
- 节点内(Intra-node): 使用 Tensor Parallel (TP)。因为同一台机器内的 GPU 有 NVLink,带宽极高,能承受 TP 的频繁通信。
- 节点间(Inter-node): 使用 Pipeline Parallel (PP)。因为跨机器网络带宽较低,PP 通信少。
- 数据层面: 在上述切分好的“虚拟大 GPU”组之间,再套用 Data Parallel (DP) 来通过更多数据加速训练。
一句话总结选择策略:
能用 DP 就用 DP;存不下就先切层(PP);还不够快或者层内计算太大就切张量(TP);超级大模型就三个一起上(3D并行)。