 播面
播面 AI Infra 中常见的 SLA / SLO 指标有哪些?
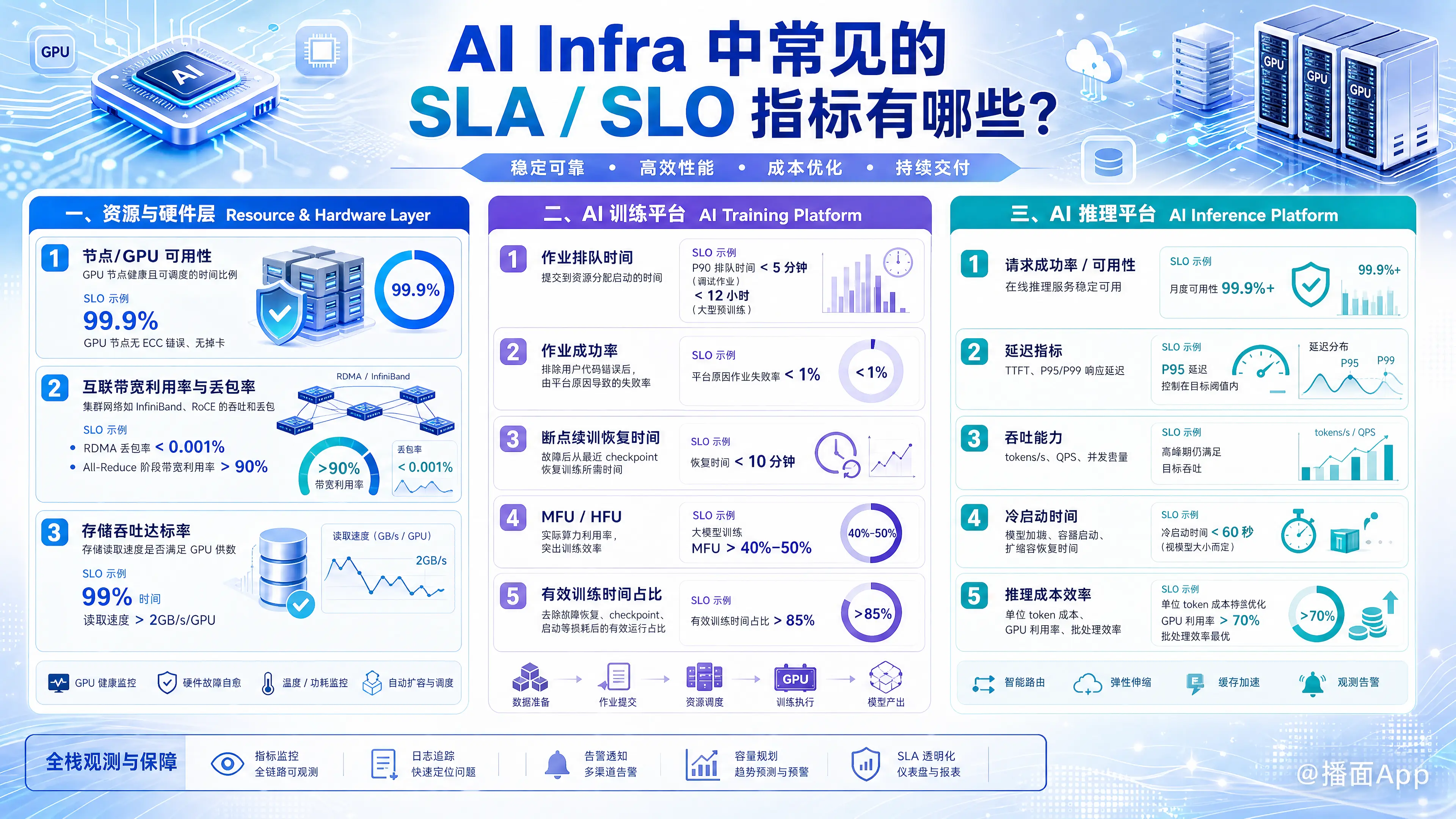
在构建和维护 AI Infrastructure(AI 基础设施)时,由于其负载特性(高并发计算、大吞吐数据、长周期任务)与传统 Web 服务不同,SLA (Service Level Agreement) 和 SLO (Service Level Objective) 的关注点也有显著差异。
AI Infra 通常分为两大场景:训练 (Training) 和 推理 (Inference)。以下是这两个场景及底层资源层常见的 SLA/SLO 指标:
一、 资源与硬件层 (Resource & Hardware Layer)
这是 AI Infra 的基石,主要关注 GPU/TPU 集群的健康度和利用率。
节点/GPU 可用性 (Node/GPU Availability)
- 定义: GPU 节点处于健康状态且可被调度的时间比例。
- 关键点: AI 训练对硬件故障非常敏感。
- SLO 示例: 99.9% 的 GPU 节点无 ECC 错误、无掉卡现象。
互联带宽利用率与丢包率 (Interconnect Bandwidth & Packet Loss)
- 定义: 集群内部网络(如 InfiniBand, RoCE)的实际吞吐量和丢包情况。
- 关键点: 分布式训练中,网络往往是瓶颈。丢包会导致 NCCL 通信卡死。
- SLO 示例: RDMA 网络丢包率 < 0.001%,带宽利用率 > 90% (在 All-Reduce 阶段)。
存储吞吐达标率 (Storage Throughput Compliance)
- 定义: 存储系统能否满足 GPU 读取数据的速度(避免 GPU Starvation)。
- SLO 示例: 99% 的时间内,读取速度 > 2GB/s/GPU。
二、 AI 训练平台 (AI Training Platform)
训练任务通常是离线、长周期(数天到数月)的批处理作业。
作业排队时间 (Job Queueing Time / Pending Time)
- 定义: 任务提交后到实际分配到资源开始运行的时间。
- 关键点: 影响算法工程师的迭代效率。
- SLO 示例: P90 排队时间 < 5 分钟(对于调试作业);< 12 小时(对于大型预训练作业)。
作业成功率 (Job Success Rate)
- 定义: 排除用户代码错误(User Error),由平台或基础设施原因(如节点宕机、网络中断)导致的作业失败率。
- SLO 示例: 平台自身原因导致的作业失败率 < 1%。
断点续训恢复时间 (Checkpoint/Restore Time)
- 定义: 发生故障后,从最近的 Checkpoint 恢复训练所需的时间。
- 关键点: 大模型 Checkpoint 巨大(TB 级),加载慢会浪费昂贵的算力。
- SLO 示例: 恢复时间 < 10 分钟。
MFU (Model FLOPS Utilization) / HFU (Hardware FLOPS Utilization)
- 定义: 实际算力利用率。MFU 是衡量训练效率的核心指标。
- 关键点: 买了 H100 卡,如果 MFU 只有 20% 就是巨大的浪费。
- SLO 示例: 大模型训练 MFU > 40% - 50%。
有效训练时间占比 (Effective Training Time Ratio)
- 定义: (总运行时间 - 故障恢复时间 - Checkpoint时间 - 启动时间) / 总运行时间。
- SLO 示例: > 95%。
三、 AI 推理平台 (AI Inference / Serving)
推理服务通常是由于用户触发的在线服务,对延迟极其敏感。对于 LLM(大语言模型),指标更加特殊。
通用推理指标:
端到端延迟 (End-to-End Latency)
- 定义: 从请求到达网关到返回结果的时间。
- SLO 示例: P99 Latency < 200ms (对于传统 CV/NLP 模型)。
服务可用性 (Service Availability)
- 定义: 请求成功响应的比例(排除 4xx 错误,关注 5xx 错误)。
- SLO 示例: 99.95% 或 99.99%。
模型冷启动时间 (Model Cold Start Time)
- 定义: 在 Serverless 场景下,从 0 副本到加载模型并服务第一个请求的时间。
- SLO 示例: < 5秒 (取决于模型大小,大模型通常需要预热)。
LLM (大模型) 专用指标 (GenAI 特有):
TTFT (Time To First Token)
- 定义: 用户发出请求到看到第一个生成的字符的时间。
- 关键点: 直接决定用户的“体感速度”。
- SLO 示例: P90 TTFT < 1.5 秒。
TPOT (Time Per Output Token) / Inter-token Latency
- 定义: 生成每一个后续 Token 的平均间隔时间。
- 关键点: 决定了文字生成的“流畅度”。如果比人类阅读速度慢,体验就很差。
- SLO 示例: < 50ms / token (即每秒生成 20 个 token 以上)。
吞吐量 (Throughput - Tokens per Second)
- 定义: 系统每秒能处理的总 Token 数(Prompt Token + Generation Token)。
- 关键点: 衡量系统负载能力和成本效益。
四、 数据与开发环境 (Data & Dev Environment)
- 开发机启动成功率与速度
- Notebook (Jupyter) 实例启动时间 < 2分钟。
- 镜像拉取速度 (Image Pulling Speed)
- AI 镜像通常很大(10GB+),P90 拉取速度应满足一定阈值,通常利用 P2P 加速。
总结:SLA 仪表盘示例
| 领域 | 关键指标 (Metric) | 典型 SLO (参考) | 业务影响 |
|---|---|---|---|
| Infra (硬件) | GPU 节点健康率 | > 99.8% | 训练中断频率 |
| Training (训练) | MFU (算力利用率) | > 45% (LLM) | 训练成本、模型上线周期 |
| Training (训练) | 作业排队时间 | P90 < 10min (调试) | 算法工程师生产力 |
| Inference (推理) | TTFT (首字延迟) | P95 < 800ms | 用户流失率 |
| Inference (推理) | Token 生成速度 | > 30 tokens/s | 用户阅读体验 |
| Inference (推理) | 错误率 (Error Rate) | < 0.1% | 服务可靠性 |
在制定 SLA 时,Training 侧更看重吞吐量和资源效率(省钱、跑得快),而 Inference 侧更看重延迟和稳定性(用户体验)。