 播面
播面 训练系统和推理系统在设计目标上有哪些本质差异?
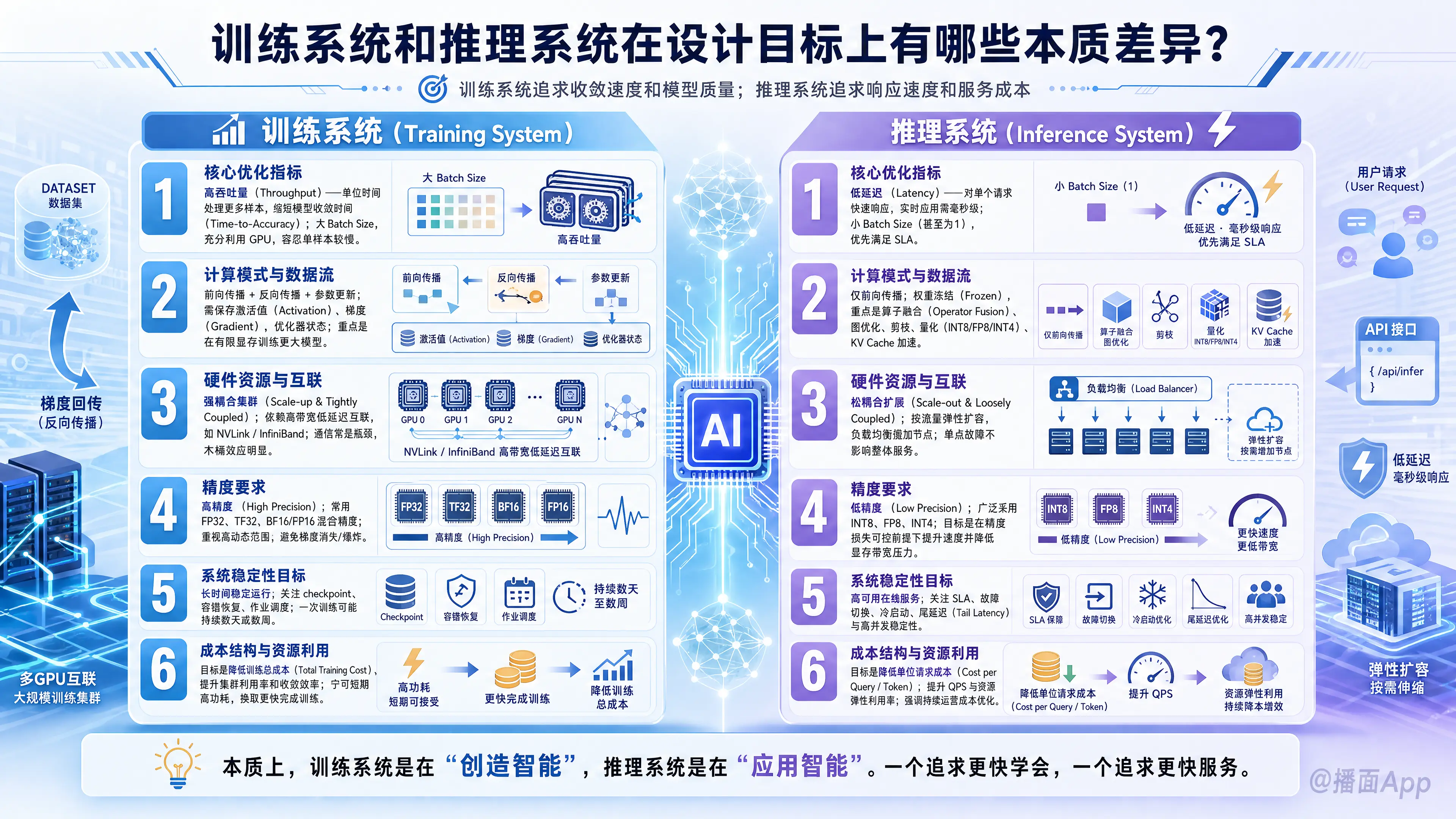
训练系统(Training System)和推理系统(Inference System)虽然都基于深度学习模型和底层算力,但由于它们处于AI生命周期的不同阶段,其核心设计目标存在本质差异。
简单来说:训练系统是为了“创造”智能,追求的是收敛速度和模型质量;推理系统是为了“应用”智能,追求的是响应速度和服务成本。
以下是两者在设计目标上的六大本质差异:
1. 核心优化指标:吞吐量 vs. 延迟 (Throughput vs. Latency)
- 训练系统:追求高吞吐量(Throughput)
- 目标: 在单位时间内处理尽可能多的数据样本,以缩短“模型收敛时间”(Time-to-Accuracy)。
- 设计: 倾向于使用极大的Batch Size(批大小),以充分填满GPU的计算单元,掩盖内存访问延迟。系统设计容忍单个样本处理慢一点,只要整体处理量大即可。
- 推理系统:追求低延迟(Latency)
- 目标: 对用户的单个请求做出最快的响应。对于实时应用(如自动驾驶、语音助手),延迟必须控制在毫秒级(如<10ms)。
- 设计: 往往使用很小的Batch Size(甚至为1)。系统必须优化关键路径,减少任何不必要的开销。虽然也关注吞吐量(QPS),但前提是必须满足SLA(服务等级协议)的延迟要求。
2. 计算模式与数据流:迭代更新 vs. 单向传递
- 训练系统:前向+反向传播+参数更新
- 特征: 计算极其复杂。需要保存前向传播的中间激活值(Activation),用于反向传播计算梯度(Gradient),最后更新权重。
- 设计目标: 内存容量管理是核心。显存不仅要存模型参数,还要存梯度、优化器状态和巨大的中间激活值。设计重点在于如何在有限显存下训练更大的模型(如使用ZeRO、Gradient Checkpointing)。
- 推理系统:仅前向传播
- 特征: 权重是冻结的(Frozen)。不需要计算梯度,不需要反向传播。
- 设计目标: 极致的算子融合(Operator Fusion)和图优化。设计重点在于如何剪枝、量化(Quantization,如从FP32降到INT8)以减少计算量和显存占用,同时利用KV Cache(针对Transformer模型)来加速生成。
3. 硬件资源与互联:强耦合 vs. 弹性伸缩
- 训练系统:强耦合集群(Scale-up & Tightly Coupled)
- 目标: 多个GPU/节点之间需要频繁同步巨大的梯度数据。
- 设计: 极度依赖高带宽、低延迟的互联技术(如NVLink, InfiniBand)。网络通信往往是瓶颈。设计目标是让成千上万张卡像一张卡一样协同工作,任何一个节点的慢都会拖累整体(木桶效应)。
- 推理系统:松耦合扩展(Scale-out & Loosely Coupled)
- 目标: 根据用户流量动态调整资源。
- 设计: 节点之间通常不需要通信(除非是超大模型需要张量并行)。设计目标是弹性(Elasticity)。可以通过负载均衡器简单地增加服务器数量来应对流量高峰,且单个节点的故障不会导致服务中断。
4. 精度要求:高动态范围 vs. 够用即可
- 训练系统:高精度(High Precision)
- 目标: 防止梯度消失或爆炸,确保模型能学到细微的特征。
- 设计: 通常使用 FP32、TF32 或 BF16/FP16 混合精度。硬件设计必须支持高动态范围的数值计算。
- 推理系统:低精度(Low Precision)
- 目标: 减少显存占用和内存带宽压力,提升计算速度。
- 设计: 广泛采用 INT8、FP8 甚至 INT4 量化。设计目标是在不显著损失模型精度(Accuracy)的前提下,最大化压缩模型体积和计算量。
5. 成本结构:一次性投入 vs. 持续运营成本
- 训练系统:关注资源利用率(Utilization)
- 目标: 训练通常是离线作业,成本高昂(数百万美元)。
- 设计: 目标是让昂贵的GPU 24小时满负荷运转(100%利用率)。如果GPU空转,就是巨大的浪费。
- 推理系统:关注性价比(Cost-Efficiency / TCO)
- 目标: 推理是7x24小时的在线服务。
- 设计: 关注“每美元能处理多少查询”(Queries per Dollar)。由于流量有波峰波谷,推理系统往往面临资源利用率不足的问题,因此设计上更看重多租户隔离、Serverless架构以及在低流量时的节能能力。
6. 可靠性与容错:检查点恢复 vs. 高可用性
- 训练系统:Checkpointing(断点续训)
- 设计: 训练任务可能持续数周。如果节点故障,系统设计目标是回滚到最近的存档点(Checkpoint)继续训练,允许中断几分钟进行恢复。
- 推理系统:High Availability(高可用)
- 设计: 面向最终用户,不能容忍服务中断。设计目标是冗余和快速故障转移(Failover)。如果一个节点挂了,流量必须毫秒级切换到健康节点。
总结对比表
| 特征 | 训练系统 (Training) | 推理系统 (Inference) |
|---|---|---|
| 核心目标 | 模型收敛质量、训练速度 | 响应延迟、吞吐量、成本 |
| 计算过程 | 前向 + 反向 + 权重更新 | 仅前向传播 (Forward Only) |
| 数据处理 | 固定数据集,多轮迭代 (Epochs) | 实时流数据,一次性处理 |
| 关键瓶颈 | 算力、显存容量、节点间通信带宽 | 内存带宽 (Memory Bandwidth)、延迟 |
| 精度偏好 | FP32, BF16 (高动态范围) | INT8, FP16, FP8 (量化) |
| 扩展方式 | 紧耦合 (通信密集型) | 松耦合 (易于水平扩展) |
| SLA要求 | 关注作业完成时间 | 关注 P99 延迟、可用性 |