 播面
播面 什么是 AI Infra?它与传统后端基础设施的核心区别是什么?
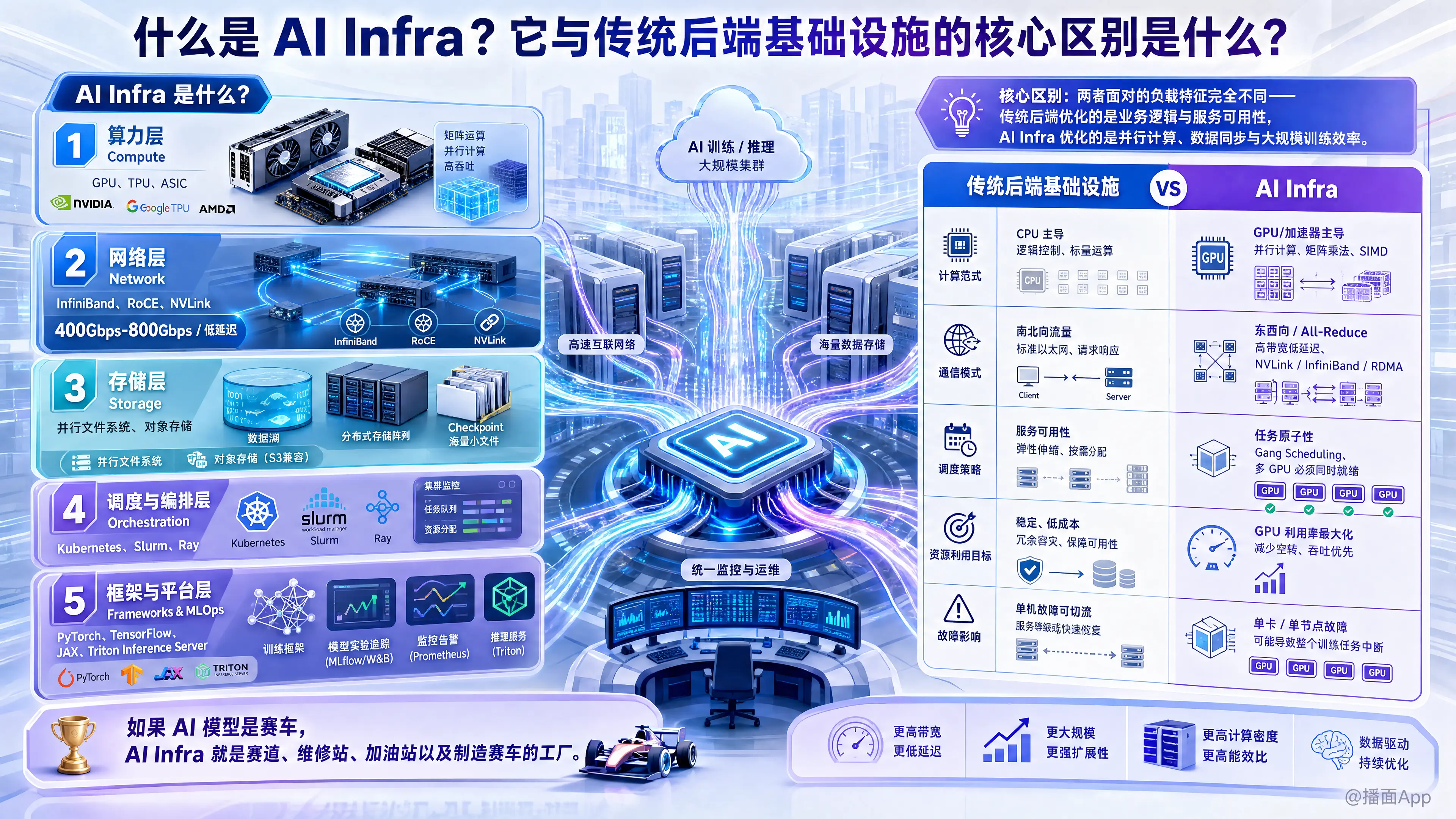
AI Infra(人工智能基础设施) 是指为了支持人工智能(AI)和机器学习(ML)模型的全生命周期(从数据处理、模型开发、训练到推理部署)而构建的底层硬件、软件平台及工具链的总和。
简单来说,如果 AI 模型是“赛车”,那么 AI Infra 就是“赛道、维修站、加油站以及制造赛车的工厂”。
随着大语言模型(LLM)和生成式 AI 的爆发,AI Infra 已经成为科技界最热门的领域之一。
一、 AI Infra 包含什么?
AI Infra 通常可以分为以下几个层级:
- 算力层(Compute):
- 核心: GPU(NVIDIA H100/A100)、TPU(Google)、ASIC(专用芯片)。
- 特点: 极高的并行计算能力,用于处理矩阵运算。
- 网络层(Network):
- 核心: InfiniBand (IB)、RoCE、NVLink。
- 特点: 极高带宽(400Gbps-800Gbps)、极低延迟,用于多卡、多机之间的数据同步。
- 存储层(Storage):
- 核心: 高性能并行文件系统(如 Lustre, GPFS, JuiceFS),对象存储。
- 特点: 需要支持海量小文件的随机读取(数据加载)和超大文件的快速写入(模型 Checkpoint 保存)。
- 调度与编排层(Orchestration):
- 核心: Kubernetes (K8s), Slurm, Ray。
- 特点: 管理成百上千张 GPU 的资源分配,处理任务调度。
- 框架与平台层(Frameworks & MLOps):
- 核心: PyTorch, TensorFlow, JAX, Triton Inference Server。
- 工具: 模型监控、特征存储、实验管理。
二、 AI Infra 与传统后端基础设施的核心区别
传统后端(Web 服务、微服务、数据库)与 AI Infra 的核心区别在于负载特征(Workload Characteristics)完全不同。
以下是五个维度的深度对比:
1. 计算范式:逻辑控制 vs. 并行计算
- 传统后端:
- CPU 主导: 处理复杂的业务逻辑、分支判断、I/O 等待。
- 任务特征: 主要是标量运算,追求单核性能和逻辑处理能力。
- AI Infra:
- GPU/加速器主导: 处理大规模矩阵乘法(Matrix Multiplication)。
- 任务特征: SIMD(单指令多数据流)。成千上万个核心同时做相同的数学运算。CPU 在这里主要充当“监工”,负责给 GPU 喂数据。
2. 通信模式:南北向流量 vs. 东西向流量
- 传统后端:
- 请求/响应模式: 用户请求进来(南北向),服务间调用(东西向),但数据包通常较小。
- 网络要求: 标准以太网(TCP/IP)即可满足,对微秒级延迟不敏感。
- AI Infra(特别是分布式训练):
- All-Reduce 模式: 在训练大模型时,成百上千个 GPU 需要在每一轮迭代中同步梯度参数。
- 网络要求: 极度依赖高带宽和低延迟。如果网络慢,昂贵的 GPU 就会空转等待数据。因此需要 NVLink(卡间互联)和 InfiniBand/RDMA(机间互联),网络成为了木桶效应中最短的那块板。
3. 调度策略:服务可用性 vs. 任务原子性 (Gang Scheduling)
- 传统后端:
- 弹性伸缩: 如果一个 Web 服务器挂了,负载均衡器会把流量切给别的服务器,服务依然可用。
- 独立调度: 容器可以逐个启动。
- AI Infra:
- Gang Scheduling(全组调度): 训练一个大模型可能需要 1000 张卡。这 1000 张卡必须同时就绪才能开始任务。如果其中 1 张卡挂了或没资源,整个训练任务就会失败或暂停。
- 拓扑感知: 调度器必须知道物理拓扑结构,尽量把需要频繁通信的 GPU 分配在同一个交换机下,以减少网络跳数。
4. 存储压力:事务处理 vs. 吞吐量轰炸
- 传统后端:
- 模式: 数据库的增删改查(ACID),注重 IOPS(每秒读写次数)和数据一致性。
- AI Infra:
- 读压力: 训练开始时,需要从存储中以极高速度读取海量数据集(可能是数 TB 的图片或文本)。
- 写压力(Checkpointing): 训练过程中,需要定期保存模型状态(Checkpoint)。对于千亿参数模型,一次保存可能涉及数百 GB 数据,必须在几秒内写完,否则会阻塞训练,浪费昂贵的算力。
5. 容错与恢复:无状态 vs. 有状态断点续训
- 传统后端:
- 无状态(Stateless): 服务挂了重启即可,不丢失数据(数据在 DB 里)。
- AI Infra:
- 极其脆弱: 训练任务可能持续几周。如果硬件故障(GPU 烧了、网络断了),不能从头开始,必须从最近的 Checkpoint 恢复(断点续训)。
- 故障检测: 需要比传统监控更敏锐的硬件健康检查(如检测 GPU 的 ECC 错误、NVLink 降速等),甚至需要预测性维护。
总结
- 传统后端 Infra 的目标是:高并发、高可用、低延迟(针对用户请求)。 它是为了让数百万用户同时访问 App 而设计的。
- AI Infra 的目标是:高吞吐、高利用率、极致的并行效率。 它是为了让成千上万个昂贵的芯片像一个超级大脑一样协同工作而设计的。