 播面
播面 Kafka生产者工作流程深度解析
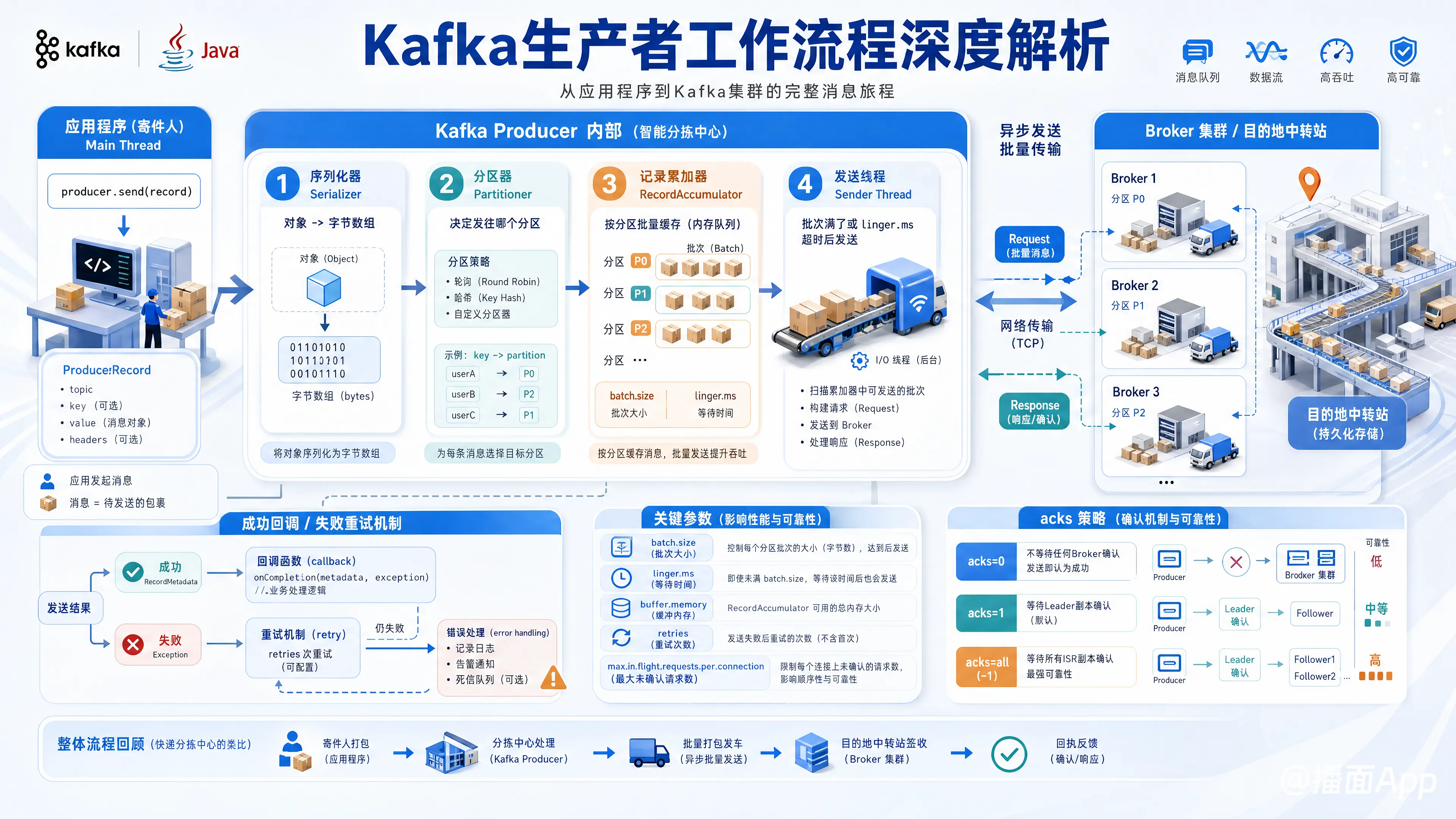
此文讲解了Kafka生产者的完整流程:消息经序列化、分区后,在内存中批量缓存,再异步发送至Broker。Broker根据acks策略确认,生产者最终处理成功回调或失败重试。
我们来详细分解一下 Kafka 生产者的整个工作流程。
这个流程可以分为两个主要部分:生产者内部的工作流程和与 Broker 的交互流程。
我会用一个“快递分拣中心”的比喻来帮助理解。你的应用程序是“寄件人”,消息是“包裹”,Kafka Producer 是“快递分拣中心”,Broker 是“目的地中转站”。
核心流程图
plaintext
+---------------------+
应用程序 (Main Thread) | producer.send(record) |
+----------+----------+
|
v
+--------------------------------------------------------------------------+
| Kafka Producer 内部 |
| |
| +-------------------+ +------------------+ +----------------------+ |
| | 1. 序列化器 |-->| 2. 分区器 |-->| 3. 记录累加器 | |
| | (Serializer) | | (Partitioner) | | (RecordAccumulator) | |
| +-------------------+ +------------------+ +----------+-----------+ |
| (对象 -> 字节数组) (决定发往哪个分区) (按分区批量缓存) |
| | |
| | (批次满了或超时) |
| v |
| +---------+----------+ |
| | 4. 发送线程 | |
| | (Sender Thread) | |
| +--------------------+ |
| |
+--------------------------------------------------------------------------+
|
| (网络请求)
v
+--------------------------------------------------------------------------+
| Kafka Broker (集群) |
| |
| +-------------------+ +------------------+ +----------------------+ |
| | Leader Broker 接收 |-->| 写入本地 Log 文件 |-->| 等待 Follower 同步 | |
| +-------------------+ +------------------+ +----------------------+ |
| (根据 acks 设置) |
| |
+--------------------------------------------------------------------------+
|
| (响应 Response)
v
+--------------------------------------------------------------------------+
| Kafka Producer 内部 |
| |
| +--------------------+ |
| | 发送线程处理响应 | |
| +----------+---------+ |
| | |
| (成功) ------------------+------------------ (失败) |
| v v |
| +----------------+ +-----------------------+ |
| | 调用 Callback | | 进行重试 (Retries) | |
| | 或完成 Future | | 或 报告最终错误 | |
| +----------------+ +-----------------------+ |
| |
+--------------------------------------------------------------------------+详细步骤分解
第一部分:生产者内部流程 (Main Thread & Sender Thread)
当你的应用程序调用 producer.send(record) 方法时,这个调用通常是异步的,会立即返回。真正的工作在后台进行。
1. 拦截器 (Interceptors) - 可选
在消息处理的最开始,生产者可以配置一些拦截器。你可以在这里对消息进行修改、记录日志或进行监控,然后再交给序列化器。
2. 序列化器 (Serializer)
- 作用:Kafka 只接受字节数组(
byte[])格式的消息。序列化器负责将你创建的ProducerRecord对象中的key和value(它们可以是任何 Java 对象,如 String, Integer, 自定义对象等)转换成字节数组。 - 配置:通过
key.serializer和value.serializer参数指定。例如:org.apache.kafka.common.serialization.StringSerializer。 - 比喻:将你的“包裹”打包成标准尺寸的箱子,贴上标准格式的地址标签。
3. 分区器 (Partitioner)
- 作用:决定这条消息应该被发送到 Topic 的哪一个分区(Partition)。一个 Topic 通常有多个分区,合理的分区可以实现负载均衡。
- 分区策略:
- 指定分区:如果你在
ProducerRecord中明确指定了分区号,分区器将直接使用该分区。 - 有 Key,无指定分区:分区器会对 Key 进行哈希计算(默认使用 Murmur2 算法),然后根据哈希值映射到一个分区。关键点:相同的 Key 总是会被发送到同一个分区,这保证了消息的局部有序性。
- 无 Key,无指定分区:
- 老版本:采用轮询(Round-Robin)策略,依次将消息发送到每个可用分区。
- 新版本(Sticky Partitioning 粘性分区):为了提高性能,生产者会选择一个分区并“粘”住它,在一段时间内(或一个批次内)将消息都发送到这个分区。当这个分区的批次满了或者
linger.ms时间到了,再选择下一个分区并“粘”住。这样做可以减少网络请求次数,提高吞吐量。
- 指定分区:如果你在
- 比喻:分拣员根据包裹上的“目的地邮编”(Key)或者“加急”标签(指定分区),决定把它放到发往北京、上海还是广州的卡车上。如果没有特定信息,就先填满一辆卡车再说。
4. 记录累加器 (RecordAccumulator)
- 作用:这是生产者内部的一块内存缓冲区(由
buffer.memory参数控制大小),用于将消息进行批量处理(Batching)。 - 工作方式:
- 分区器确定分区后,消息不会立即被发送,而是被放入累加器中。
- 累加器会为每个 Topic-Partition 维护一个双端队列(Deque),队列中存放着一个个的
ProducerBatch。 - 新来的消息会被追加到对应分区的最后一个
ProducerBatch中。如果最后一个批次满了,或者没有批次,就会创建一个新的ProducerBatch。
- 比喻:这是快递中心的“待发货区”。来自不同寄件人的、发往同一个城市(分区)的包裹,会被放在同一个货运托盘(Batch)上,等托盘装满了再一起装车。
5. 发送线程 (Sender Thread)
- 作用:这是一个独立的后台线程,是真正负责网络通信的“工人”。
- 工作方式:
- Sender 线程不断地从 RecordAccumulator 中拉取“准备好”的
ProducerBatch。 - 何时“准备好”?
- 一个批次的大小达到了
batch.size。 - 距离该批次第一条消息的创建时间超过了
linger.ms。 producer.flush()或producer.close()被调用。- 累加器内存不足。
- 一个批次的大小达到了
- Sender 线程会将发往同一个 Broker 的多个批次(可能来自不同分区)组合成一个网络请求(Request),一次性发送出去,以减少网络开销。
- Sender 线程不断地从 RecordAccumulator 中拉取“准备好”的
- 比喻:装卸工(Sender Thread)看到某个城市的托盘(Batch)满了,或者等待时间太长了,就把这个托盘以及其他发往同一个中转站(Broker)的托盘一起装上卡车(Request),然后发车。
第二部分:与 Broker 的交互流程
6. Broker 接收与处理
- Leader 副本处理:网络请求会直接发送到目标分区的 Leader 副本所在的 Broker。
- 写入 Log:Leader Broker 验证请求后,将消息以追加(Append)的方式写入到本地磁盘的 Log 文件中。
- 同步给 Follower:Leader Broker 会通知该分区的所有 ISR (In-Sync Replicas, 同步副本集) 中的 Follower 副本前来拉取数据。
7. Broker 发送响应 (ACK)
- 核心配置
acks:这个参数决定了生产者认为“发送成功”的标准,直接影响了数据的可靠性和延迟。acks=0(不等待响应): 生产者发送后不等待任何来自 Broker 的确认。速度最快,但可靠性最低,可能丢数据(例如 Broker 宕机)。acks=1(默认值,等待 Leader 确认): 只要 Leader 副本成功写入 Log,就会返回成功响应给生产者。性能和可靠性的良好平衡。如果在 Follower 同步完成前 Leader 宕机,数据可能会丢失。acks=all或acks=-1(等待所有 ISR 确认): Leader 副本写入 Log 后,还会等待所有 ISR 列表中的 Follower 副本都同步完成,才返回成功响应。可靠性最高,但延迟也最大,保证了数据至少被写入了多个副本,不会丢失。
8. 生产者处理响应
- 成功:如果 Sender 线程收到了 Broker 的成功响应,它会从 RecordAccumulator 中移除这个已发送的批次,并释放内存。如果用户在调用
send()方法时提供了Callback,此时会调用Callback的onCompletion()方法,通知应用程序发送成功。 - 失败(可重试):如果遇到的是临时性错误(如网络抖动、Leader 选举),Sender 线程会根据
retries配置进行自动重试。- 幂等性 (
enable.idempotence=true): 开启此项后,即使重试导致消息被发送多次,Broker 也只会接收并写入一次,从而避免了数据重复问题(保证单分区单会话内的精准一次性)。
- 幂等性 (
- 失败(不可重试):如果遇到的是无法恢复的错误(如消息太大、序列化失败),生产者会直接放弃,并通过
Callback或Future将异常报告给应用程序。
总结
整个流程可以概括为:
- 应用程序调用
send(),这是一个异步操作。 - 消息在生产者内部经过序列化和分区。
- 消息被存入内存缓冲区 (RecordAccumulator),等待成批。
- 后台 Sender 线程在满足条件(批次大小或超时)时,将批次数据打包成请求发送给对应的 Broker Leader。
- Broker Leader 写入本地日志,并根据
acks设置等待 Follower 同步。 - Broker 返回响应给生产者。
- Sender 线程处理响应,成功则通知应用,失败则根据情况重试或报告错误。