 播面
播面 Pod 的健康检查机制(LivenessProbe, ReadinessProbe, StartupProbe)的区别
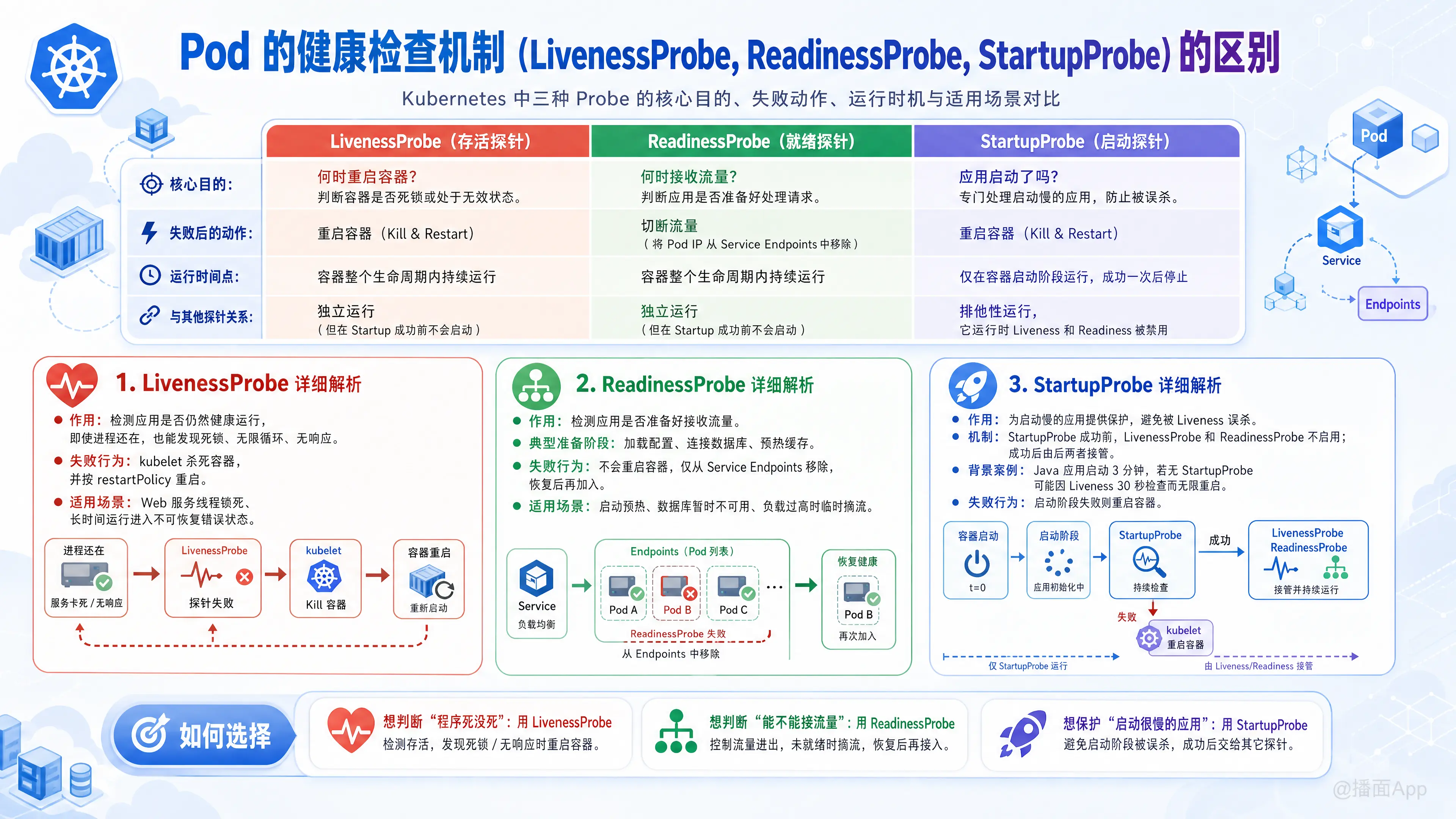
在 Kubernetes 中,Pod 的健康检查(Health Check)是通过 Probes(探针) 来实现的。这三种探针(Liveness, Readiness, Startup)虽然配置方式相似(都支持 HTTP、TCP、Exec 等检测方式),但它们的目的、触发后的行为以及适用场景截然不同。
以下是它们的详细区别与对比:
1. 核心区别总结
| 特性 | LivenessProbe (存活探针) | ReadinessProbe (就绪探针) | StartupProbe (启动探针) |
|---|---|---|---|
| 核心目的 | 何时重启容器? 判断容器是否死锁或处于无效状态。 |
何时接收流量? 判断应用是否准备好处理请求。 |
应用启动了吗? 专门处理启动慢的应用,防止被误杀。 |
| 失败后的动作 | 重启容器 (Kill & Restart)。 | 切断流量 (将 Pod IP 从 Service 的 Endpoints 中移除)。 | 重启容器 (Kill & Restart)。 |
| 运行时间点 | 容器整个生命周期内持续运行。 | 容器整个生命周期内持续运行。 | 仅在容器启动阶段运行,成功一次后就停止。 |
| 与其他探针关系 | 独立运行(但在 Startup 成功前不会启动)。 | 独立运行(但在 Startup 成功前不会启动)。 | 排他性:它运行时,Liveness 和 Readiness 均被禁用。 |
2. 详细解析
A. LivenessProbe (存活探针)
- 作用:检测应用程序是否正在运行。如果应用进程还在,但内部出现了死锁(Deadlock)或无限循环,无法响应,LivenessProbe 会检测到失败。
- 失败行为:Kubernetes 的 kubelet 会杀死该容器,并根据 Pod 的
restartPolicy(通常是 Always)来重启它。 - 适用场景:
- 应用程序长时间运行后可能进入无法恢复的错误状态。
- 例如:一个 Web 服务进程还在,但所有线程都被锁死,无法处理任何请求。
B. ReadinessProbe (就绪探针)
- 作用:检测应用程序是否已经准备好接受网络流量。应用启动后可能需要加载配置文件、连接数据库、预热缓存等,这期间虽然进程活着,但不能服务。
- 失败行为:不会重启容器。Kubernetes 会暂时将该 Pod 的 IP 地址从对应 Service 的后端列表(Endpoints)中移除。直到下一次探测成功,才会再次加入。
- 适用场景:
- 应用启动初期需要较长时间加载数据。
- 应用在运行过程中因为负载过高暂时无法处理新请求(以此实现简单的流控)。
- 依赖的后端服务(如数据库)暂时不可用,应用希望暂时屏蔽流量而不是崩溃重启。
C. StartupProbe (启动探针) —— K8s v1.16+ 引入
- 作用:专门为了解决启动慢的遗留应用(Legacy App)。
- 背景:在没有 StartupProbe 之前,如果一个 Java 应用启动需要 3 分钟,而 LivenessProbe 配置为 30 秒检测一次,应用还没启动完就会被 LivenessProbe 判定死亡并无限重启,导致陷入“启动死循环”。
- 机制:
- 在 StartupProbe 成功之前,LivenessProbe 和 ReadinessProbe 不会启用。
- 一旦 StartupProbe 成功(返回 200 或 0),它就完成了历史使命,不再运行,随后 Liveness 和 Readiness 接管。
- 失败行为:如果超过了配置的
failureThreshold * periodSeconds时间应用仍未启动成功,容器会被重启。 - 适用场景:
- 启动非常慢的单体应用(如大型 Java/Spring 应用)。
- 避免为了迁就启动时间而把 LivenessProbe 的检测参数设置得过大(导致运行时反应迟钝)。
3. 它们是如何协同工作的?(生命周期图解)
假设一个 Pod 同时配置了这三种探针,流程如下:
- 容器启动 (Container Created)。
- StartupProbe 开始工作:
- 此时 Liveness 和 Readiness 被暂停。
- 如果 StartupProbe 失败,重试。
- 如果超时仍未成功 -> 重启容器。
- 如果成功 -> 进入下一阶段。
- LivenessProbe 和 ReadinessProbe 同时开始工作:
- LivenessProbe:每隔一段时间检测。如果失败 -> 重启容器。
- ReadinessProbe:每隔一段时间检测。
- 如果失败 -> 停止向该 Pod 发送 Service 流量。
- 如果成功 -> Pod 状态变为 Ready,Service 开始转发流量。
4. 最佳实践建议
Liveness 和 Readiness 不要使用相同的配置:
- Liveness 应该宽容一些(只要进程没死锁就不重启)。
- Readiness 应该严格一些(必须能处理业务才放行流量)。
- 错误示例:如果 Readiness 和 Liveness 检测逻辑完全一样,一旦 Readiness 失败(比如数据库连不上),Liveness 也会失败导致容器重启,这通常不是预期的行为(数据库挂了重启应用没用)。
不要在 Liveness 中检查外部依赖:
- 不要在 LivenessProbe 中去 ping 数据库或外部 API。如果数据库挂了,你的所有 Pod 都会被判定为 Liveness 失败并同时重启,导致级联雪崩。
- 外部依赖检查应该放在 ReadinessProbe 中(数据库挂了,切断流量,等待数据库恢复,而不是重启应用)。
利用 StartupProbe 处理慢启动:
- 对于启动时间超过 30 秒的应用,务必配置 StartupProbe,而不是把 Liveness 的
initialDelaySeconds设置得非常大。
- 对于启动时间超过 30 秒的应用,务必配置 StartupProbe,而不是把 Liveness 的
总结一句话
- Liveness 负责保命(不行就重启)。
- Readiness 负责接客(不行就不给流量)。
- Startup 负责拖延时间(让慢应用先启动完再体检)。