 播面
播面 Flink的数据分区策略
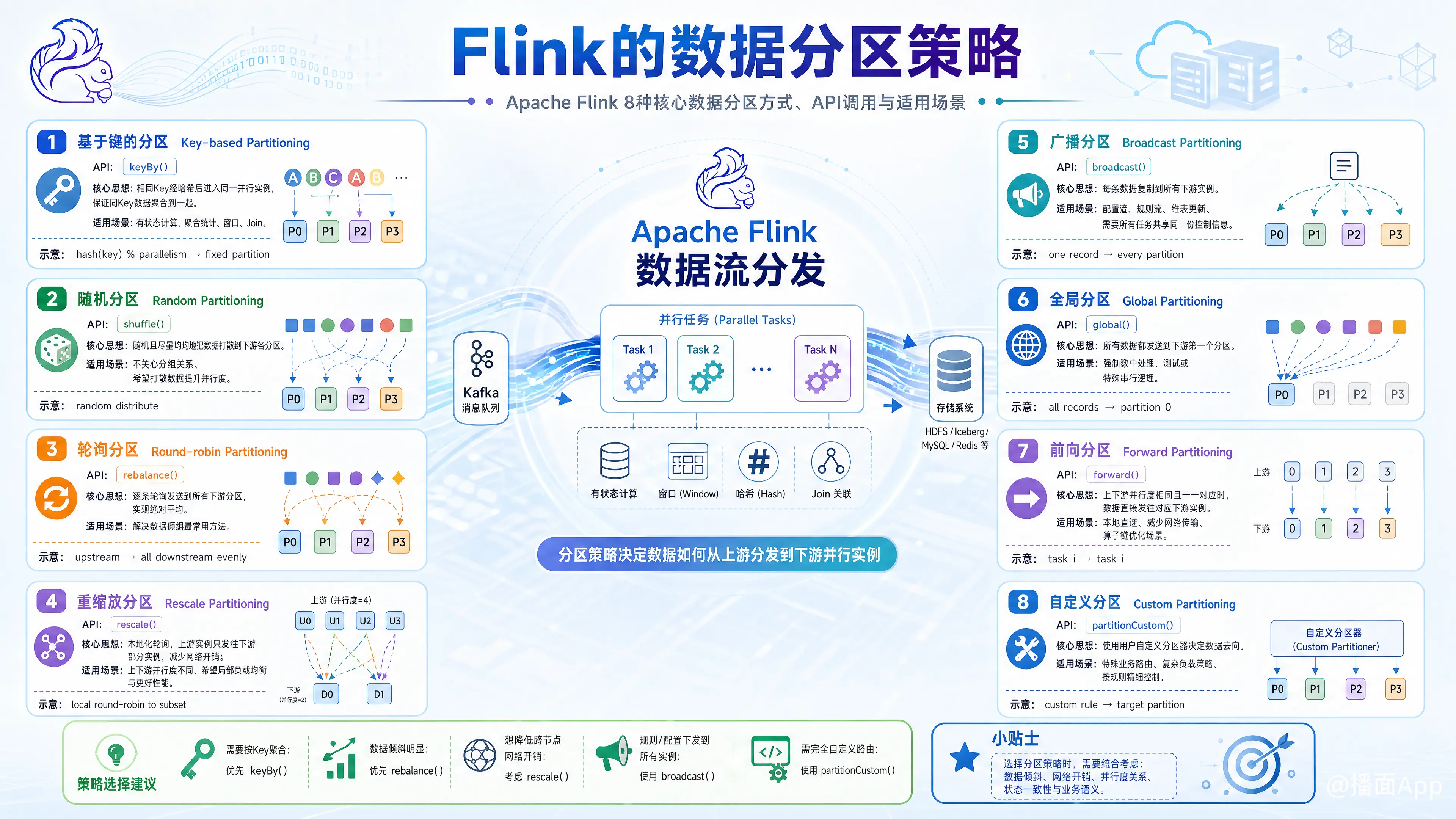
文章介绍了Apache Flink提供的8种核心数据分区策略,包括它们的API调用和适用场景。
Apache Flink 提供了多种数据分区策略(Partitioning Strategies),用于控制数据在上下游算子(Operator)的并行实例之间如何分发。正确选择分区策略对于 Flink 作业的性能、资源利用率和结果正确性至关重要。
以下是 Flink 中最核心的 8 种分区策略,每一种都有其特定的 API 调用和适用场景。
1. Key-based Partitioning (基于键的分区) - keyBy()
这是 Flink 中最重要、最常用的一种分区策略。
- API:
dataStream.keyBy(...) - 核心思想: 根据指定的
Key将数据发送到固定的分区。Flink 会对 Key 计算哈希值,然后根据哈希值对下游算子的并行度取模 (hash(key) % parallelism),从而决定数据进入哪个分区。 - 保证: 具有相同 Key 的所有数据都会被发送到同一个下游任务实例中。
- 主要应用场景:
- 有状态计算: 所有需要按键进行聚合、计数、窗口计算等操作(如
sum(),reduce(),processFunction),都必须先进行keyBy。 - Join 操作: 当你需要将两个数据流按照相同的 Key 连接在一起时。
- 有状态计算: 所有需要按键进行聚合、计数、窗口计算等操作(如
- 代码示例:java
// 按照元组的第一个字段 (ID) 进行分区 dataStream.keyBy(data -> data.f0) .sum(1); // 对第二个字段求和
2. Random Partitioning (随机分区) - shuffle()
- API:
dataStream.shuffle() - 核心思想: 随机、均匀地将数据分发到下游的每个分区。
- 保证: 尽量保证下游每个任务实例接收到的数据量大致相等,但不保证任何数据之间的顺序或分组关系。
- 主要应用场景:
- 当你希望打散数据,提高并行处理能力,但又不关心数据分组时。
- 可以用来缓解轻微的数据倾斜,但效果不如
rebalance。
- 代码示例:java
dataStream.shuffle().print();
3. Round-robin Partitioning (轮询分区) - rebalance()
- API:
dataStream.rebalance() - 核心思想: 以轮询(Round-robin)的方式将数据逐个分发给下游的每一个分区。上游的每个分区会将数据依次发送给下游的所有分区。
- 保证: 下游每个任务实例接收到的数据量绝对平均。
- 主要应用场景:
- 解决数据倾斜: 这是处理数据倾斜最有效、最常用的方法。当上游某些任务实例产生的数据量远大于其他实例时,使用
rebalance可以将这些数据平均分配给所有下游任务,避免下游出现瓶颈。
- 解决数据倾斜: 这是处理数据倾斜最有效、最常用的方法。当上游某些任务实例产生的数据量远大于其他实例时,使用
- 代码示例:java
dataStream.rebalance().map(...);
4. Rescale Partitioning (重缩放分区) - rescale()
rescale 是 rebalance 的一种性能优化版本。
- API:
dataStream.rescale() - 核心思想: 同样是轮询,但它是本地化(local)的轮询。上游的每个任务实例只会将数据发送到下游的一部分任务实例中,而不是全部。
- 与
rebalance的区别:rebalance会导致全局的数据网络传输,每个上游任务都可能连接到所有下游任务。rescale只会进行本地数据传输。例如,一个 TaskManager 上的上游任务只会把数据发送给同一个 TaskManager 上的下游任务(如果可能)。这大大减少了跨节点(TaskManager)的网络开销。
- 主要应用场景:
- 当上下游算子的并行度不同,且你想用比
rebalance更高效的方式来均匀分配数据时。 - 当你确定不需要全局的数据重分区,只需要在 TaskManager 内部进行负载均衡即可。
- 当上下游算子的并行度不同,且你想用比
- 代码示例:java
// 假设上游并行度为2,下游为4 // rescale后,上游分区0的数据发给下游分区0,1 // 上游分区1的数据发给下游分区2,3 dataStream.rescale().map(...);
5. Broadcast Partitioning (广播分区) - broadcast()
- API:
dataStream.broadcast() - 核心思想: 将上游的每一条数据都复制并发送给下游的所有任务实例。
- 保证: 下游的每个并行任务都拥有上游数据集的全量数据。
- 主要应用场景:
- 配置/规则分发: 将一个数据量较小的数据集(如配置信息、机器学习模型、规则集)广播给所有任务,以便它们在处理主数据流时使用。
- Broadcast State Pattern: 这是 Flink 中一种常见的模式,用于将一个流(配置流)与另一个流(事件流)进行连接处理。
- 代码示例:java
// 将配置流广播出去 dataStream.broadcast().connect(mainStream).process(...);
6. Global Partitioning (全局分区) - global()
- API:
dataStream.global() - 核心思想: 将上游所有的分区数据都发送到下游的第一个任务实例(分区索引为 0 的任务)。
- 保证: 所有数据都汇集到一个点。
- 主要应用场景:
- 当你需要对整个数据集进行全局计算,但又无法并行处理时(例如,需要全局排序或收集所有结果)。
- 这会强制下游算子的并行度为 1,成为整个作业的性能瓶颈,因此要谨慎使用。
- 代码示例:java
// 将所有数据发送到下游的第一个实例进行最终处理 dataStream.global().apply(...);
7. Forward Partitioning (前向分区) - forward()
- API:
dataStream.forward() - 核心思想: 上游分区
i的数据直接发送给下游分区i。这是一个一对一的传输。 - 要求: 上下游算子的并行度必须相等,否则会报错。
- 主要应用场景:
- 性能优化。当你在一个
map或filter操作后,不希望数据重新分区(因为没有改变数据的分布),forward可以避免不必要的网络 shuffle,保持数据流的“直通”状态。 - Flink 的算子链(Operator Chaining)优化在很多情况下会自动实现类似
forward的效果。
- 性能优化。当你在一个
- 代码示例:java
// 假设上下游并行度都为4 // 上游分区i的数据只会发给下游分区i dataStream.forward().map(...);
8. Custom Partitioning (自定义分区) - partitionCustom()
- API:
dataStream.partitionCustom(Partitioner<K> partitioner, KeySelector<IN, K> keySelector) - 核心思想: 用户可以自己实现
Partitioner接口,定义自己的分区逻辑。 - 保证: 根据你自定义的逻辑进行分区。
- 主要应用场景:
- 当 Flink 内置的所有分区策略都无法满足你的特殊需求时。
- 例如,你想根据数据的某个字段(如城市名)将数据路由到指定的分区(北京到分区0,上海到分区1等)。
- 代码示例:java
// 自定义一个Partitioner public class MyPartitioner implements Partitioner<String> { @Override public int partition(String key, int numPartitions) { if ("beijing".equals(key)) { return 0; } else if ("shanghai".equals(key)) { return 1; } else { return 2 % numPartitions; } } } // 使用自定义分区 dataStream.partitionCustom(new MyPartitioner(), data -> data.getCity());
总结对比
| 策略 (Strategy) | API | 核心思想 | 主要应用场景 |
|---|---|---|---|
| Key-based | keyBy() |
相同Key进入同一分区 | 有状态计算、聚合、Join |
| Random (Shuffle) | shuffle() |
随机分发 | 简单的数据重分布,不关心分组 |
| Round-robin | rebalance() |
全局轮询分发 | 解决数据倾斜,保证绝对均匀 |
| Rescale | rescale() |
本地轮询分发 | rebalance的性能优化版,减少网络开销 |
| Broadcast | broadcast() |
复制到所有下游分区 | 分发配置数据、小表 Join(Broadcast State) |
| Global | global() |
全部汇集到第一个分区 | 全局聚合或排序(下游并行度为1) |
| Forward | forward() |
一对一传输 | 性能优化,上下游并行度需相同 |
| Custom | partitionCustom() |
用户自定义逻辑 | 满足内置策略无法实现的特殊分区需求 |