 播面
播面 发生Full GC的诊断流程
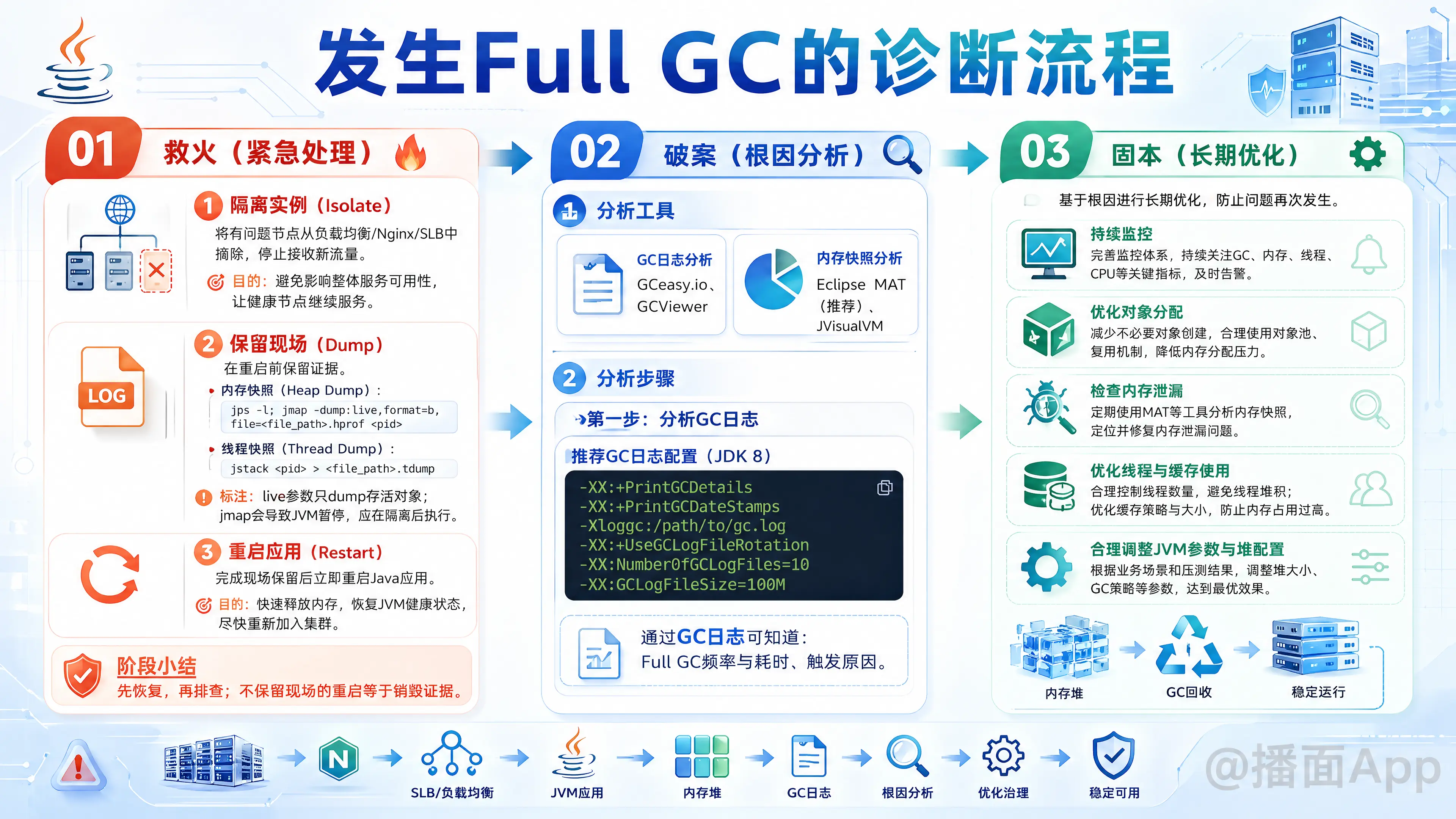
本文系统性地讲解了解决线上Full GC问题的方法,分为紧急处理、根因分析和长期优化三个阶段。
线上出现 Full GC 是一个非常严重的问题,通常意味着系统性能出现瓶頸或即将中断服务。解决这个问题需要一套系统性的方法,从紧急处理到根因分析,再到长期优化。
下面我将这个过程分为三个阶段:“救火”(紧急处理)、“破案”(根因分析)和“固本”(长期优化)。
第一阶段:救火(紧急处理)
当线上告警 Full GC 频繁,甚至服务已经开始响应缓慢或不可用时,首要目标是 快速恢复服务。
这套操作俗称“三板斧”:
隔离实例 (Isolate)
- 操作:如果你的服务是集群部署,立即将有问题的节点从负载均衡(Nginx, SLB 等)中摘除,不再让它接收新的流量。
- 目的:避免单点问题影响整个服务的可用性。让健康的节点继续提供服务。
保留现场 (Dump)
- 操作:在重启应用之前,务必保留现场证据,这是后续“破案”的关键。
- 内存快照 (Heap Dump):这是最重要的证据。执行
jmap命令来生成堆转储文件。
bash# 1. 找到Java进程的PID jps -l # 2. 生成heap dump文件 (注意:该命令会导致JVM暂停,所以要在隔离后执行) # <pid> 是你的Java进程ID # <file_path> 是dump文件的存放路径,建议放在大磁盘空间目录 jmap -dump:live,format=b,file=<file_path>.hprof <pid>live参数只 dump 存活的对象,可以减小文件大小,分析时更有针对性。- 线程快照 (Thread Dump):有时候 Full GC 也可能和线程阻塞有关。
bashjstack <pid> > <file_path>.tdump - 内存快照 (Heap Dump):这是最重要的证据。执行
- 操作:在重启应用之前,务必保留现场证据,这是后续“破案”的关键。
重启应用 (Restart)
- 操作:完成现场保留后,立即重启该Java应用。
- 目的:重启能最快地释放内存,让JVM恢复到健康状态,可以尽快将该节点重新加入集群,恢复服务的整体处理能力。
小结:救火阶段的核心是“先恢复,再排查”。不保留现场的重启等于“销毁证据”,会让问题排查变得极其困难。
第二阶段:破案(根因分析)
服务恢复后,就可以拿着第一阶段保留的证据,开始分析 Full GC 的根本原因。
1. 分析工具
- GC日志分析工具:GCeasy.io (在线)、GCViewer (本地)
- 内存快照分析工具:Eclipse MAT (Memory Analyzer Tool) (功能最强大,推荐)、JVisualVM
2. 分析步骤
第一步:分析GC日志
如果你的应用启动时配置了GC日志(强烈建议所有线上应用都配置),这是最直接的线索。
# 推荐的GC日志配置 (JDK 8)
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-Xloggc:/path/to/gc.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100M通过分析GC日志,你可以知道:
- Full GC 的频率和耗时:问题有多严重。
- Full GC 的触发原因:这是定位问题的关键!常见原因包括:
Allocation Failure:老年代空间不足,无法分配新对象。这是最常见的原因。System.gc():代码中显式调用了System.gc()。Metadata GC Threshold:Metaspace (元空间) 不足。Ergonomics:JVM根据其工效学(Ergonomics)策略自动触发。
第二步:分析内存快照 (Heap Dump)
将第一阶段生成的 .hprof 文件导入 MAT 进行分析。MAT 的核心功能是帮助你找到“谁占用了大量内存且无法被回收”。
- 启动MAT分析:打开 MAT,加载
.hprof文件。这个过程可能需要较长时间和较大内存。 - 查看概览 (Overview):MAT 会给出一个饼图,显示最大的几个对象。这能让你对内存占用情况有个初步印象。
- 运行“Leak Suspects”报告:这是 MAT 的王牌功能。它会自动分析并给出最可疑的内存泄漏点,通常直接就能定位到问题。
- 使用“Dominator Tree” (支配树):
- 作用:列出堆中所有对象,并按照它们持有的总内存大小(Retained Heap)排序。
- 分析方法:排在最前面的对象就是“元凶”。右键点击它,选择
Path to GC Roots,查看它的引用链,就能知道为什么它无法被回收。
- 使用“Histogram” (直方图):
- 作用:按类名列出所有实例的数量和大小。
- 分析方法:可以快速找到哪个类的实例最多或总大小最大。例如,你可能会发现
byte[]或String占用了G级别的内存。再结合支配树,找到这些实例是被谁引用的。
3. 常见 Full GC 原因与场景
结合以上分析,通常可以将 Full GC 的原因归为以下几类:
内存泄漏 (Memory Leak)
- 现象:老年代内存持续增长,即使在 Full GC 后也无法有效回收,最终导致OOM或频繁Full GC。
- 典型场景:
- 长生命周期的集合类:
static的Map,List等容器,只进不出,不断添加数据。 - 资源未关闭:数据库连接、网络连接、文件流等没有在
finally块或try-with-resources中正确关闭。 - ThreadLocal使用不当:线程池中的线程复用,但
ThreadLocal变量没有被remove(),导致对象一直被线程引用。 - 内部类或监听器未注销:非静态内部类持有外部类的引用,导致外部类无法回收。
- 长生命周期的集合类:
大对象或大流量冲击
- 现象:GC日志显示,老年代使用率短时间内迅速飙升,随后触发Full GC。每次Full GC后老年代都能被有效回收。
- 典型场景:
- 一次性加载大量数据:从数据库或文件中一次性读取了G级别的数据到内存中,例如导出报表功能。
- 流量洪峰:突发的大量请求,导致短时间内创建了海量对象,Minor GC 来不及回收,大量对象被直接晋升到老年代。
- 不合理的大对象:程序中存在一次性分配几百兆甚至上G的超大对象(如
byte[]),直接进入老年代。
JVM参数配置不当
- 现象:GC表现不符合预期,例如Young GC频繁,对象晋升过快。
- 典型场景:
- 堆内存过小:
-Xms,-Xmx设置得太小,无法承载正常的业务量。 - 新生代过小:
-Xmn设置过小,或-XX:NewRatio值过大。导致对象稍微“熬过”一两次Minor GC就被晋升到老年代。 - 元空间过小:
-XX:MetaspaceSize和-XX:MaxMetaspaceSize过小,导致因元空间不足而触发Full GC(常见于大量使用动态类生成、反射、Lambda表达式的场景)。
- 堆内存过小:
代码中显式调用
System.gc()- 现象:GC日志中明确看到
System.gc()触发的Full GC。 - 排查:全局搜索代码中的
System.gc()调用。一些第三方库(如 RMI)也可能调用。 - 解决方案:通常应避免手动调用。可以通过
-XX:+DisableExplicitGC参数来禁止显式调用。
- 现象:GC日志中明确看到
第三阶段:固本(长期优化)
根据“破案”阶段的结论,进行针对性的修复和优化。
代码层面优化
- 修复内存泄漏:找到泄漏点,修改代码逻辑(如:使用后清空
static集合、正确关闭资源、remove()ThreadLocal)。 - 优化大对象处理:对于大数据处理,改用流式(Stream)读取、分页查询、分批处理等方式,避免一次性将所有数据加载到内存。
- 优化数据结构:使用更节省内存的数据结构,例如使用基本类型数组代替包装类型集合。
- 修复内存泄漏:找到泄漏点,修改代码逻辑(如:使用后清空
JVM层面优化
- 合理配置堆大小:根据应用的实际内存使用情况,调整
-Xms,-Xmx,-Xmn等参数。通常建议-Xms和-Xmx设置为相同值,避免堆动态扩容带来的性能开销。 - 调整新生代和老年代比例:如果应用创建大量短生命周期的对象,可以适当调大新生代 (
-Xmn)。 - 选择合适的GC收集器:
- JDK 8 默认是 Parallel Scavenge + Parallel Old,吞吐量优先。
- CMS (Concurrent Mark Sweep):关注低停顿,但有内存碎片问题。
- G1 (Garbage-First):JDK 9+ 的默认收集器,是目前的主流选择,在吞吐量和停顿时间之间取得了很好的平衡。对于大部分应用,从 Parallel 或 CMS 切换到 G1 都能有不错的性能提升。
- ZGC / Shenandoah:JDK 11+ 引入的低延迟收集器,STW时间极短(毫秒级),适合对延迟要求极高的大内存应用。
- 合理配置堆大小:根据应用的实际内存使用情况,调整
建立监控和预警机制
- 持续监控:使用APM工具(如 SkyWalking, Pinpoint)或Prometheus + Grafana,持续监控JVM的各项指标(堆内存、GC次数/耗时、线程数等)。
- 设置告警:为Full GC次数、老年代使用率等关键指标设置合理的告警阈值,做到提前发现问题,而不是等服务不可用时才介入。
总结
解决线上 Full GC 问题是一个综合性的工程,需要沉着冷静,遵循科学的流程:
- 紧急响应:隔离、Dump、重启,快速恢复服务。
- 根因分析:利用GC日志和内存快照,借助MAT等工具,精准定位问题。
- 长期优化:从代码和JVM层面彻底解决问题,并建立完善的监控体系,防患于未然。
掌握这套方法论,不仅能解决当前的 Full GC 问题,更是衡量一个高级Java工程师能力的重要标准。