 播面
播面 Golang Map 的底层实现原理
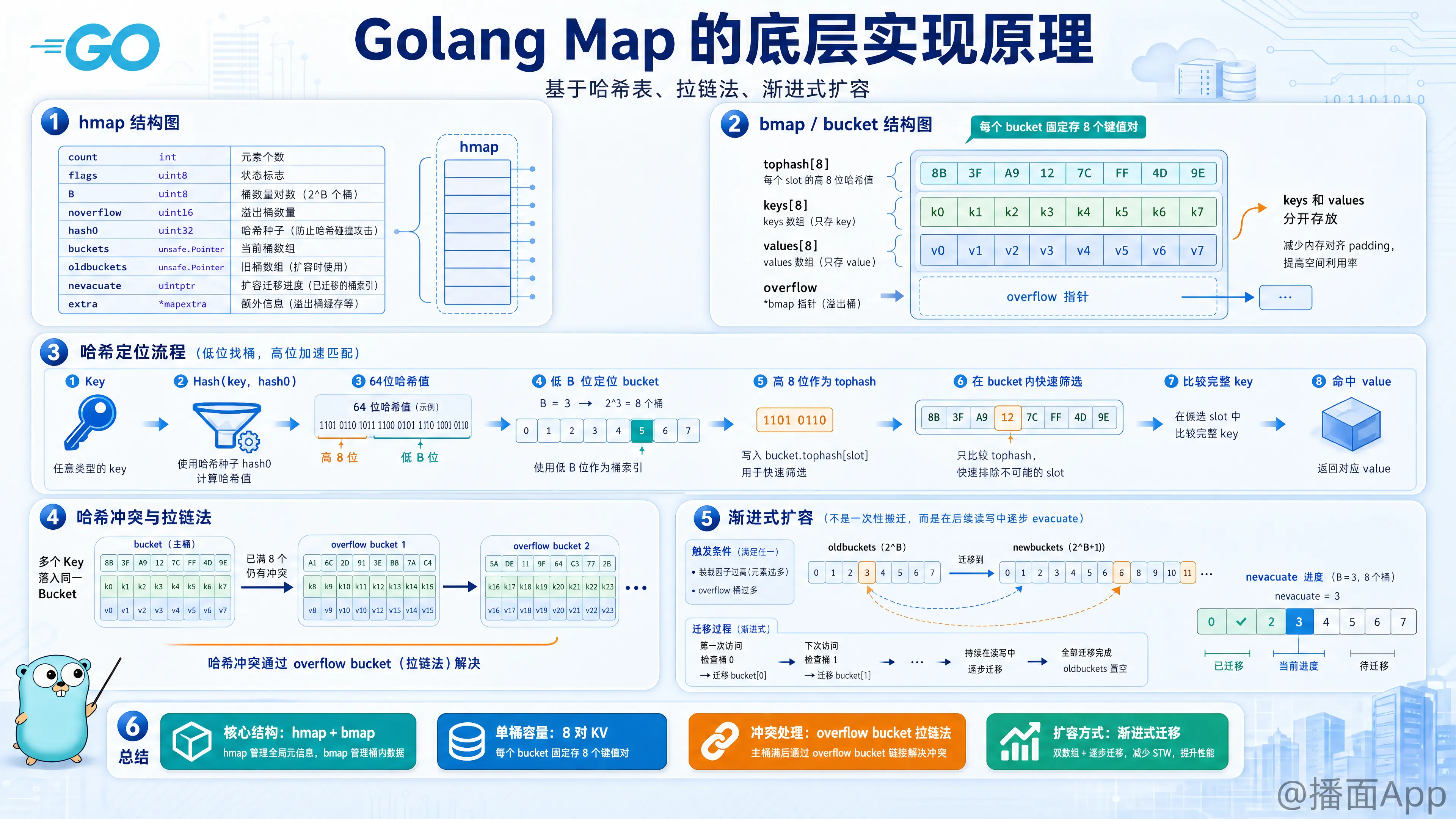
Golang 的 map 是一个非常高频使用的面试考点。它的底层实现是一个基于哈希表(Hash Table)的数据结构,采用拉链法(Chaining)来解决哈希冲突,并使用了渐进式扩容策略。
以下是 Golang map 底层实现的详细解析:
1. 核心数据结构
Go map 的源码位于 runtime/map.go 中。核心结构体有两个:hmap(header map)和 bmap(bucket map)。
1.1 hmap (Map 的头部信息)
这是 map 的最外层结构,当我们声明 m := make(map[string]int) 时,返回的就是一个指向 hmap 的指针。
go
type hmap struct {
count int // 当前 map 中的元素个数 (len(map) 返回这个值)
flags uint8 // 状态标志 (如:是否正在写入,用于并发检测)
B uint8 // 桶数量的对数 (len(buckets) = 2^B)
noverflow uint16 // 溢出桶的大致数量
hash0 uint32 // 哈希种子 (随机数,防止哈希碰撞攻击)
buckets unsafe.Pointer // 指向 bucket 数组的指针
oldbuckets unsafe.Pointer // 扩容时指向旧 bucket 数组的指针
nevacuate uintptr // 扩容进度计数器 (指示搬迁到了哪个 bucket)
extra *mapextra // 存储溢出桶的额外信息 (优化 GC)
}1.2 bmap (Bucket 桶)
buckets 指向的是一个 bmap 数组。每个 bmap 就是一个“桶”,用来实际存储 Key-Value 数据。
在源码中 bmap 定义很简单,但编译期间会动态生成其完整结构:
go
// 源码定义
type bmap struct {
tophash [8]uint8 // 存储哈希值的高8位
}
// 编译期间动态生成的实际结构大致如下:
type bmap struct {
tophash [8]uint8 // 8个 key 哈希值的高8位
keys [8]KeyType // 8个 Key
values [8]ValueType // 8个 Value
overflow *bmap // 指向溢出桶的指针 (拉链法)
}关键设计细节:
- Bucket 大小: 每个 bucket 固定存储 8个 键值对。
- 内存布局优化: 注意
keys和values是分开存放的(k1,k2...v1,v2...),而不是交替存放(k1,v1,k2,v2...)。- 原因: 为了节省内存对齐带来的 padding 开销。例如
map[int64]int8,如果交替存放,每个int8后面都要补 7 个字节的 padding;分开存放则不需要。
- 原因: 为了节省内存对齐带来的 padding 开销。例如
- tophash: 存储哈希值的高 8 位。在查找时,先比较 tophash,如果不匹配直接跳过,匹配了再比较完整的 Key,极大提高了查找效率。
2. 哈希计算与定位
当进行 map[key] 操作时,过程如下:
- 计算 Hash 值: 使用哈希函数(如 AES hash)和种子
hash0计算 Key 的 64 位哈希值。 - 定位 Bucket (低位): 取哈希值的低 B 位,用来决定该 Key 落在哪个 bucket(数组下标)。
- 定位 Slot (高位): 取哈希值的高 8 位(tophash),在 bucket 内部遍历比较。
3. 哈希冲突解决 (拉链法)
当两个不同的 Key 落在同一个 Bucket 时(即低位哈希相同):
- Go 会尝试将新数据放入该 Bucket 的空闲槽位(一共8个)。
- 如果该 Bucket 的 8 个槽位都满了,Go 会创建一个溢出桶(overflow bucket)。
- 将当前 Bucket 的
overflow指针指向这个新桶,形成一个链表结构。
4. 扩容机制 (Rehashing)
Go map 的扩容是渐进式的,为了避免一次性搬迁大量数据导致性能抖动(Stop the World)。
4.1 触发扩容的条件
- 负载因子过大 (Load Factor > 6.5):
- 公式:
count / (2^B) > 6.5。即平均每个 bucket 存储的元素超过 6.5 个。 - 动作: 翻倍扩容。
B加 1,bucket 数组大小变为原来的 2 倍。
- 公式:
- 溢出桶过多 (Overflow buckets 太多):
- 当 bucket 总数 < 2^15 时,溢出桶数量 > bucket 总数。
- 当 bucket 总数 >= 2^15 时,溢出桶数量 > 2^15。
- 这种情况通常发生在频繁删除元素后,bucket 里有很多空洞。
- 动作: 等量扩容。
B不变,创建一个新的 bucket 数组,将旧数据整理搬迁过去(内存整理,减少碎片)。
4.2 渐进式搬迁 (Evacuation)
- 触发扩容时,不会立即搬迁所有数据。而是将
oldbuckets指向旧数组,buckets指向新数组。 - 搬迁时机: 每次对 map 进行写操作(插入、删除)时,会顺带搬迁 2 个 bucket 的数据(一个是当前访问的 bucket,一个是按顺序的
nevacuatebucket)。 - 读操作: 如果正在扩容,读操作会先去
oldbuckets查找,如果旧 bucket 还没搬迁,就在旧的里面找;如果已经搬迁,就去新 bucket 找。 - 直到所有数据搬迁完毕,
oldbuckets被置为 nil,扩容结束。
5. 并发安全性
Go 的原生 map 是非线程安全的。
- 原因: map 的设计初衷是追求极致的单线程性能。加锁会带来巨大的开销。
- 表现: 如果检测到并发写(通过
flags位的hashWriting标志),Go runtime 会直接抛出 fatal error (concurrent map writes),导致程序崩溃,且无法 recover。 - 解决方案:
- 使用
sync.Mutex或sync.RWMutex进行加锁保护。 - 使用 Go 1.9 引入的
sync.Map(适用于读多写少的场景)。
- 使用
6. 总结 (面试速记版)
- 结构:
hmap维护元数据,指向buckets数组。 - 存储: 每个 bucket (
bmap) 存 8 个 Key-Value,为了内存对齐,Key 和 Value 是分开堆放的。 - 冲突: 使用拉链法,桶满了链接到溢出桶。
- 查找: 哈希低位定桶,高位 (tophash) 定槽。
- 扩容:
- 翻倍扩容: 负载因子 > 6.5。
- 等量扩容: 溢出桶太多(整理内存)。
- 策略: 渐进式扩容,每次写操作搬迁一部分,避免性能卡顿。
- 并发: 不安全,并发写会 panic。