 播面
播面 数据仓库分层的好处?
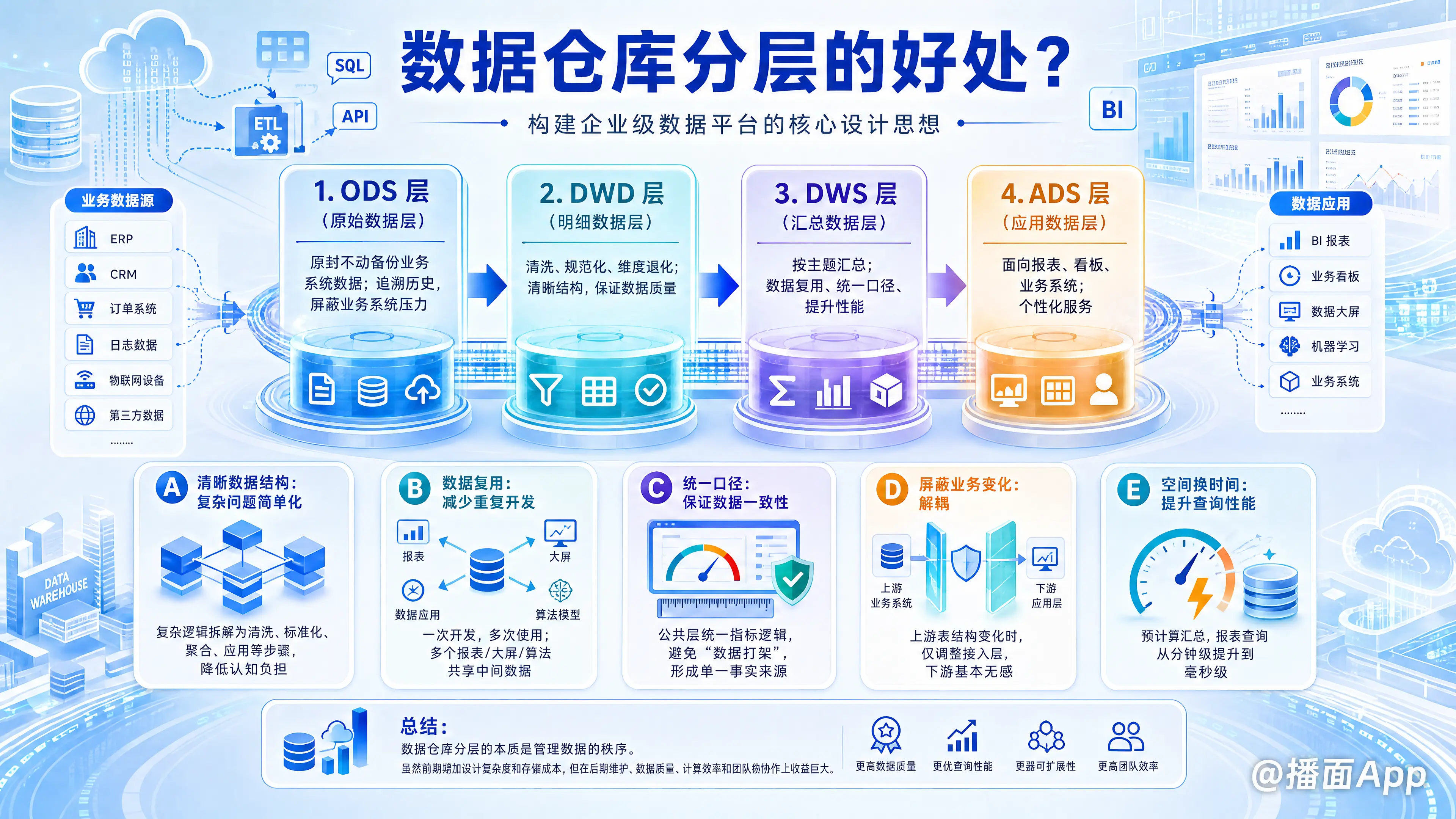
数据仓库分层(Layering)是构建企业级数据平台的核心设计思想。简单来说,就是把数据处理的过程像“流水线”一样分成几个阶段,每个阶段只做特定的事情。
数据仓库分层的主要好处可以总结为以下 5 点核心优势:
1. 清晰数据结构:复杂问题简单化
- 好处:将复杂的业务逻辑拆解为多个步骤。
- 解释:就像写代码要分模块、写文章要分段落一样。通过分层,我们将一个复杂的任务(例如:从杂乱的日志中计算出年度财报)分解成清洗、标准化、聚合、应用等多个简单的步骤。
- 结果:每一层都有明确的职责,开发人员更容易理解数据的流向和逻辑,降低了认知负担。
2. 数据复用:减少重复开发
- 好处:一次开发,多次使用(Write Once, Read Many)。
- 解释:如果没有分层,每个报表都要从原始数据(Raw Data)重新计算一遍。有了中间层(如 DWD 明细层或 DWS 汇总层),多个下游应用(如报表 A、大屏 B、算法 C)可以共用同一份处理好的中间数据。
- 结果:极大地减少了代码冗余,提升了开发效率。
3. 统一口径:保证数据一致性
- 好处:避免“数据打架”。
- 解释:在没有分层的情况下,财务部门和销售部门可能各自从原始数据计算“销售额”,因为过滤条件不同(比如是否包含退款),导致结果不一致。
- 结果:通过在公共层(DWS)统一计算逻辑,所有下游应用都取用同一个指标值,确保了全公司数据口径的统一(Single Source of Truth)。
4. 屏蔽业务变化:解耦(Decoupling)
- 好处:上游改动不影响下游。
- 解释:业务系统的数据库结构经常变化(比如表名变了、字段改了)。如果没有分层,所有下游报表都要重写。
- 结果:有了分层(特别是 ODS 和 DWD 层),只需要修改接入层的一小段代码,下游的汇总层和应用层完全不需要感知上游的变化,大大降低了维护成本。
5. 空间换时间:提升查询性能
- 好处:预计算,查询快。
- 解释:海量数据的聚合计算(Sum, Count, Distinct)非常消耗资源和时间。
- 结果:通过在汇总层(DWS)预先将数据计算好(比如按天、按月汇总),虽然多占用了存储空间,但当用户查询报表时,只需要查询极少量的结果数据,响应速度从“几分钟”提升到“毫秒级”。
附:通用的分层架构(参考)
为了更好地理解上述好处,通常数据仓库会被分为以下四层:
- ODS 层 (Operational Data Store) - 原始数据层:
- 作用:原封不动地备份业务系统数据。
- 对应好处:追溯历史,屏蔽业务系统压力。
- DWD 层 (Data Warehouse Detail) - 明细数据层:
- 作用:清洗、规范化(比如把“男/女”统一为“M/F”)、维度退化。
- 对应好处:清晰结构,数据质量保证。
- DWS 层 (Data Warehouse Service) - 汇总数据层:
- 作用:按主题进行轻度或高度汇总(如:用户日表、商品月表)。
- 对应好处:数据复用,统一口径,提升性能。
- ADS 层 (Application Data Service) - 应用数据层:
- 作用:直接面向具体报表或业务系统的结果数据。
- 对应好处:个性化服务。
总结
数据仓库分层的本质是管理数据的秩序。它虽然在前期增加了设计的复杂度(和存储成本),但在后期维护、数据质量、计算效率和团队协作上带来了巨大的收益。