 播面
播面 什么是宽表?为什么要建设宽表?
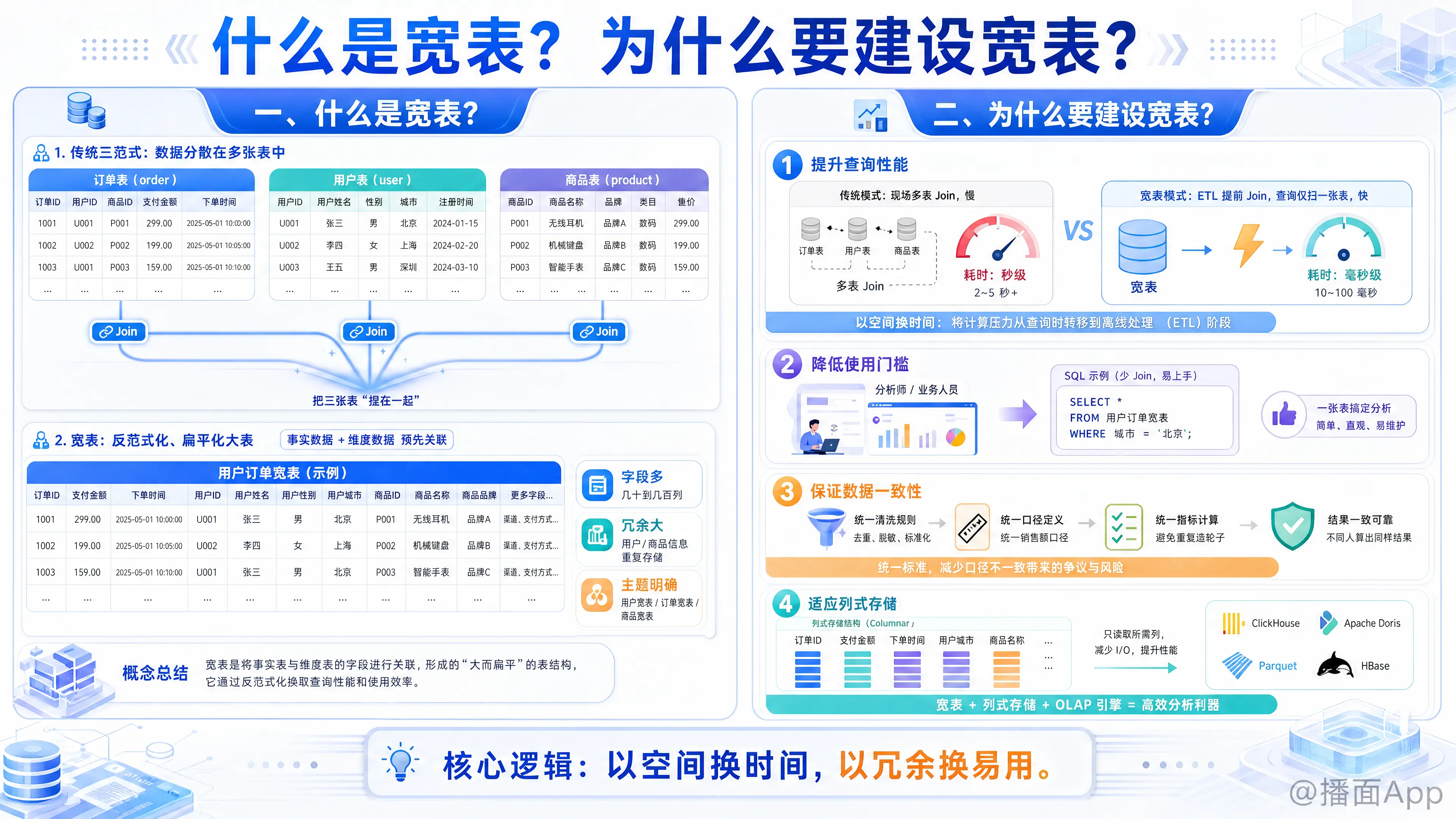
宽表(Wide Table) 是数据仓库和大数据分析领域中非常核心的一个概念。
简单来说,宽表就是一张包含了很多很多字段(列)的表。它通常是将业务中的“事实数据”和相关的“维度数据”提前关联(Join)好,形成的一张扁平化的大表。
为了让你更透彻地理解,我们可以从“什么是宽表”和“为什么要建设宽表”两个方面来详细拆解。
一、 什么是宽表?
在传统的数据库设计(如 MySQL 业务库)中,为了减少数据冗余,我们遵循“三范式” (3NF) 设计原则,把数据拆散存放在不同的表中。
举个电商场景的例子:
如果要查询“北京地区 25 岁男性用户的 iPhone 销量”,在传统模式下,你可能需要关联三张表:
- 订单表(存了订单ID、用户ID、商品ID、金额)
- 用户表(存了用户ID、姓名、性别、年龄、所在城市)
- 商品表(存了商品ID、商品名称、品牌、类目)
而宽表,就是把这三张表“捏”在一起:
它不遵循三范式,而是采用“反范式化”设计。在宽表中,每一行数据不仅包含订单信息,还直接包含该订单对应的用户详情和商品详情。
宽表的结构看起来是这样的:
| 订单ID | 支付金额 | 下单时间 | 用户ID | 用户姓名 | 用户性别 | 用户城市 | 商品ID | 商品名称 | 商品品牌 | ...更多字段 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1001 | 5000 | 10:00 | U01 | 张三 | 男 | 北京 | P01 | iPhone | Apple | ... |
核心特征:
- 字段多: 可能包含几十甚至几百个字段。
- 冗余大: 比如“张三”下了 10 单,那么“张三、男、北京”这些信息就会在宽表中重复存储 10 次。
- 主题明确: 通常是基于某个实体或业务过程构建的,如“用户宽表”、“订单宽表”、“商品宽表”。
二、 为什么要建设宽表?
既然宽表会造成大量的数据冗余(浪费存储空间),为什么在大数据分析和数据仓库(DWS层/ADS层)中,宽表却是主流选择?
核心逻辑是:以空间换时间,以冗余换易用。
1. 提升查询性能(最主要原因)
在大数据量级下(亿级数据),表与表之间的关联(Join)操作是非常消耗计算资源(CPU/内存)和时间的。
- 传统模式: 每次查询都要现场把几张大表 Join 起来,速度极慢,甚至跑不出来。
- 宽表模式: 数据在写入宽表之前(ETL阶段)已经 Join 好了。查询时,只需要扫描这一张表,完全避免了 Join 操作。这使得查询响应速度可以从“分钟级”提升到“毫秒/秒级”。
- 注:现代 OLAP 引擎(如 ClickHouse、Doris)配合列式存储,对宽表的查询速度优化到了极致。
2. 降低使用门槛,提高分析效率
对于数据分析师(DA)、业务人员或数据科学家来说,写复杂的 SQL(包含 5-6 个 Join)是非常痛苦且容易出错的。
- 建设宽表后: 业务人员只需要面对一张表,直接
SELECT * FROM 宽表 WHERE 城市='北京'即可。不需要了解底层复杂的表结构关系,大大降低了取数门槛。
3. 保证数据一致性(口径统一)
在复杂的业务中,同一个指标可能有不同的算法。
- 如果不建宽表,分析师 A 和分析师 B 在关联表时,可能过滤条件不同(例如是否包含退款订单),导致算出的“销售额”不一致。
- 建设宽表后: 数据开发工程师在构建宽表时,已经统一了清洗规则和计算口径。所有下游业务都统一使用这张宽表,保证了“数据出口”的一致性。
4. 适应列式存储
大数据分析引擎(如 HBase, ClickHouse, Parquet 文件格式)通常采用列式存储。列式存储非常适合宽表结构:
- 当你只需要查询“销售额”这一列时,数据库只需要读取这一列的数据,而忽略其他 99 个字段。这使得宽表即使字段再多,查询特定几列时速度依然飞快。
三、 宽表的缺点与挑战
虽然宽表很好用,但建设宽表也有代价:
- 存储成本高: 大量的冗余数据会占用更多的磁盘空间(虽然现在的压缩算法已经能很好地缓解这个问题)。
- 数据回溯与更新困难: 这是宽表最大的痛点。
- 如果“张三”从北京搬到了上海,在范式设计中只需改用户表的一行数据。
- 但在订单宽表中,需要把张三历史所有的订单记录中的“城市”字段全部更新。在大数据环境下,这种 Update 操作极其昂贵甚至不支持。
- 解决方案:通常采用“拉链表”或仅保留当时快照,或者每天全量重算。
- ETL 开发成本: 宽表的生成需要复杂的 ETL 任务调度,数据产出会有一定的延迟(通常是 T+1,即第二天才能看到前一天的宽表)。
总结
宽表是大数据时代的产物。
- 它是什么: 一张包含所有相关维度和指标的、反范式化的、扁平的大表。
- 为什么做: 为了不想在查询时做 Join。它牺牲了存储空间和灵活性,换取了极致的查询速度和极简的使用体验。