 播面
播面 Spark中如何处理小文件过多的问题?
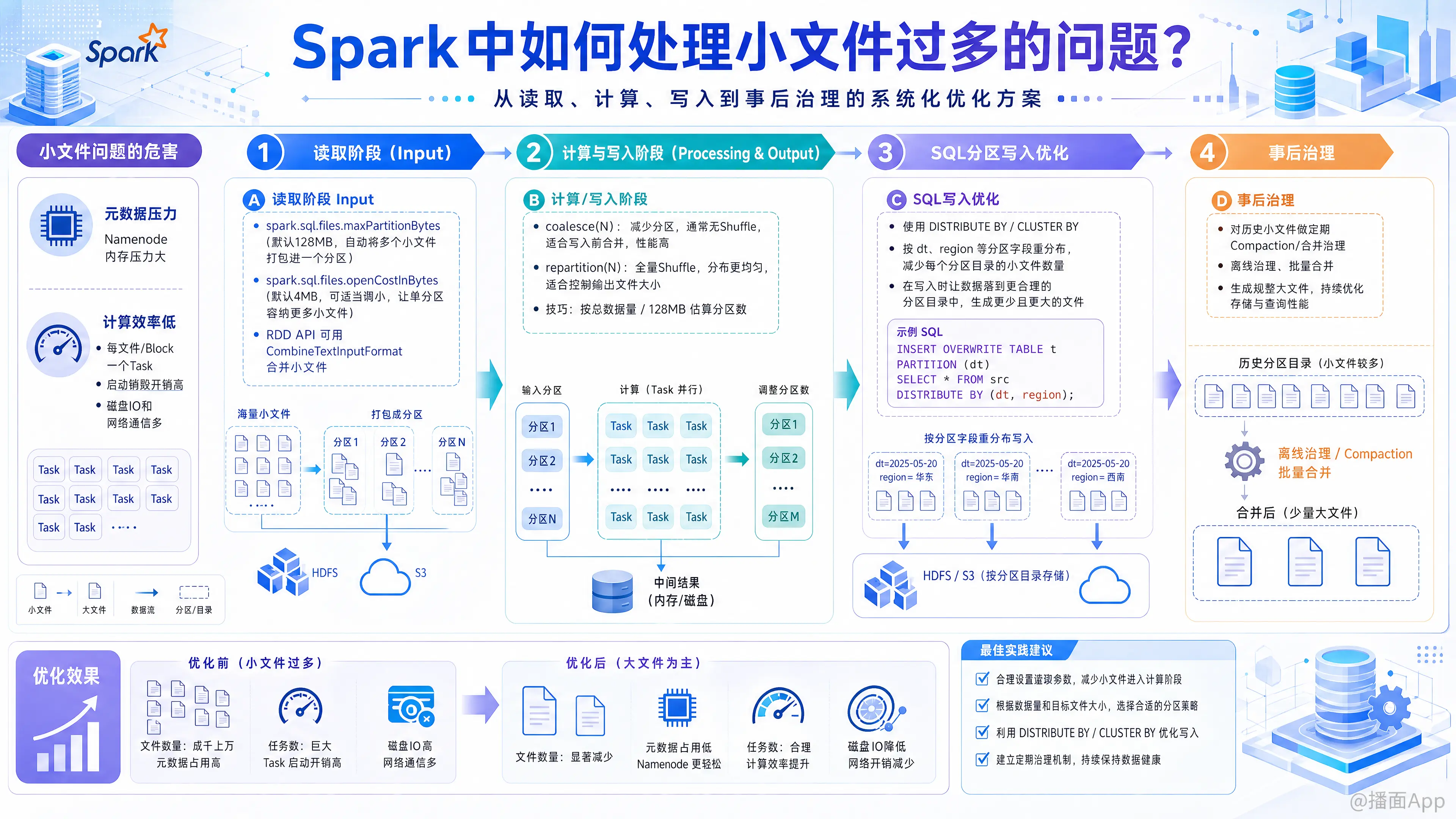
在 Spark 中,小文件过多(Small Files Problem)是一个非常经典且严重的性能杀手。它主要会导致两个问题:
- 元数据压力:HDFS 的 Namenode 内存压力大(每个文件占用约 150 bytes 内存)。
- 计算效率低:Spark 会为每个文件(或 block)生成一个 Task,导致 Task 启动/销毁的开销远大于实际计算时间,且会有大量的磁盘 IO 和网络通信。
解决这个问题通常需要分三个阶段来考虑:读取时(输入)、计算中(处理)、写入时(输出),以及事后治理。
以下是详细的解决方案:
1. 读取阶段 (Input)
当数据源已经是大量小文件时,我们需要让 Spark 在读取时将它们合并,避免生成成千上万个 Task。
调整
spark.sql.files.maxPartitionBytes(推荐)- 原理:这是 Spark SQL 读取文件时的核心参数。默认是 128MB。Spark 会尝试将多个小文件打包进一个分区(Partition),直到达到这个大小。
- 操作:如果小文件特别多且特别小,可以适当调小这个值(例如 64MB),或者保持默认,确保 Spark 能够自动合并。
- 配合参数:
spark.sql.files.openCostInBytes(默认 4MB)。Spark 会把打开一个文件的开销预估为 4MB。如果文件实际只有 1KB,Spark 也会把它当做 4MB+1KB 来计算分区填冲。如果小文件极多,可以适当调小此参数,让 Spark 认为打开文件很便宜,从而在一个分区里塞入更多文件。
使用 Hadoop 的
CombineTextInputFormat(针对 RDD API)- 如果使用的是旧版 RDD API (
sc.textFile),默认是不会合并小文件的。需要显式使用sc.newAPIHadoopFile并指定CombineTextInputFormat。
- 如果使用的是旧版 RDD API (
2. 计算与写入阶段 (Output)
这是产生小文件的主要源头。通常是因为 Shuffle 后分区数太多,或者动态分区写入时数据分散。
A. 使用算子手动合并
coalesce(N)(推荐用于减少分区)- 原理:不进行 Shuffle,直接将多个分区的 Block 合并。
- 场景:数据量变少后(比如经过 filter 过滤后),在写入前调用。
- 优点:性能高,无 Shuffle。
- 缺点:只能减少分区,不能增加;如果数据分布不均,合并后可能导致数据倾斜。
repartition(N)- 原理:进行全量 Shuffle,重新打散数据。
- 场景:需要彻底平衡数据分布,或者需要增加分区数时。
- 优点:生成的文件大小均匀。
- 缺点:Shuffle 代价昂贵(网络+磁盘IO)。
- 技巧:在写入 HDFS/S3 前,根据数据总量估算 N 的大小(例如:总数据量 / 128MB = N),确保每个输出文件大小适中。
B. SQL 写入时的优化 (Distribute By)
在使用 Spark SQL 写入分区表(Partitioned Table)时,如果 Map 端的数据是乱序的,每个 Task 都可能包含所有分区的数据,导致每个 Task 都要在每个分区目录下创建一个小文件。
- 解决方案:使用
DISTRIBUTE BY或CLUSTER BY。 - 代码示例:sql
INSERT OVERWRITE TABLE target_table SELECT * FROM source_table DISTRIBUTE BY (dt, region); -- 按照分区字段进行 Shuffle - 效果:相同的分区键数据会被 Shuffle 到同一个 Task 中,这样该 Task 只会向对应的分区目录写出一个(或少数几个)大文件。
C. Spark 3.x 自适应查询执行 (AQE)
Spark 3.0+ 引入了 AQE (Adaptive Query Execution),可以自动处理 Shuffle 后的小文件问题。
- 配置:
spark.sql.adaptive.enabled = truespark.sql.adaptive.coalescePartitions.enabled = true(默认开启)
- 原理:在 Shuffle 阶段结束后,Spark 会查看每个分区的实际数据量。如果发现很多分区数据量很小,它会自动将相邻的小分区合并成一个大分区,从而减少下游 Task 数量和输出文件数量。
3. 事后治理 (Post-Processing)
如果小文件已经产生并存储在 HDFS/S3 上,需要通过外部任务进行清理。
定期压缩任务 (Compaction Job)
- 编写一个专门的 Spark 任务,定期(如每天凌晨)读取小文件过多的目录,执行
repartition后覆盖写回(Overwrite)。 - 代码逻辑:
spark.read.parquet("path").repartition(合理数量).write.mode("overwrite").parquet("path")
- 编写一个专门的 Spark 任务,定期(如每天凌晨)读取小文件过多的目录,执行
使用现代数据湖格式 (Delta Lake / Hudi / Iceberg)
- 这是目前最先进的解法。这些格式自带小文件治理功能。
- Delta Lake: 执行
OPTIMIZE table_name [ZORDER BY col]命令,它会自动合并小文件。 - Iceberg: 提供
RewriteDataFilesAction 来压缩文件。 - Hudi: 支持在写入时同步压缩(Inline Compaction)或异步压缩。
总结:最佳实践路线图
- 升级版本:尽量使用 Spark 3.x,开启 AQE,这能自动解决大部分 Shuffle 过程中的小文件问题。
- 写入规范:
- 如果是写文件:计算
repartition(总大小/128M)。 - 如果是写分区表:务必使用
DISTRIBUTE BY 分区字段。
- 如果是写文件:计算
- 架构升级:如果条件允许,引入 Delta Lake 或 Iceberg,将小文件治理交给表格式管理,而不是人工写代码维护。