 播面
播面 Spark 有哪几种 Shuffle 实现机制?
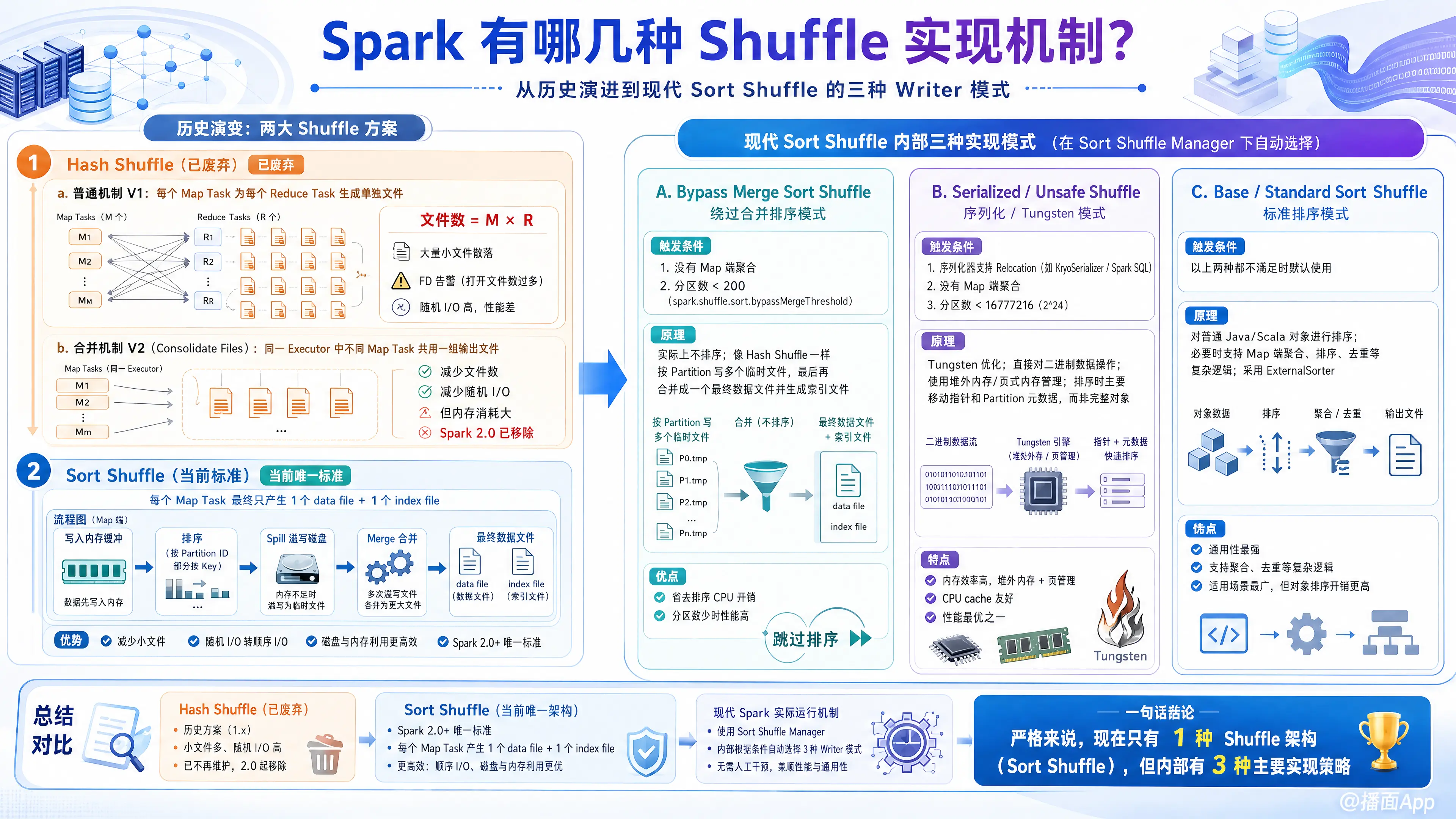
Apache Spark 的 Shuffle 实现机制经历了多次演进。从宏观的历史演变来看,主要分为 Hash Shuffle (已废弃) 和 Sort Shuffle (当前主流) 两大类。
但在目前的 Spark 版本(2.0 及以后)中,实际上只有 Sort Shuffle 这一种架构,但它内部根据不同的条件,会智能选择三种不同的写入策略(Writer Modes)。
以下是详细的分类和原理解析:
一、 历史演变分类
1. Hash Shuffle (已废弃)
这是 Spark 早期(1.2版本之前)的默认机制。
- 普通机制 (V1): 每个 Map Task 会为每个 Reduce Task 生成一个单独的文件。
- 问题: 产生的文件数量是 (Map任务数 Reduce任务数)。如果 Mapper 和 Reducer 各有 1000 个,就会产生 100 万个文件,导致文件描述符(FD)耗尽和大量的随机磁盘 I/O。
- 合并机制 (Consolidate Files, V2): 优化了上述问题,让同一个 Executor 中的不同 Map Task 共用一组输出文件。
- 现状: 由于内存消耗大且难以处理大规模数据,在 Spark 2.0 中已被彻底移除。
2. Sort Shuffle (当前标准)
从 Spark 1.2 开始引入,Spark 2.0 后成为唯一标准。
- 核心逻辑: 每个 Map Task 最终只产生一个数据文件和一个索引文件。
- 过程: 数据先写入内存缓冲,内存满后进行排序(按 Partition ID 排序,部分模式下按 Key 排序),然后溢写(Spill)到磁盘,最后将多个溢写文件合并(Merge)成一个大文件。
- 优势: 极大减少了小文件数量,将随机 I/O 转换为顺序 I/O。
二、 Sort Shuffle 内部的三种实现模式 (重点)
在现代 Spark (2.x, 3.x) 中,Sort Shuffle Manager 会根据任务的具体情况(如是否有聚合、分区数量、序列化方式等),自动选择以下三种 Handle(处理句柄/写入器)之一:
1. Bypass Merge Sort Shuffle (绕过合并排序模式)
- 触发条件:
- 没有 Map 端聚合操作(如
groupByKey,sortByKey等)。 - Shuffle 的分区数(Reducer 数量)少于阈值(默认 200,由
spark.shuffle.sort.bypassMergeThreshold控制)。
- 没有 Map 端聚合操作(如
- 原理:
- 它虽然属于 Sort Shuffle Manager,但实际上不进行排序。
- 它像早期的 Hash Shuffle 一样,为每个 Partition 开辟一个临时文件进行写入。
- 但在最后,它会将这些临时文件合并成一个最终的数据文件,并创建索引文件。
- 优点: 省去了排序的 CPU 开销(因为不需要排序),在分区数少时性能极高。
2. Serialized / Unsafe Shuffle (序列化/Tungsten 模式)
- 触发条件:
- 序列化器支持 Relocation(如 KryoSerializer,或者 Spark SQL 自带的序列化器)。
- 没有 Map 端聚合。
- 分区数少于 ()。
- 原理:
- 这是 Spark Tungsten (钨丝计划) 优化的一部分。
- 它直接在二进制数据(Binary Data)上操作,使用堆外内存(Off-heap)或页式内存管理。
- 排序时只对指针和 Partition ID 进行排序,不反序列化数据。
- 优点: 极大地减少了 Java 对象创建(GC 开销小),内存利用率极高,CPU 缓存命中率高。这是处理 Spark SQL 和 DataFrame 时最常用的模式。
3. Base Shuffle (普通排序模式)
- 触发条件:
- 上述两种模式都不满足时(例如:需要 Map 端聚合,或者使用了不支持 Relocation 的自定义对象)。
- 原理:
- 这是最传统的 Sort Shuffle 实现。
- 使用
ExternalSorter。 - 数据以 Java 对象形式存在于内存中(
Map<Key, Value>结构)。 - 在溢写前需要对 Key 进行排序(如果需要聚合)。
- 特点: 功能最全(支持聚合),但内存和 GC 开销相对较大。
三、 总结对比表
| 机制/模式 | 状态 | 核心特点 | 适用场景 |
|---|---|---|---|
| Hash Shuffle | 已移除 | 不排序,文件数爆炸 | 小规模数据 (旧版本) |
| Sort Shuffle | 默认 | 产生 1 Data + 1 Index 文件 | 所有场景 |
| ├─ Bypass | 内部模式 | 不排序,直接写临时文件后合并 | 分区少 (<200)、无 Map 端聚合 |
| ├─ Serialized | 内部模式 | 二进制排序,Tungsten 优化 | Spark SQL, DataFrame, Kryo 序列化 |
| └─ Base | 内部模式 | 对象排序,支持聚合 | RDD 复杂操作,有 Map 端聚合 |
四、 Spark 3.0+ 的新特性补充
虽然底层写入机制依然是上述三种,但 Spark 3.0+ 引入了新的特性影响 Shuffle 的行为:
- AQE (Adaptive Query Execution): 可以在运行时动态合并 Shuffle 分区(Coalesce Partitions)。虽然写入时还是产生那么多分区,但在读取阶段会将小的分区合并,解决数据倾斜和小文件读取问题。
- Push-based Shuffle (RSS 相关): 针对 YARN 部署环境,Spark 3.2+ 引入了 Push-based Shuffle,允许 Mapper 主动将数据推送到远程的 Shuffle Service 进行预合并,进一步优化大规模 Shuffle 的随机读问题。