 播面
播面 Structured Streaming和 DStream 的区别是什么?
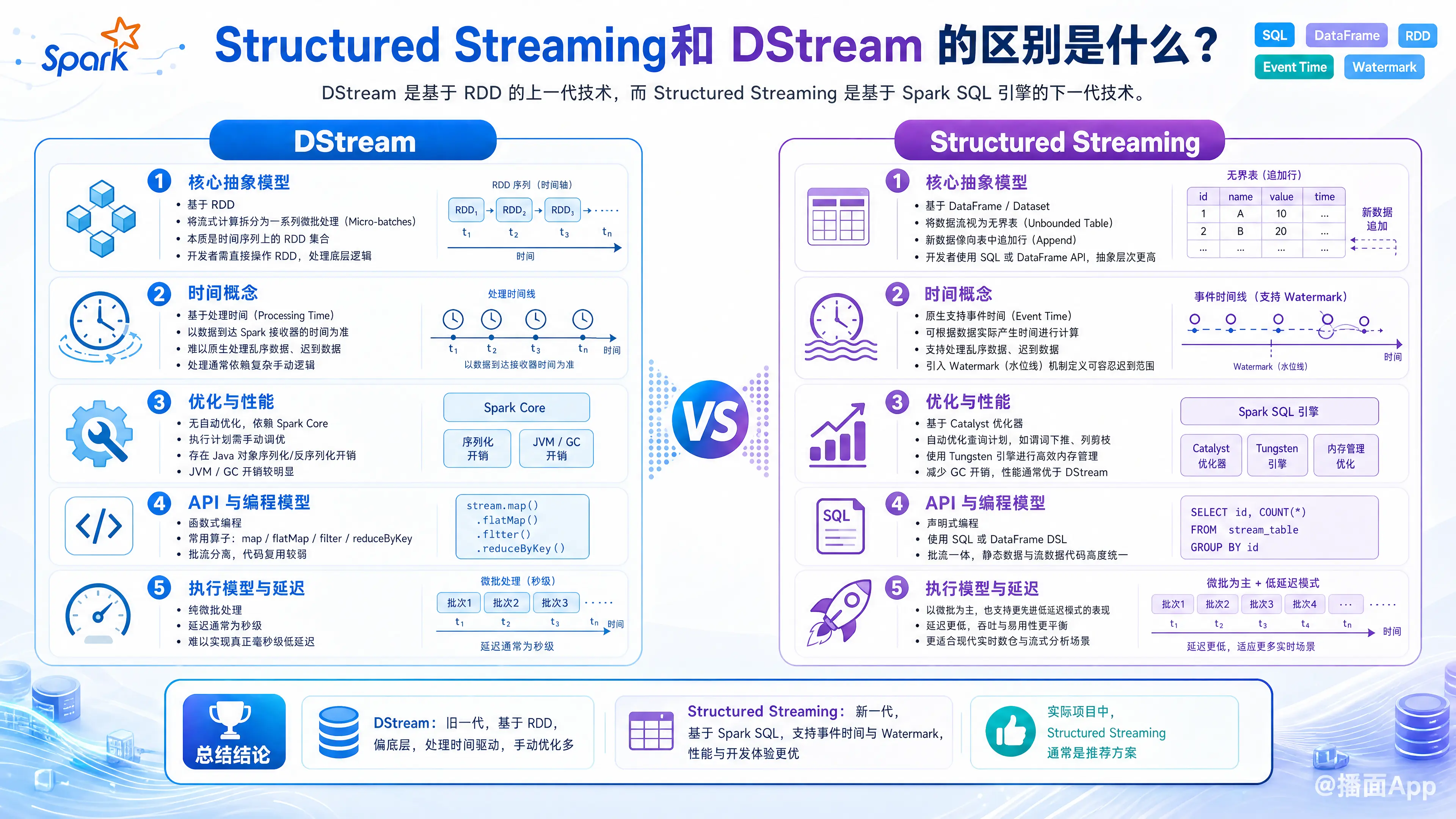
Apache Spark 中的 Structured Streaming (结构化流) 和 DStream (Spark Streaming 的旧 API) 是处理实时数据流的两种不同方式。
简单来说:DStream 是基于 RDD 的上一代技术,而 Structured Streaming 是基于 Spark SQL 引擎的下一代技术。
以下是它们在核心概念、API、性能和功能上的详细区别:
1. 核心抽象模型 (Data Model)
- DStream (Discretized Stream):
- 基于 RDD。它将流式计算分解为一系列微小的批处理作业(Micro-batches)。
- DStream 本质上是一个时间序列上的 RDD 集合。
- 开发者需要直接操作 RDD,处理底层逻辑。
- Structured Streaming:
- 基于 DataFrame / Dataset。它将数据流视为一张无界表 (Unbounded Table)。
- 新数据进来就像是往这张表中追加行 (Append)。
- 开发者使用 SQL 或 DataFrame API 进行操作,抽象层次更高。
2. 时间概念 (Time Handling) —— 最关键的区别之一
- DStream:
- 基于处理时间 (Processing Time)。即数据到达 Spark 接收器的时间。
- 很难处理乱序数据 (Out-of-order data) 和迟到数据 (Late data)。虽然可以通过复杂的逻辑手动处理,但并非原生支持。
- Structured Streaming:
- 原生支持事件时间 (Event Time)。即数据实际产生的时间(通常嵌入在数据内容中)。
- 引入了 Watermark (水位线) 机制,可以自动处理乱序数据,并允许用户定义能够容忍多长时间的迟到数据。
3. 优化与性能 (Optimization)
- DStream:
- 无自动优化。依赖于 Spark Core 引擎。
- 开发者必须自己优化 RDD 的执行计划(例如手动调整分区、序列化方式)。
- 存在 Java 对象序列化/反序列化的开销(JVM Overhead)。
- Structured Streaming:
- 基于 Catalyst 优化器。与 Spark SQL 使用相同的引擎。
- Spark 会自动分析查询计划并进行优化(例如谓词下推、列剪枝)。
- 使用 Tungsten 引擎进行内存管理,直接操作二进制数据,大大减少了 GC 开销,性能通常优于 DStream。
4. API 与 编程模型
- DStream:
- 函数式编程。使用
map,flatMap,filter,reduceByKey等算子。 - 批流分离。流处理代码(DStream)和批处理代码(RDD)虽然相似,但 API 不完全兼容,很难复用同一套代码。
- 函数式编程。使用
- Structured Streaming:
- 声明式编程。使用 SQL 语句或 DataFrame DSL。
- 批流一体。编写流处理代码和批处理代码几乎完全一样。你可以在静态数据上测试代码,然后只需更改输入源即可将其变为流处理应用。
5. 执行模型与延迟 (Latency)
- DStream:
- 纯微批处理 (Micro-batch)。
- 延迟通常在 秒级 (例如 0.5s - 10s)。无法做到真正的毫秒级低延迟。
- Structured Streaming:
- 默认使用 微批处理 (Micro-batch),延迟与 DStream 类似。
- 但它引入了 Continuous Processing (连续处理) 模式(实验性功能),可以实现 毫秒级 的低延迟(At-least-once 语义)。
6. 输出模式 (Sinks) 与 事务语义
- DStream:
- 实现 Exactly-once (精确一次) 语义比较困难,通常需要手动管理 Offset(偏移量)并配合幂等写入。
- Structured Streaming:
- 设计之初就考虑了端到端的 Exactly-once。
- 通过 Checkpoint 和 Write-ahead Logs (WAL) 机制,只要 Sink 端支持(如 Kafka, HDFS, Delta Lake),就能比较容易地实现精确一次写入。
- 提供了三种输出模式:
Append(追加),Update(更新),Complete(全量)。
总结对比表
| 特性 | Spark Streaming (DStream) | Structured Streaming |
|---|---|---|
| 基础抽象 | RDD (DStream) | DataFrame / Dataset |
| API 风格 | 偏底层,函数式 (Map/Reduce) | 高层,声明式 (SQL/DSL) |
| 时间语义 | 处理时间 (Processing Time) | 事件时间 (Event Time) |
| 迟到数据 | 处理困难 | 通过 Watermark 自动处理 |
| 执行引擎 | Spark Core | Spark SQL (Catalyst & Tungsten) |
| 延迟 | 秒级 (微批) | 秒级 (微批) 或 毫秒级 (连续处理) |
| 批流统一 | 代码不通用 | 代码高度统一 |
| 发展状态 | 维护模式 (仅修复Bug) | 主要开发方向 (推荐使用) |
结论:应该选哪个?
- 新项目: 请务必使用 Structured Streaming。它是 Spark 的未来,性能更好,API 更简单,且原生支持事件时间。
- 旧项目: 如果现有的 DStream 运行稳定,且没有复杂的乱序处理需求,可以继续维持。但如果需要重构或有新的复杂业务逻辑,建议迁移到 Structured Streaming。