 播面
播面 Parquet 文件格式有什么特点?为什么 Spark 默认推荐使用它?
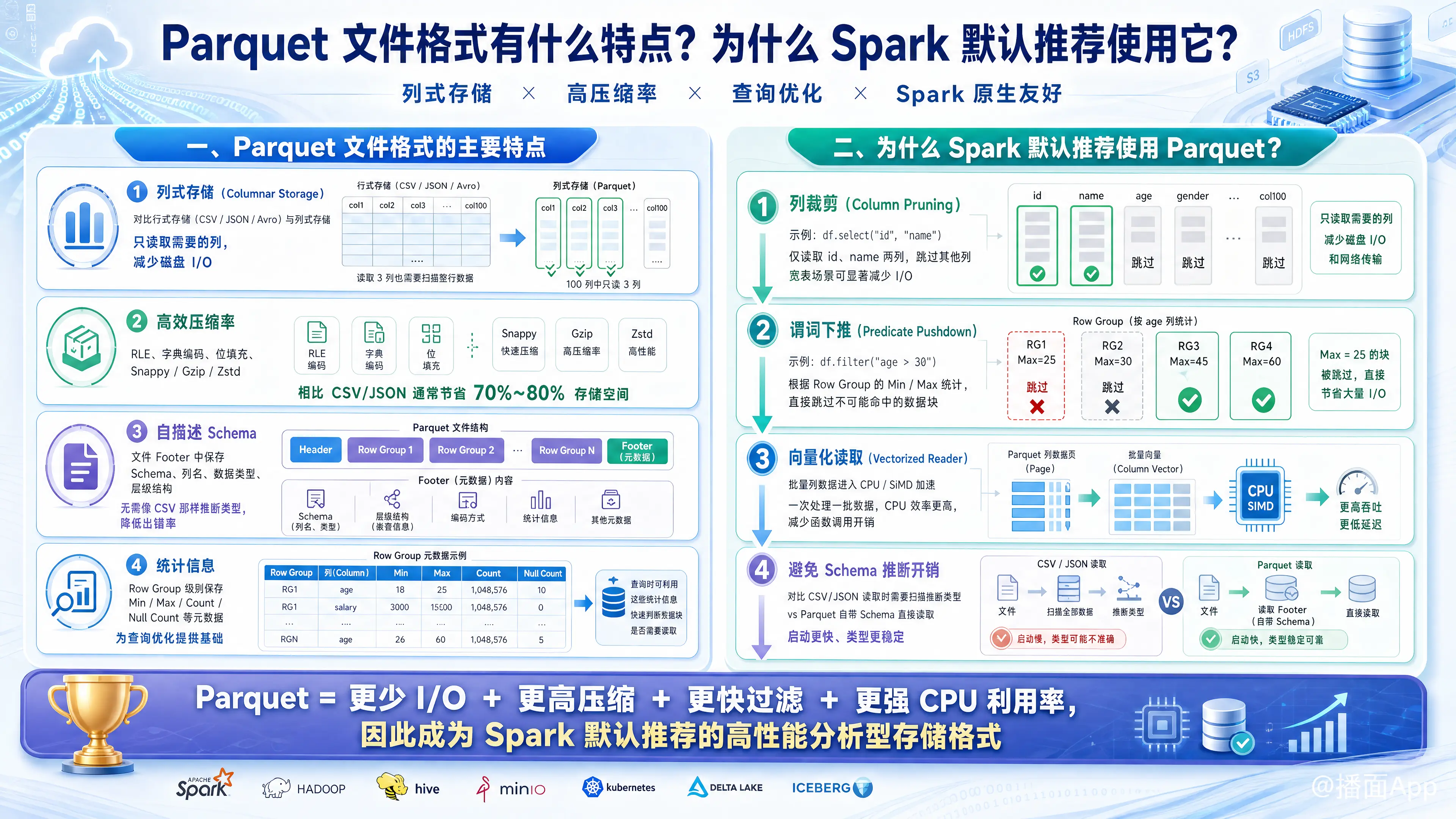
Apache Parquet 是一种开源的列式存储(Columnar Storage)文件格式,专为 Hadoop 生态系统中的大数据处理而设计。
Spark 之所以将其作为默认推荐格式,是因为 Parquet 的设计理念与 Spark 的分布式内存计算模型完美契合,能够极大地提升查询性能并降低存储成本。
以下是 Parquet 的核心特点以及 Spark 推荐使用它的详细原因:
一、 Parquet 文件格式的主要特点
1. 列式存储 (Columnar Storage)
- 传统行式存储 (如 CSV, JSON, Avro): 数据按行连续存储。读取时必须扫描整行数据,即使你只需要其中的一列。
- Parquet 列式存储: 数据按列连续存储。同一列的数据放在一起。
- 优势: 如果你的查询只需要表中的 3 列(共 100 列),Parquet 只需要读取这 3 列的数据块,忽略其他 97 列,极大地减少了磁盘 I/O。
2. 高效的压缩率
- 由于同一列的数据类型是一致的(例如都是整数或都是字符串),Parquet 可以使用针对特定数据类型的轻量级编码算法(如 RLE 游程编码、字典编码、位填充)。
- 在此基础上,还可以应用通用的压缩算法(如 Snappy, Gzip, Zstd)。
- 结果: 相比 CSV 或 JSON,Parquet 文件通常能节省 70% - 80% 的存储空间。
3. 自描述 Schema (Self-describing)
- Parquet 文件在文件末尾(Footer)存储了完整的元数据,包括 Schema 信息(列名、数据类型、层级结构)。
- 读取时不需要像 CSV 那样去推断数据类型,避免了类型转换错误。
4. 包含统计信息 (Statistics)
- Parquet 在文件内部会将数据切分为多个 Row Groups(行组)。
- 在元数据中,它会记录每一列在每个 Row Group 中的统计信息(如 Min, Max, Count, Null Count)。这对于查询优化至关重要。
二、 为什么 Spark 默认推荐使用 Parquet?
Spark 的优化器(Catalyst Optimizer)能够利用 Parquet 的特性实现“飞一般”的查询速度。
1. 列裁剪 (Column Pruning) —— 减少 I/O
当你执行 df.select("id", "name") 时,Spark 会下推指令给 Parquet 读取器。由于 Parquet 是列式存储,Spark 只会从磁盘读取 "id" 和 "name" 这两列的数据块,完全跳过其他列。这在宽表(几百列)查询中能带来几十倍的 I/O 性能提升。
2. 谓词下推 (Predicate Pushdown) —— 智能跳过数据
这是 Parquet 最强大的功能之一。
当你执行 df.filter("age > 30") 时:
- Spark 会查看 Parquet 文件中各个 Row Group 的元数据(Min/Max 统计)。
- 如果某个 Row Group 的
age列记录显示Max = 25,Spark 就会直接跳过整个 Row Group,完全不读取该块数据。 - 这极大地减少了需要扫描的数据量,显著提升过滤查询的速度。
3. 向量化读取 (Vectorized Reader)
Spark 针对 Parquet 实现了向量化读取器。
- 传统的读取是“一次处理一行”。
- 向量化读取利用现代 CPU 的 SIMD(单指令多数据)指令集,可以一次性在内存中解码和处理一批(Batch)列数据。
- 这使得 CPU 的处理效率提高了数倍,减少了函数调用的开销。
4. 避免 Schema 推断的开销
读取 CSV/JSON 时,Spark 通常需要扫描整个文件(或部分文件)来推断每一列的数据类型(是 Int 还是 String?)。这非常耗时且容易出错。
Parquet 自带 Schema,Spark 读取时可以直接构建 DataFrame,启动速度极快。
5. 复杂数据类型支持
Parquet 原生支持嵌套数据结构(如 Map, List, Struct)。Spark SQL 处理这些复杂结构时,Parquet 能够很好地保留层级关系,而不需要像处理扁平化 CSV 那样进行复杂的解析。
三、 总结对比
| 特性 | CSV / JSON (行式) | Parquet (列式) | Spark 场景下的表现 |
|---|---|---|---|
| 可读性 | 人类可读 (文本) | 二进制 (不可读) | Parquet 更好 (机器处理快) |
| 存储空间 | 大 (无压缩或通用压缩) | 极小 (列式压缩) | Parquet 节省存储成本 |
| 读取方式 | 必须读取整行 | 只读取需要的列 | Parquet 极大减少 I/O |
| 查询过滤 | 必须全表扫描 | 利用统计信息跳过数据块 | Parquet 速度极快 (谓词下推) |
| Schema | 需要推断 | 自带元数据 | Parquet 更安全、启动更快 |
一句话总结:
Spark 推荐 Parquet 是因为它是“用空间换时间”(列式存储+压缩)和“智能读取”(谓词下推+列裁剪)的完美结合,能让 Spark 的分析任务运行得更快、更省钱。