 播面
播面 如何自定义 UDF(User Defined Function)和 UDAF(User Defined Aggregate Function)?
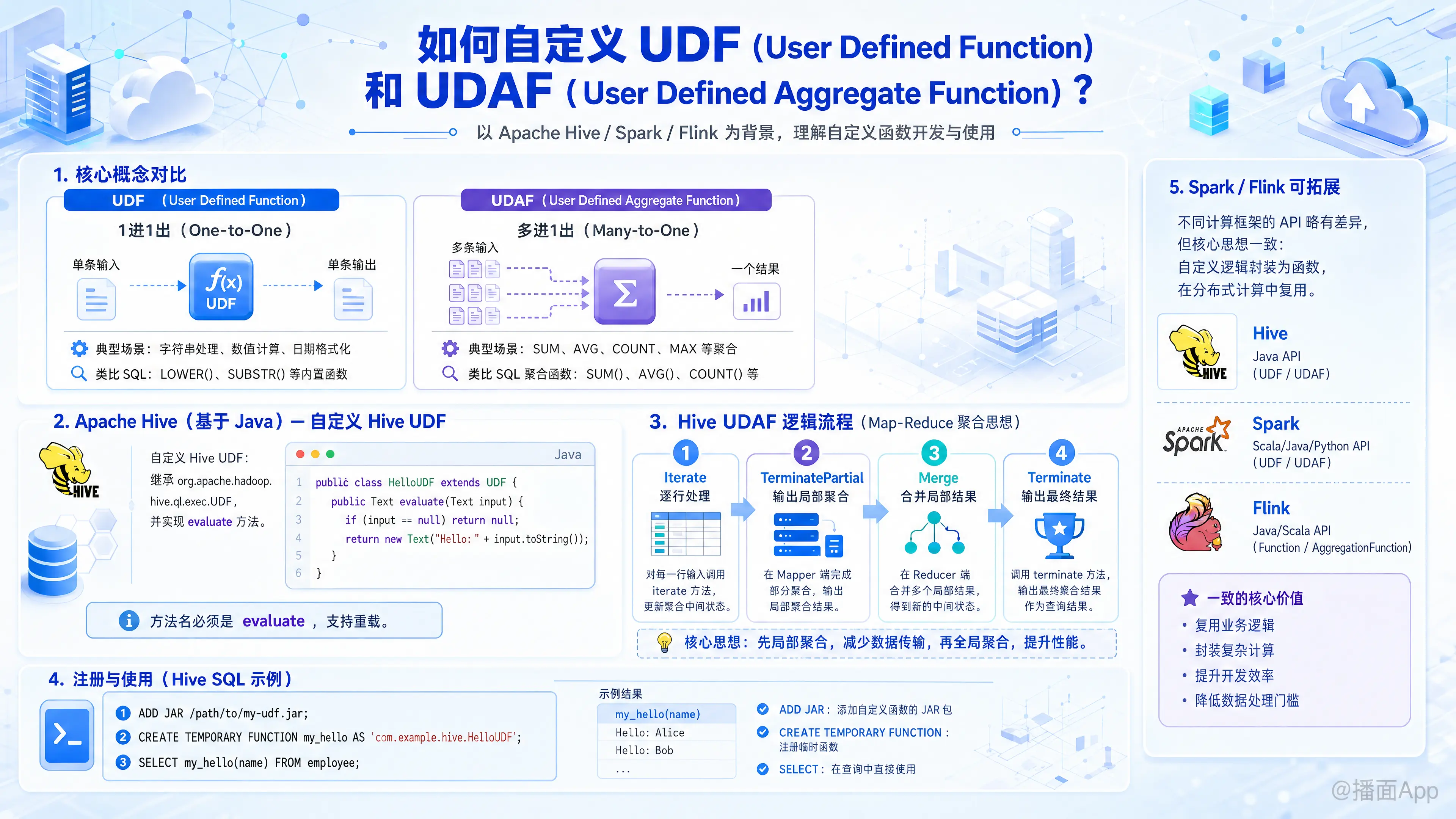
自定义 UDF(User Defined Function)和 UDAF(User Defined Aggregate Function)通常是在大数据处理框架(如 Apache Hive、Apache Spark 或 Flink)中进行的。虽然不同框架的 API 略有不同,但核心思想是一致的。
以下我将以最主流的 Apache Hive(Java)和 Apache Spark(Scala/Python)为例,详细介绍如何定义和使用它们。
核心概念区别
UDF (User Defined Function):
- 输入输出关系: 1 进 1 出 (One-to-One)。
- 场景: 字符串处理(如转大写)、数值计算、日期格式化等。
- 类似 SQL:
LOWER(),SUBSTR().
UDAF (User Defined Aggregate Function):
- 输入输出关系: 多 进 1 出 (Many-to-One)。
- 场景: 统计总和、平均值、最大值等聚合操作。
- 类似 SQL:
COUNT(),SUM(),AVG().
一、Apache Hive (基于 Java)
Hive 是定义 UDF/UDAF 的标准起源,很多 Spark 任务也会兼容 Hive 的 UDF。
1. 自定义 Hive UDF
步骤:继承 org.apache.hadoop.hive.ql.exec.UDF 类,并实现 evaluate 方法。
package com.example.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
// 示例:给字符串添加 "Hello: " 前缀
public class HelloUDF extends UDF {
// 方法名必须是 evaluate,支持重载
public Text evaluate(Text input) {
if (input == null) {
return null;
}
return new Text("Hello: " + input.toString());
}
}2. 自定义 Hive UDAF
Hive 的 UDAF 比较复杂,通常需要继承 AbstractGenericUDAFResolver。核心逻辑分为四个阶段(Map-Reduce 思想):
- Iterate: 在 Map 阶段处理每一行数据。
- TerminatePartial: Map 阶段结束,返回部分聚合结果。
- Merge: 在 Reduce 阶段,合并来自不同 Map 的部分结果。
- Terminate: Reduce 阶段结束,计算并返回最终结果。
(由于 Hive 原生 UDAF 代码冗长,这里仅描述逻辑,具体实现建议参考 Spark 的 Aggregator 或 Hive 官方文档)
3. 注册与使用 (Hive SQL)
编译成 JAR 包后,在 Hive CLI 中执行:
-- 1. 添加 Jar 包
ADD JAR /path/to/my-udf.jar;
-- 2. 创建临时函数
CREATE TEMPORARY FUNCTION my_hello AS 'com.example.hive.HelloUDF';
-- 3. 使用
SELECT my_hello(name) FROM employee;二、Apache Spark (Scala / Java / Python)
Spark 提供了更现代的 API,尤其是 PySpark 和 Spark SQL 的强类型聚合器。
1. Spark UDF (Python - PySpark)
这是最简单的方式,适合快速开发。
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
# 定义 Python 函数
def add_suffix_func(name):
if name:
return name + "_v2"
return None
# 注册 UDF
# 方式 A: 用于 DataFrame API
suffix_udf = udf(add_suffix_func, StringType())
df.select(suffix_udf(df["name"])).show()
# 方式 B: 用于 Spark SQL
spark.udf.register("add_suffix", add_suffix_func, StringType())
spark.sql("SELECT add_suffix(name) FROM table").show()2. Spark UDF (Scala)
import org.apache.spark.sql.functions.udf
// 定义函数
val toUpper = (s: String) => if (s != null) s.toUpperCase else null
// 注册并使用
val toUpperUDF = udf(toUpper)
df.select(toUpperUDF($"name")).show()
// 注册到 SQL
spark.udf.register("to_upper", toUpper)3. Spark UDAF (Scala - 推荐使用 Aggregator)
在 Spark 3.0+ 中,推荐继承 org.apache.spark.sql.expressions.Aggregator,它是强类型的,比旧版 UserDefinedAggregateFunction 更安全、性能更好。
示例:计算平均值 (Average)
import org.apache.spark.sql.{Encoder, Encoders, SparkSession}
import org.apache.spark.sql.expressions.Aggregator
// 1. 定义中间缓存对象 (Buffer)
case class AverageBuffer(sum: Long, count: Long)
// 2. 定义 Aggregator [输入类型, 缓存类型, 输出类型]
object MyAverage extends Aggregator[Long, AverageBuffer, Double] {
// 初始化 Buffer
override def zero: AverageBuffer = AverageBuffer(0L, 0L)
// Map 阶段:处理每一条输入数据
override def reduce(b: AverageBuffer, a: Long): AverageBuffer = {
AverageBuffer(b.sum + a, b.count + 1)
}
// Reduce 阶段:合并两个 Buffer
override def merge(b1: AverageBuffer, b2: AverageBuffer): AverageBuffer = {
AverageBuffer(b1.sum + b2.sum, b1.count + b2.count)
}
// 最终计算
override def finish(reduction: AverageBuffer): Double = {
if (reduction.count == 0) 0 else reduction.sum.toDouble / reduction.count
}
// 编码器设置 (Spark 需要知道如何序列化对象)
override def bufferEncoder: Encoder[AverageBuffer] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
// 3. 使用
import spark.implicits._
val ds = Seq(1L, 2L, 3L, 4L).toDS()
// 方式 A: DSL
val avgValue = ds.select(MyAverage.toColumn.name("average_value"))
// 方式 B: 注册为 SQL 函数
spark.udf.register("my_avg", functions.udaf(MyAverage))
spark.sql("SELECT my_avg(value) FROM table")三、关键注意事项与最佳实践
空值处理 (Null Handling):
- 这是新手最容易犯的错。务必在代码开头检查输入是否为
null,否则会导致 NullPointerException 导致任务失败。
- 这是新手最容易犯的错。务必在代码开头检查输入是否为
性能问题 (Performance):
- 优先使用内置函数: 框架内置函数(如
sum,date_add)通常经过了底层 C++ 或 字节码优化,比 UDF 快得多。 - PySpark UDF: 普通 Python UDF 性能较差(涉及 JVM 和 Python 进程间的数据序列化/反序列化)。
- 优化: 在 PySpark 中,尽量使用 Pandas UDF (Vectorized UDF),它利用 Apache Arrow 进行内存交换,批量处理数据,性能可提升 10-100 倍。
- 优先使用内置函数: 框架内置函数(如
确定性 (Determinism):
- 如果你的 UDF 是确定性的(即输入相同,输出永远相同),数据库引擎可以进行优化。如果是非确定性的(如
random()或current_timestamp()),需要标记为 nondeterministic,否则可能导致查询结果错误。
- 如果你的 UDF 是确定性的(即输入相同,输出永远相同),数据库引擎可以进行优化。如果是非确定性的(如
依赖管理:
- 如果 UDF 依赖第三方库(如 Gson, Apache Commons),打 Jar 包时需要使用
maven-shade-plugin将依赖打进去(Fat Jar),或者在提交任务时通过--jars参数上传依赖。
- 如果 UDF 依赖第三方库(如 Gson, Apache Commons),打 Jar 包时需要使用
总结流程
- 选型: 确定是用 Java (Hive/通用), Scala (Spark 高性能), 还是 Python (Spark 快速开发)。
- 编码:
- UDF: 实现处理逻辑
f(x) = y。 - UDAF: 实现
Init->Iterate->Merge->Result的状态机逻辑。
- UDF: 实现处理逻辑
- 打包: 编译成 Jar 文件(Python 则直接引用 .py 文件)。
- 注册: 在 SQL 会话中
REGISTER或CREATE FUNCTION。 - 调用: 在 SQL 语句中像内置函数一样调用。