 播面
播面 典型的 LLM Agent 架构是怎样的?
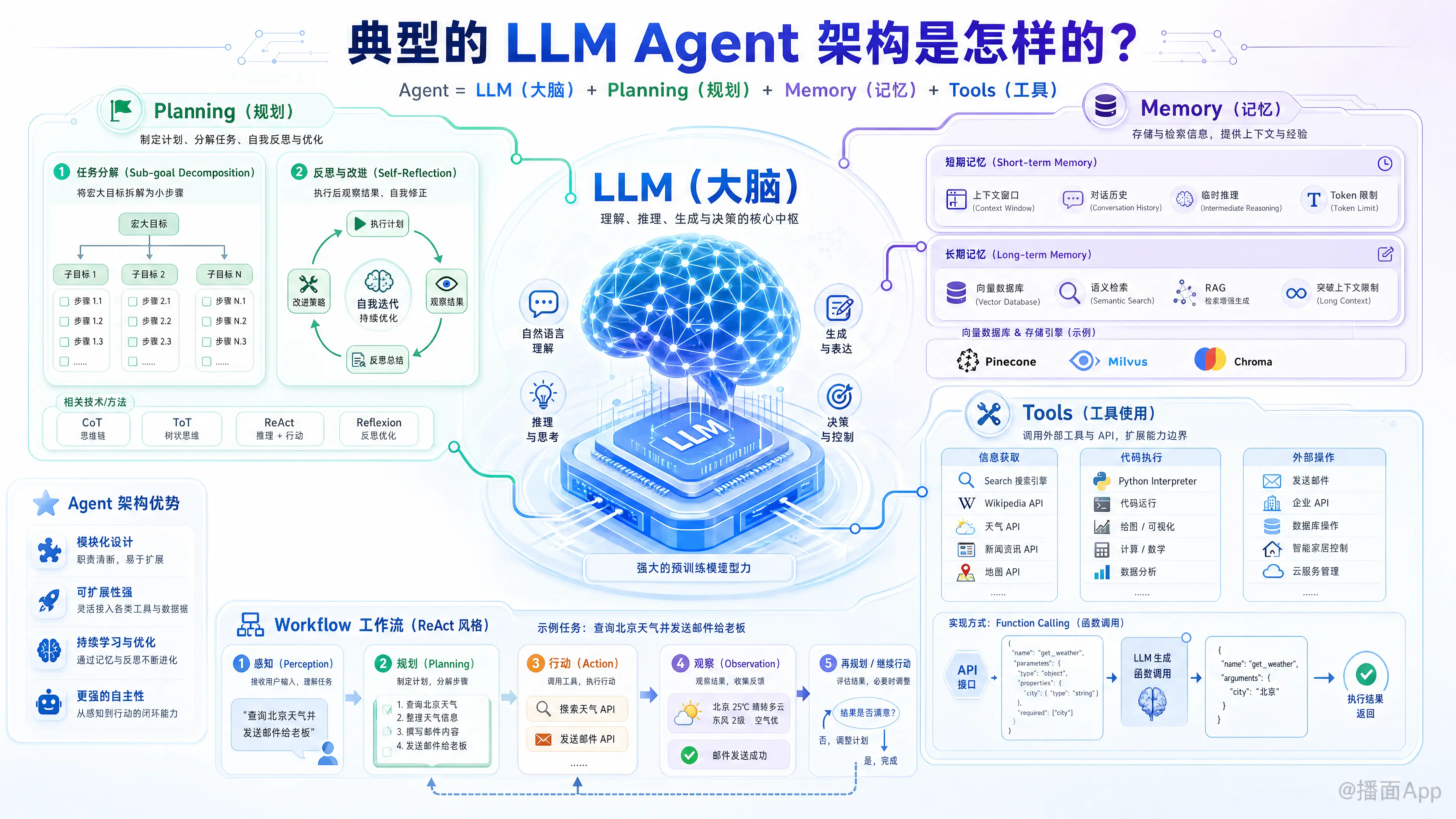
典型的 LLM Agent(大语言模型智能体)架构通常被视为一个以 LLM 为核心大脑,辅以规划(Planning)、记忆(Memory)和工具使用(Tool Use)等模块的综合系统。
目前业界公认最经典的架构参考是 OpenAI 的 Lilian Weng 提出的模型。我们可以将其简化为以下公式:
以下是该架构的详细拆解:
1. 核心大脑:LLM (Large Language Model)
这是 Agent 的指挥中心。它不仅仅负责生成文本,更重要的是负责逻辑推理、决策制定和指令分发。
- 作用:理解用户意图,决定下一步做什么,选择什么工具,以及处理工具返回的结果。
2. 规划模块 (Planning)
如果没有规划,LLM 只是一个问答机器。规划模块让 Agent 具备解决复杂任务的能力。
- 任务分解 (Sub-goal Decomposition):
- 将一个宏大的目标(例如“写一个贪吃蛇游戏”)拆解为更小、可执行的步骤(生成代码、编写测试、创建UI)。
- 技术手段:Chain of Thought (CoT, 思维链), Tree of Thoughts (ToT, 思维树)。
- 反思与改进 (Self-Reflection):
- Agent 在执行过程中会观察结果,自我批评并修正错误。
- 技术手段:ReAct (Reason + Act), Reflexion (失败后自我反思)。
3. 记忆模块 (Memory)
LLM 本身是无状态的,记忆模块让 Agent 能够从过往经验中学习并保持上下文连贯。
- 短期记忆 (Short-term Memory):
- 即上下文窗口 (Context Window)。
- 存储当前的对话历史、临时的推理过程。受限于 Token 长度。
- 长期记忆 (Long-term Memory):
- 通常通过向量数据库 (Vector Database) 实现(如 Pinecone, Milvus, Chroma)。
- Agent 可以将海量的文档、过去的经验存储起来,在需要时通过语义检索(RAG)提取相关信息,从而突破 Context Window 的限制。
4. 工具使用 (Tool Use / Action)
这是 Agent 与外部世界交互的“手”和“眼”。LLM 的训练数据是截止到过去的,且无法直接操作软件,工具层解决了这个问题。
- 能力范围:
- 信息获取:Google Search, Wikipedia API (获取最新信息)。
- 代码执行:Python Interpreter (进行复杂计算、绘图)。
- 外部操作:发送邮件、调用企业 API、操作数据库、控制智能家居。
- 实现方式:
- Function Calling:OpenAI 等模型原生支持的格式,LLM 输出结构化的 JSON 来指定要调用的函数和参数。
典型的 Agent 工作流 (Workflow)
一个标准的 Agent 处理任务的流程通常是这样的(以 ReAct 模式为例):
- 感知 (Perception):用户输入指令(例如:“帮我查一下今天北京的天气,并发邮件给老板”)。
- 规划 (Planning):
- LLM 思考:首先需要获取天气信息,然后撰写邮件,最后发送。
- 行动 (Action - 查天气):
- LLM 选择工具:
Weather_API。 - 生成参数:
location="Beijing"。
- LLM 选择工具:
- 观察 (Observation):
- 工具返回结果:
"Beijing: Sunny, 25°C"。
- 工具返回结果:
- 规划 (Planning - 更新):
- LLM 思考:拿到天气了,现在需要写邮件并发出去。
- 行动 (Action - 发邮件):
- LLM 选择工具:
Email_API。 - 生成内容:
To="Boss", Body="Today is sunny..."。
- LLM 选择工具:
- 响应 (Response):
- 任务完成,向用户反馈:“邮件已发送。”
进阶架构:多智能体 (Multi-Agent)
随着技术发展,单体 Agent 容易陷入死循环或能力不足。现在的趋势是 Multi-Agent Systems (MAS)。
- 架构特点:多个扮演不同角色的 Agent 协作。
- 角色分工:
- Product Manager Agent:负责拆解需求。
- Coder Agent:负责写代码。
- Reviewer Agent:负责检查代码 bug。
- 优势:专业分工,互相监督,效果通常优于单个全能 Agent。
- 代表框架:Microsoft AutoGen, CrewAI, MetaGPT。
总结
典型的 LLM Agent 架构就是:
“大脑 (LLM) + 记忆 (Vector DB) + 规划 (Prompt Engineering/CoT) + 工具 (APIs)”。
它将大模型从一个被动的“文本生成器”转变为一个主动的“任务执行者”。