 播面
播面 Agent 中的「思考(Reasoning)」与「行动(Action)」如何协同?
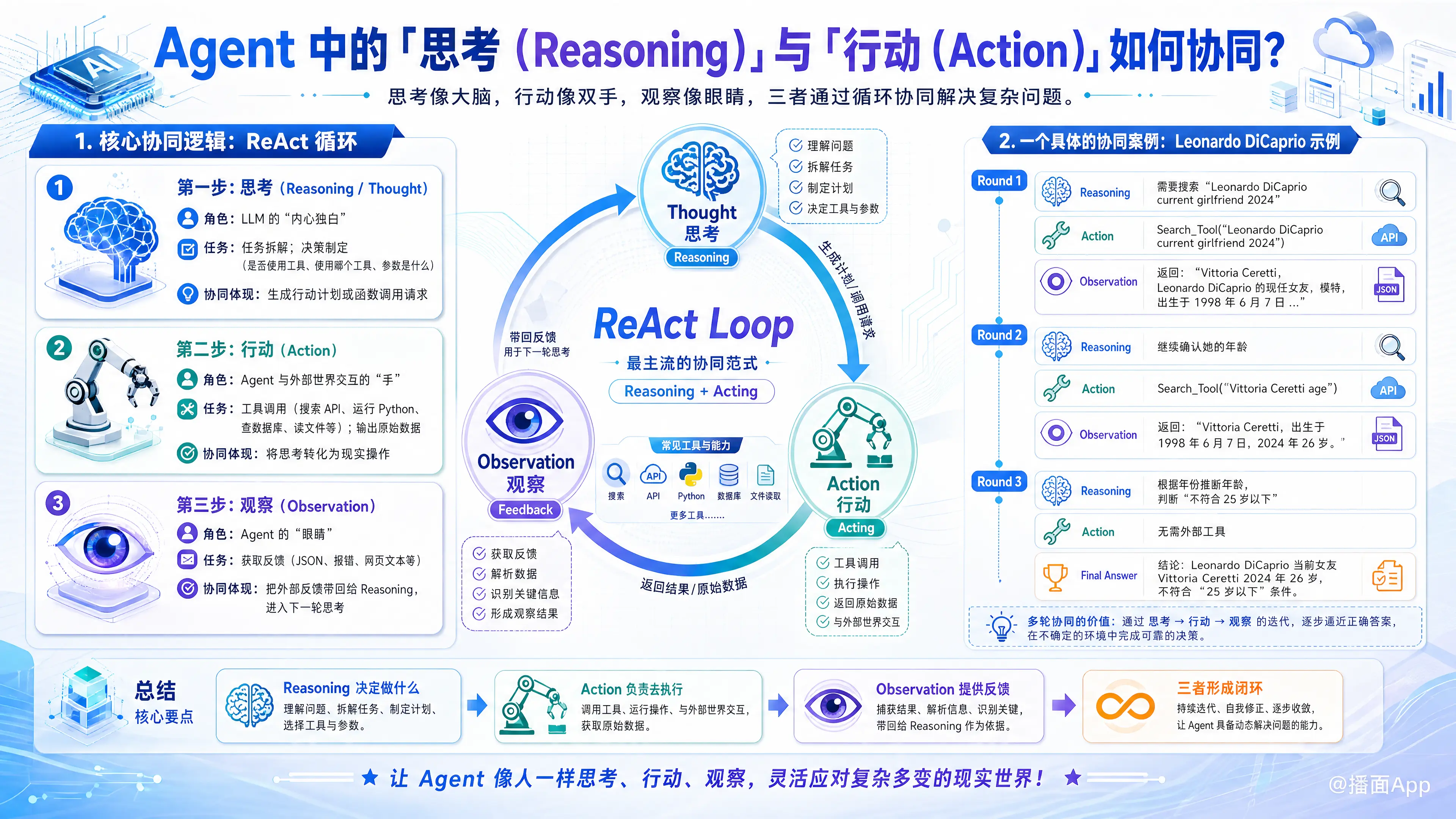
在 AI Agent(智能体)的架构中,「思考(Reasoning)」与「行动(Action)」的关系就像是大脑与手的关系。它们通过一个不断的循环(Loop)来协同工作,从而解决那些仅靠大模型(LLM)内部知识无法解决的复杂问题。
目前最主流的协同范式被称为 ReAct (Reasoning + Acting)。以下是它们协同工作的详细机制解析:
1. 核心协同逻辑:ReAct 循环
Agent 的工作流程通常不是线性的(一次性生成),而是一个迭代的闭环。这个闭环通常包含三个关键步骤:Thought(思考) Action(行动) Observation(观察)。
第一步:思考 (Reasoning/Thought)
- 角色:这是 LLM 的“内心独白”。
- 任务:
- 任务拆解:面对用户复杂的问题(例如“查询今天北京的天气并建议穿搭”),LLM 首先分析需要做什么。
- 决策制定:判断当前是否需要使用工具?需要使用哪个工具?参数是什么?
- 协同体现:思考的结果是生成一个“行动计划”或具体的“函数调用请求”。
第二步:行动 (Action)
- 角色:这是 Agent 与外部世界交互的“手”。
- 任务:
- 工具调用:根据上一步思考的指令,实际执行操作。例如:调用 Google Search API、运行 Python 代码、查询数据库、读取文件等。
- 输出生成:行动本身不产生最终答案,而是产生原始数据。
- 协同体现:行动将“思考”转化为现实世界的操作。
第三步:观察 (Observation)
- 角色:这是 Agent 的“眼睛”。
- 任务:
- 获取反馈:捕获行动(Action)执行后的返回结果(例如 API 返回的 JSON 数据、代码运行的报错信息、网页的文本内容)。
- 协同体现:观察将外部世界的反馈带回给大脑(Reasoning),作为下一轮思考的依据。
2. 一个具体的协同案例
假设用户问:“莱昂纳多·迪卡普里奥现在的女朋友是谁?她的年龄也是 25 岁以下吗?”
LLM 无法直接回答(因为知识库截止或不包含实时八卦),Agent 会这样协同:
Round 1:
- 思考 (Reasoning): 用户问的是莱昂纳多的现任女友。我无法直接回答,我需要搜索一下“Leonardo DiCaprio current girlfriend 2024”。
- 行动 (Action): 调用
Search_Tool("Leonardo DiCaprio current girlfriend 2024")。 - 观察 (Observation): 搜索工具返回结果:“...Vittoria Ceretti is currently dating Leonardo..."
Round 2:
- 思考 (Reasoning): 我找到了名字是 Vittoria Ceretti。现在我需要确认她的年龄,看是否在 25 岁以下。
- 行动 (Action): 调用
Search_Tool("Vittoria Ceretti age")。 - 观察 (Observation): 搜索工具返回结果:“...born June 7, 1998 (age 25)...” (假设当前时间计算后为25或26)。
Round 3:
- 思考 (Reasoning): 我知道了她出生于 1998 年。现在是 2024 年,她应该是 26 岁。这不符合“25 岁以下”的条件。
- 行动 (Action): 无需外部工具,直接生成最终答案。
- 最终回答 (Final Answer): 莱昂纳多现在的女朋友是 Vittoria Ceretti。她目前 26 岁,所以不是 25 岁以下。
3. 协同的关键技术细节
为了让“思考”和“行动”顺畅配合,Agent 架构中通常包含以下机制:
A. 提示词工程 (System Prompt)
开发者会在系统提示词中规定格式,告诉 LLM:“你是一个有用的助手。当你需要解决问题时,请遵循 Thought -> Action -> Observation 的格式。”
这迫使 LLM 在行动前先输出思考过程,这被称为 Chain-of-Thought (CoT),能显著提高行动的准确率。
B. 上下文记忆 (Context Memory)
协同的关键在于记忆。
Agent 会将 Round 1 的思考、行动和观察结果全部拼接到对话历史中,作为 Round 2 的输入。
- 如果没有记忆,Agent 在查完名字后,就会忘记自己为什么要查名字,无法进行下一步查年龄的操作。
C. 错误修正 (Self-Correction/Reflection)
如果“行动”失败了怎么办?
- 行动:调用计算器工具,因为格式错误报错了。
- 观察:返回
Error: Invalid syntax. - 思考:LLM 看到报错信息,进行反思:“啊,我输入的格式不对。我应该重新尝试正确的格式。”
- 新行动:再次调用工具,使用正确格式。
这种“思考-报错-反思-重试”的机制是 Agent 鲁棒性的核心。
4. 不同的协同模式
除了标准的 ReAct,还有其他协同方式:
Plan-and-Solve (先计划再执行):
- 思考:先一次性列出所有步骤(1. 查名字 2. 查年龄 3. 比对)。
- 行动:依次执行,或者并行执行。
- 适用场景:任务链路清晰,不需要根据中间结果动态调整的任务。
ToT (Tree of Thoughts) + Tools:
- 思考:LLM 生成多个可能的行动路径,自我评估哪个路径最靠谱。
- 行动:选择最佳路径执行。
- 适用场景:需要深度推理和探索的复杂难题。
总结
Agent 中“思考”与“行动”的协同,本质上是将 LLM 的语义理解能力(大脑)与 外部工具的执行能力(手)通过“观察反馈”连接起来。
- 思考指导行动(提供方向和参数)。
- 行动滋养思考(提供实时数据和反馈)。
这种循环让静态的 LLM 变成了动态的、能解决实际问题的智能体。