 播面
播面 Spark 的运行架构(Master/Worker, Driver/Executor)
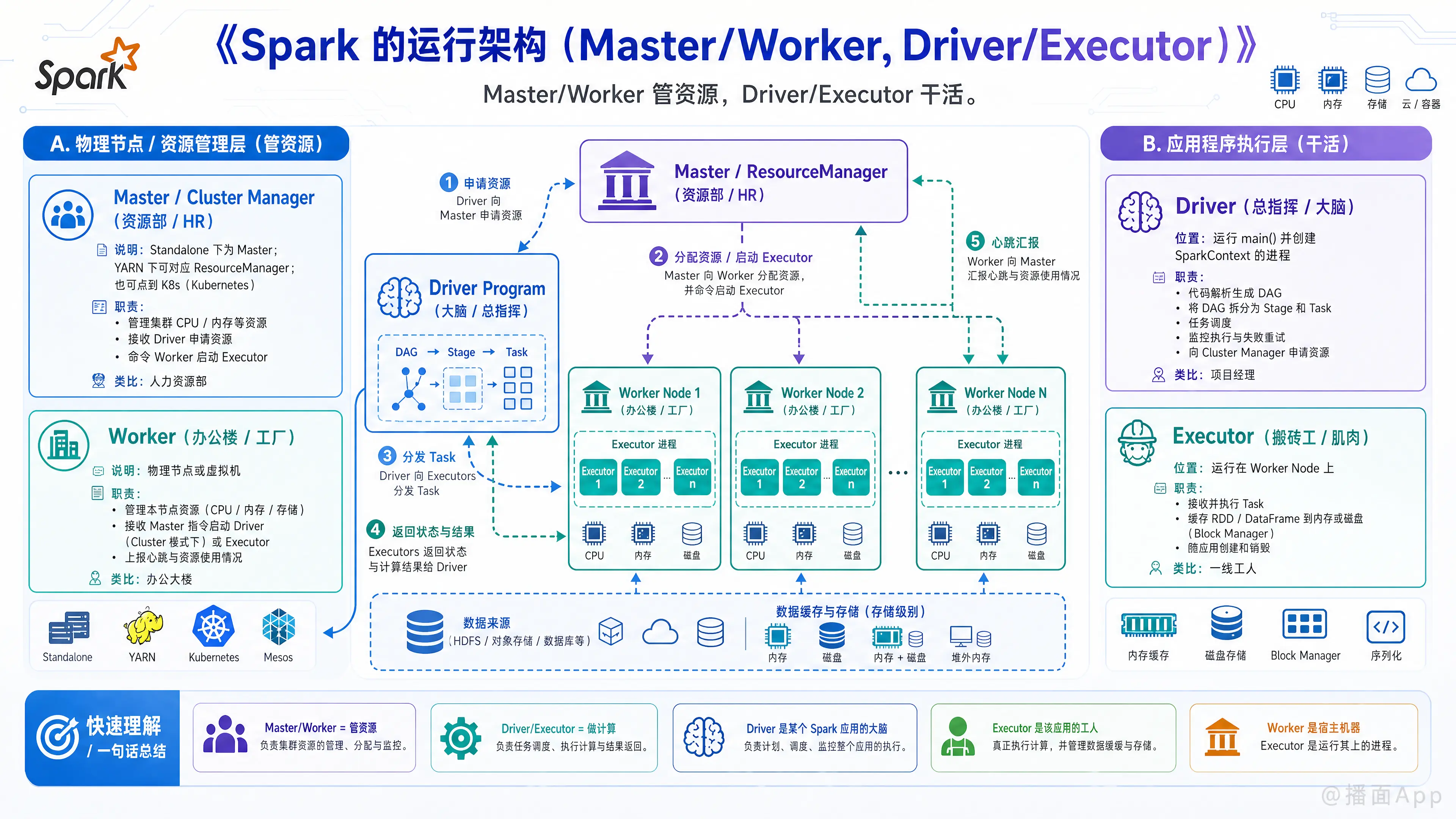
Apache Spark 的运行架构是一个典型的 Master-Slave (主从) 结构。为了理解清楚,我们需要把架构分为两个维度来看:
- 物理节点/资源管理层:Master 和 Worker(负责管资源)。
- 应用程序执行层:Driver 和 Executor(负责干活)。
以下是详细的架构解析:
一、 核心组件详解
1. Driver (驱动器) —— "总指挥 / 大脑"
Driver 是 Spark 作业的入口,是整个应用的控制中心。
- 位置:运行
main()函数并创建SparkContext的进程。 - 主要职责:
- 代码解析:将用户写的代码(算子)转换成逻辑执行图(DAG)。
- 任务调度:将 DAG 拆分成 Stage(阶段),再拆分成 Task(任务),分发给 Executor 执行。
- 监控:监控 Task 的执行状态,失败重试。
- 资源申请:向 Cluster Manager 申请资源(Executor)。
- 类比:项目经理。他制定计划,把大项目拆分成小任务,分发给员工,并监督进度。
2. Executor (执行器) —— "搬砖工 / 肌肉"
Executor 是运行在工作节点(Worker)上的一个进程,专门为某个 Spark 应用服务。
- 位置:运行在 Worker Node 上。
- 主要职责:
- 执行任务:接收 Driver 发来的 Task 并执行计算。
- 数据存储:负责将数据(RDD/DataFrame)缓存在内存或磁盘中(Block Manager)。
- 生命周期:Executor 在应用启动时创建,应用结束时销毁。
- 类比:一线工人。干具体的活,把干活需要的材料(数据)放在手边。
3. Master / Cluster Manager (集群管理器) —— "资源部 / HR"
根据部署模式不同(Standalone, YARN, K8s),名称可能不同,但功能一致。
- Master (Standalone模式) / ResourceManager (YARN模式)。
- 主要职责:
- 管理整个集群的物理资源(CPU、内存)。
- 接收 Driver 的资源申请,并命令 Worker 启动 Executor。
- 类比:公司的人力资源部。不参与具体项目细节,只负责给项目组分配办公室和工位。
4. Worker (工作节点) —— "办公楼 / 工厂"
集群中的物理节点或虚拟机。
- 主要职责:
- 管理当前节点的资源。
- 接收 Master 的指令,启动 Driver(Cluster模式下)或 Executor 进程。
- 向 Master 汇报心跳和资源使用情况。
- 类比:具体的办公大楼。里面有很多工位(资源),可以容纳很多工人(Executor)。
二、 架构关系图解
plaintext
graph TD
subgraph Cluster_Manager [资源管理层]
Master[Master / ResourceManager]
Worker1[Worker Node 1]
Worker2[Worker Node 2]
end
subgraph Application [应用执行层]
Driver[Driver Program]
Exec1[Executor 1]
Exec2[Executor 2]
end
%% 关系连线
Driver --1.申请资源--> Master
Master --2.指令启动Executor--> Worker1
Master --2.指令启动Executor--> Worker2
Worker1 --启动--> Exec1
Worker2 --启动--> Exec2
Driver --3.发送Task / 监控--> Exec1
Driver --3.发送Task / 监控--> Exec2
Exec1 --4.汇报状态 / 结果--> Driver
Exec2 --4.汇报状态 / 结果--> Driver三、 运行流程 (Step-by-Step)
- 提交应用:使用
spark-submit提交任务。 - 启动 Driver:Driver 进程启动,初始化
SparkContext。 - 注册申请:Driver 向 Master (Cluster Manager) 注册,并申请资源(CPU/内存)。
- 分配资源:Master 通知 Worker 节点启动 Executor 进程。
- 反向注册:Executor 启动后,会主动向 Driver 反向注册(这样 Driver 就知道谁在为它干活了)。
- 任务分发:
- Driver 解析代码,生成 DAG 图。
- 划分 Stage 和 Task。
- Driver 将 Task 发送到 Executor 上执行(尽量遵循“数据本地化”原则,即移动计算不移动数据)。
- 执行与反馈:Executor 执行 Task,并将状态和结果反馈给 Driver。
- 回收资源:任务完成后,Driver 关闭
SparkContext,Master 回收 Executor 资源。
四、 关键区别:Client 模式 vs Cluster 模式
理解 Driver 在哪里运行非常重要:
| 特性 | Client 模式 (客户端模式) | Cluster 模式 (集群模式) |
|---|---|---|
| Driver 运行位置 | 提交任务的本地机器 | 集群中的某个 Worker 节点 |
| 网络流量 | Driver 和集群间有大量网络通信 | 通信都在集群内部,流量快 |
| 客户端断开影响 | 提交窗口关闭,任务挂掉 | 提交后窗口关闭,任务继续运行 |
| 适用场景 | 开发、调试、交互式查询 (能立刻看到日志) | 生产环境 (稳定,不依赖客户端网络) |
五、 总结:一句话概括
- Master/Worker 是物理层面的概念,负责搭建台子(管理集群资源)。
- Driver/Executor 是逻辑层面的概念,负责唱戏(执行具体代码)。
Driver 向 Master 要资源,Master 让 Worker 腾出地方运行 Executor,最后 Driver 指挥 Executor 干活。