 播面
播面 Flink 的网络通信模型是怎样的?
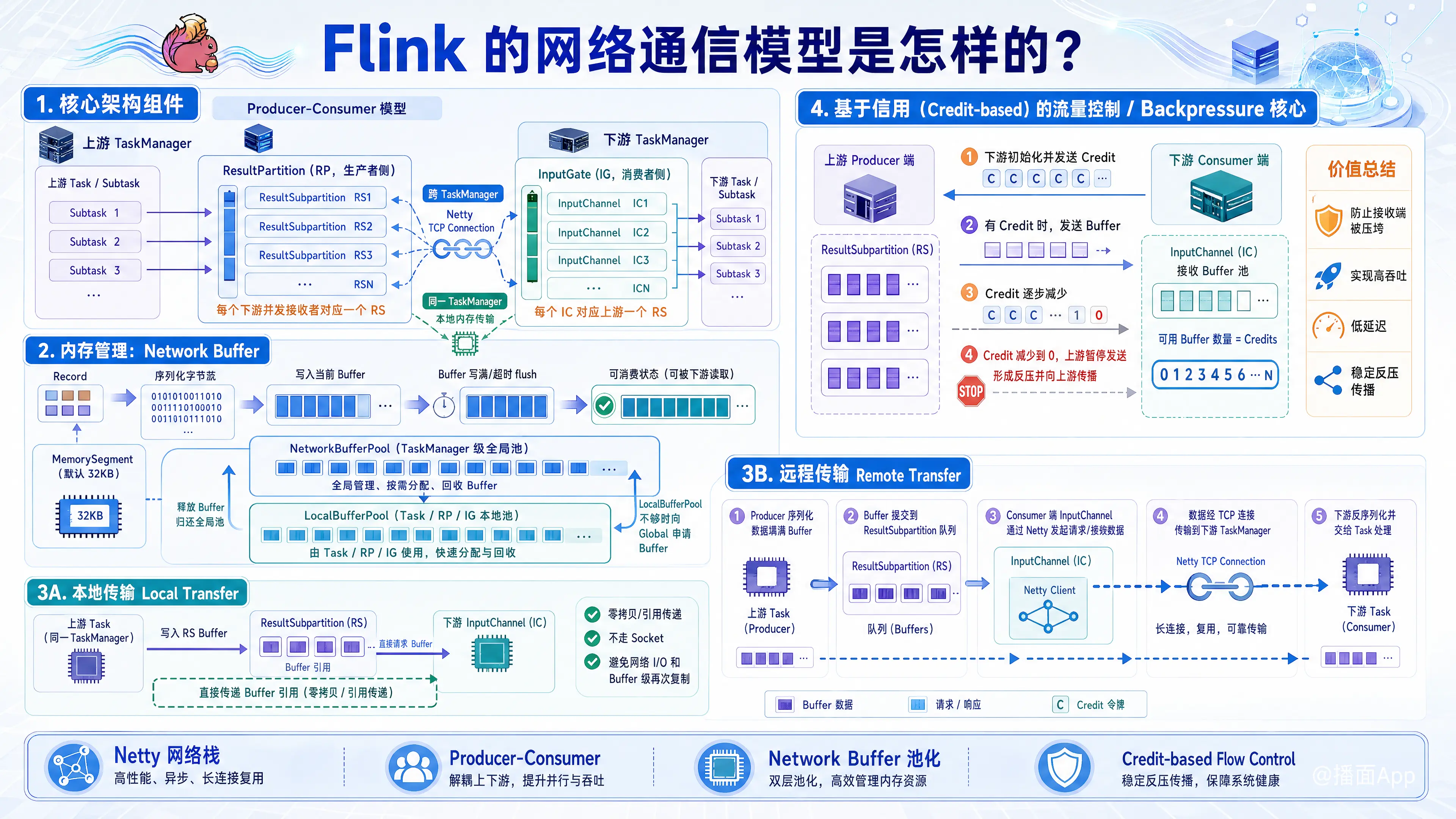
Flink 的网络通信模型是其能够实现高吞吐、低延迟以及强大的反压(Backpressure)机制的核心。简单来说,Flink 的网络栈基于 Netty 实现,采用 Producer-Consumer(生产者-消费者) 模式,并结合了 基于信用(Credit-based)的流量控制 机制。
以下是 Flink 网络通信模型的详细解析,分为架构组件、数据传输流程、内存管理和流量控制四个部分。
1. 核心架构组件
在 Flink 的任务执行中,数据在不同的 Task 之间传输(例如从 Map 到 Reduce)。核心抽象如下:
ResultPartition (RP - 生产者侧):
- 每个发送数据的 Task(Subtask)都会产生一个
ResultPartition。 - RP 负责持有该 Task 产生的数据,等待下游消费。
- RP 被进一步切分为多个 ResultSubpartition (RS)。如果下游有 N 个并发任务,那么 RP 通常会有 N 个 RS,每个 RS 对应下游的一个特定接收者。
- 每个发送数据的 Task(Subtask)都会产生一个
InputGate (IG - 消费者侧):
- 每个接收数据的 Task 都有一个
InputGate。 - IG 负责从上游拉取数据并交给 Task 处理。
- IG 包含多个 InputChannel (IC)。每个 IC 对应上游的一个 ResultSubpartition。
- 每个接收数据的 Task 都有一个
Netty Connection:
- 当上下游 Task 位于不同的 TaskManager (TM) 时,数据通过 Netty 的 TCP 连接传输。
- 同一个 TM 之间的不同 Task 传输则直接通过本地内存拷贝,不走网络。
2. 内存管理:Network Buffer
Flink 网络传输的基本单位不是一条条记录(Record),而是 Network Buffer(网络缓冲区)。
- MemorySegment: 这是 Flink 内存管理的最小单元(默认 32KB)。
- 序列化与打包:
- 上游 Task 产生的 Record 首先被序列化。
- 序列化后的字节流被写入
ResultSubpartition中的当前 Buffer。 - 当 Buffer 写满(或超时触发 flush)时,该 Buffer 变为“可消费”状态,准备发送。
- Buffer Pool:
- NetworkBufferPool: TM 级别的全局内存池。
- LocalBufferPool: 每个 Task (RP 或 IG) 独占的本地内存池。
- Task 会从 LocalBufferPool 申请 Buffer,不够时 Local 会向 Global 申请。
3. 数据传输流程
数据传输分为 本地传输 和 远程传输 两种情况。
A. 本地传输 (Local Transfer)
当上游 Task 和下游 Task 在同一个 TaskManager 进程内运行时:
- 上游 Task 将数据写入
ResultSubpartition的 Buffer。 - 下游 Task 的
InputChannel直接向该 RS 请求 Buffer。 - 零拷贝/引用传递: 实际上不需要通过 Socket,Buffer 的引用直接被传递给下游,避免了网络 I/O 和序列化开销(虽然 Record 级序列化仍存在,但 Buffer 级无需再次复制)。
B. 远程传输 (Remote Transfer)
当上游和下游在不同的 TaskManager 时,流程如下:
- 上游 (Producer):
- Task 序列化数据填满 Buffer。
- Buffer 被提交到
ResultSubpartition。 - Netty 的 Server 端线程(PartitionRequestQueue)检测到有数据,将 Buffer 拷贝到 Netty 的 Direct Buffer 中并通过 Socket 发送。
- 网络 (Network):
- 数据通过物理网络传输。
- Flink 尽量复用 TCP 连接(多个 Subtask 共享同一个 TM 到 TM 的 TCP 连接),减少连接数。
- 下游 (Consumer):
- Netty Client 端线程从 Socket 读取数据。
- 数据被解码并拷贝到下游
InputChannel申请到的 Network Buffer 中。 - Buffer 填满后,通知下游 Task 线程进行反序列化和处理。
4. 流量控制:基于信用的反压机制 (Credit-based Flow Control)
这是 Flink 网络模型中最精彩的部分。在 Flink 1.5 之前,Flink 依赖 TCP 本身的滑动窗口机制进行反压,但这会导致 “阻塞所有通道” 的问题(即一个 Subtask 阻塞导致整个 TCP 连接上的其他 Subtask 也被阻塞)。
Flink 1.5+ 引入了应用层的 Credit-based Flow Control:
- Credit(信用/配额): 下游(InputChannel)会告诉上游(ResultSubpartition)自己当前有多少个空闲的 Buffer(即 Credit)。
- 发送条件: 上游只有在 Credit > 0 时才会发送数据。每发送一个 Buffer,Credit 减 1。
- Backlog(积压量): 上游发送数据时,会在包头附带
Backlog大小,告诉下游:“我这里还积压了多少个 Buffer 等着发”。 - 动态调整: 下游根据上游的 Backlog,动态去申请更多的 Buffer(如果有余量),并更新 Credit 给上游。
优势:
- 精细化反压: 只有处理慢的 Subtask 对应的上游会被限流,不会阻塞同一 TCP 连接上的其他健康 Subtask。
- Checkpoints 不受阻: 即使数据流被反压阻塞,Checkpoint 的 Barrier 依然可以通过特殊的通道优先传输,保证 Checkpoint 不会因为反压而超时失败。
5. 总结:Flink 网络模型的特点
- 基于 Netty NIO: 异步非阻塞,高性能。
- 面向 Buffer: 批量传输,提高吞吐量,减少系统调用。
- 多路复用: 多个 Subtask 复用同一个 TaskManager 之间的 TCP 连接。
- Credit-based 反压: 解决了 TCP 反压粒度太粗的问题,实现了更平滑、更稳定的流控。
- 低延迟与高吞吐的平衡:
- Flush 机制: 为了降低延迟,Flink 允许配置
buffer-timeout(默认 100ms)。即使 Buffer 没满,时间到了也会强制发送,从而在低延迟和高吞吐之间取得平衡。
- Flush 机制: 为了降低延迟,Flink 允许配置
这个模型确保了 Flink 既能处理大规模吞吐的历史数据,也能处理毫秒级延迟的实时数据,同时在系统过载时通过反压机制优雅地降级,而不是崩溃。