 播面
播面 Flink 的内存模型(Memory Model)
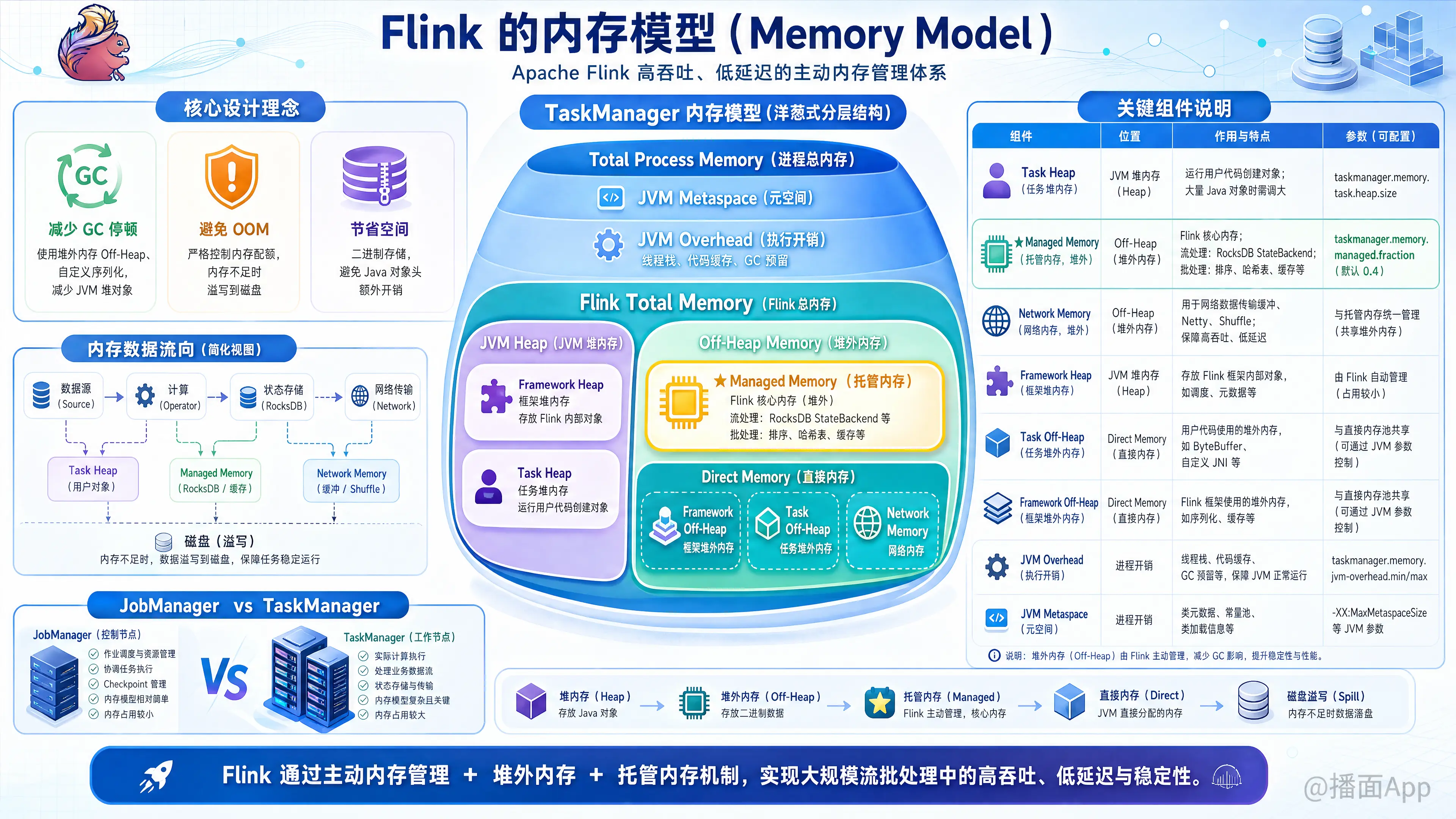
Apache Flink 的内存模型是其能够高效处理大规模数据流、保证高吞吐和低延迟的关键所在。
在 Flink 1.10 版本之后,社区对内存模型进行了重构,引入了更细粒度的内存控制。Flink 的内存管理主要分为 JobManager(控制节点) 和 TaskManager(工作节点) 两部分,其中 TaskManager 的内存模型最为复杂且关键。
以下是 Flink 内存模型的详细解析:
一、 核心设计理念
Flink 并没有完全依赖 JVM 的垃圾回收(GC)机制来管理内存,而是主动管理内存。这样做主要有三个目的:
- 减少 GC 停顿:通过使用堆外内存(Off-Heap)和自定义的序列化机制,减少存活在 JVM 堆上的对象数量。
- 避免 OOM(内存溢出):严格控制内存使用配额,当内存不足时将数据溢写到磁盘,而不是导致程序崩溃。
- 节省空间:通过二进制存储数据,避免了 Java 对象头带来的额外开销。
二、 TaskManager 内存模型 (重点)
TaskManager 是执行作业实际计算逻辑的地方。它的内存布局可以看作一个洋葱结构,从外到内层层包裹。
1. 总体层级结构
整个容器/进程的内存被划分为以下几个部分:
Total Process Memory (进程总内存)
│
├── JVM Metaspace (元空间): 存放类加载信息
├── JVM Overhead (执行开销): 线程栈、代码缓存、GC 预留等
└── Flink Total Memory (Flink 总内存)
│
├── JVM Heap (JVM 堆内存)
│ ├── Framework Heap: Flink 框架自身运行所需
│ └── Task Heap: 用户代码(算子逻辑)运行所需
│
└── Off-Heap Memory (堆外内存)
├── Managed Memory (托管内存): 最重要,用于 RocksDB StateBackend、批处理排序/缓存
├── Direct Memory (直接内存)
│ ├── Framework Off-Heap: Flink 框架自身堆外部分
│ ├── Task Off-Heap: 用户代码显式申请的堆外内存
│ └── Network Memory: 网络数据传输缓冲 (Netty)
2. 各组件详细说明
| 组件名称 | 描述与用途 | 关键配置参数 |
|---|---|---|
| Task Heap | 任务堆内存。用于运行用户代码创建的对象(如 MapFunction 中的临时变量)。如果你的代码中创建了大量 Java 对象,需要调大此部分。 |
taskmanager.memory.task.heap.size |
| Managed Memory | 托管内存(堆外)。这是 Flink 内存模型的核心。它由 Flink 自身管理,不经过 JVM GC。 1. 流处理:主要用于 RocksDB StateBackend 存储状态。 2. 批处理:用于排序、哈希表、缓存中间结果。 |
taskmanager.memory.managed.fraction (默认 0.4,即占 Flink 总内存的 40%) |
| Network Memory | 网络内存(堆外)。用于 TaskManager 之间的数据 Shuffle(洗牌)和广播。它由一组 Network Buffers 组成。如果作业并行度很高或 Shuffle 数据量大,需要增加此内存以避免反压。 | taskmanager.memory.network.fraction |
| Framework Heap/Off-Heap | 框架内存。Flink 系统底层运行所需的内存(如 Checkpoint 协调器等),通常不需要调整。 | taskmanager.memory.framework.heap.size |
| JVM Overhead | JVM 开销。为 JVM 自身预留的空间,包括线程栈、NIO buffer 等。如果报错 "Direct buffer memory",可能需要调整这里。 | taskmanager.memory.jvm-overhead.fraction |
三、 JobManager 内存模型
JobManager 的内存模型相对简单,因为它主要负责协调,不处理大量业务数据。
Total Process Memory
│
├── JVM Metaspace
├── JVM Overhead
└── Flink Total Memory
├── JVM Heap: 存放 JobGraph、ExecutionGraph、Checkpoint 元数据等。
└── Off-Heap Memory: 主要是 Netty 通信使用的直接内存。
注意:对于 JobManager,通常只需要关注 Heap 大小,因为它随着作业数量和并行度的增加而增加。
四、 内存配置的最佳实践
在 flink-conf.yaml 中配置内存时,通常有两种方式:
1. 傻瓜式配置(推荐容器环境)
直接设置进程总内存,Flink 会根据默认比例自动计算各部分大小。
# 设置 TaskManager 进程总内存为 4GB
taskmanager.memory.process.size: 4096m适用场景:Kubernetes、YARN 部署,直接限制容器资源。
2. 精细化配置
如果你明确知道作业是计算密集型(需要大 Heap)还是状态密集型(需要大 Managed Memory),可以手动调整。
场景 A:使用 RocksDB 且状态很大
- 调大
taskmanager.memory.managed.fraction(例如调至 0.6)。 - RocksDB 会直接使用这部分堆外内存来存储 MemTable 和 BlockCache。
- 调大
场景 B:大量数据 Shuffle / 高并行度
- 调大
taskmanager.memory.network.min或fraction。 - 避免出现
IOException: Insufficient number of network buffers。
- 调大
场景 C:用户代码极其复杂,创建大量对象
- 调大
taskmanager.memory.task.heap.size。 - 避免频繁 Full GC。
- 调大
五、 为什么 Flink 要使用“内存分段” (Memory Segment)?
Flink 在 Managed Memory 和 Network Memory 中,将内存切分为一个个固定大小的块,称为 MemorySegment(默认 32KB)。
- 序列化/反序列化优化:Flink 将 Java 对象序列化为二进制数据存储在 Segment 中。操作数据时,可以直接在二进制数据上进行(如比较 Key 的大小),无需反序列化成 Java 对象,极大提升效率。
- 对堆外内存友好:MemorySegment 可以轻松地分配在堆外(Direct Memory),实现 Zero-Copy(零拷贝)数据传输。
六、 常见问题排查
OOM: Java heap space
- 原因:用户代码创建对象太多,或 Heap StateBackend 存不下。
- 解决:增加
taskmanager.memory.task.heap.size,或改用 RocksDB。
OOM: Direct buffer memory
- 原因:Netty 网络传输过载,或使用了大量 NIO 操作。
- 解决:增加
taskmanager.memory.framework.off-heap.size或jvm-overhead。
Container is killed by YARN/K8s (OOM Killed)
- 原因:TaskManager 实际使用的物理内存超过了申请的容器限额。通常是因为 JVM Overhead 预估不足(例如开启了大量线程)。
- 解决:调大
taskmanager.memory.jvm-overhead.fraction,或者检查代码是否存在内存泄漏(非 Heap 区域)。
总结
Flink 的内存模型是一个以堆外内存为核心、动静分离的架构。
- Heap 留给用户代码逻辑;
- Off-Heap (Managed) 留给大规模状态存储(RocksDB)和批处理运算;
- Off-Heap (Network) 留给数据流转。
理解这个模型有助于你精准地进行资源规划和故障调优。