 播面
播面 Flink 状态的 TTL(Time-To-Live)机制是如何工作的?
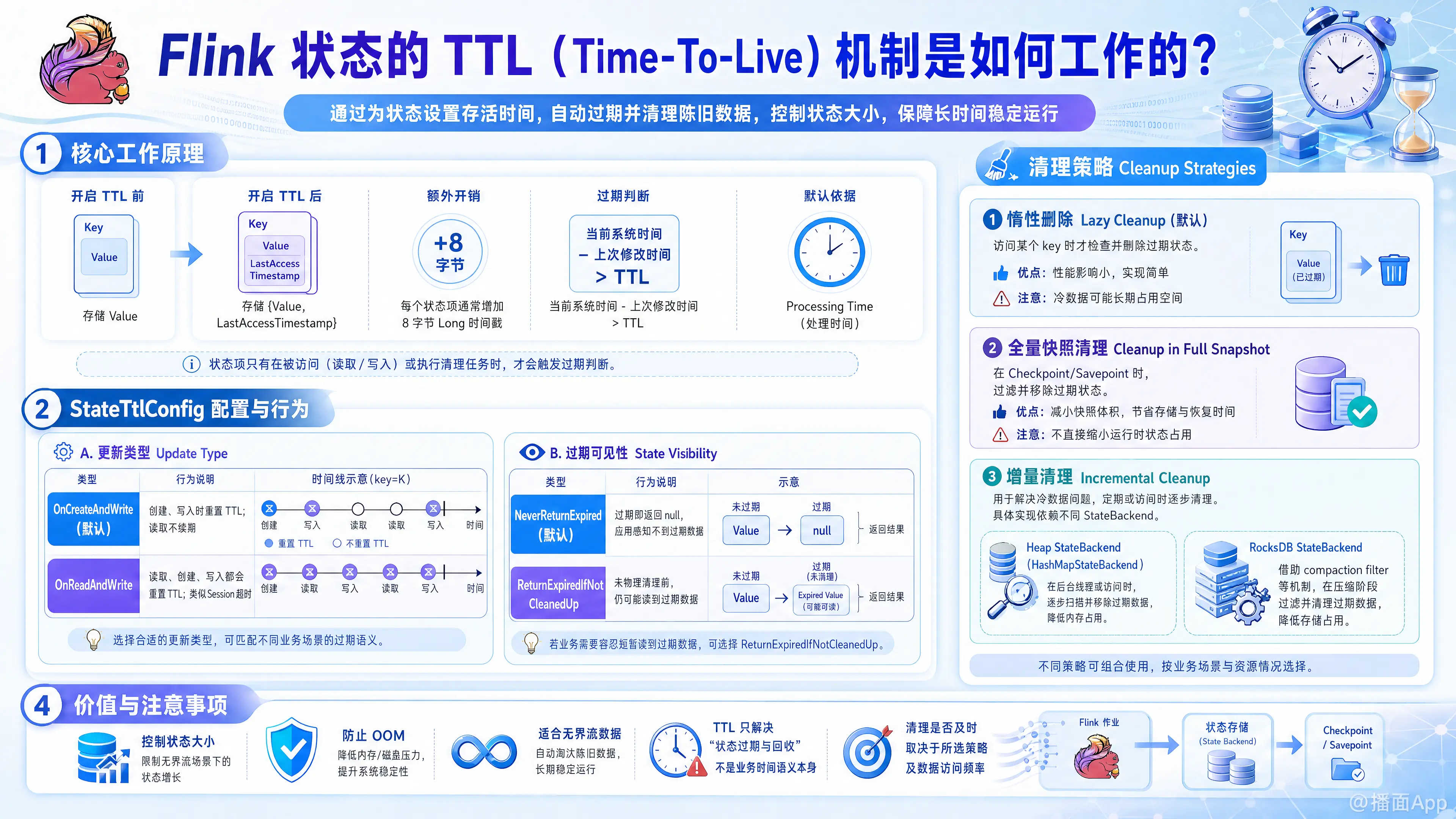
Flink 的状态 TTL(Time-To-Live,生存时间)机制允许用户为算子的状态设置一个过期时间。如果状态在规定时间内没有被更新(或访问),它将被视为过期并最终被清除。这对于控制状态大小、防止内存溢出(OOM)以及处理无界流数据至关重要。
以下是 Flink 状态 TTL 机制的详细工作原理,包括配置、内部存储、过期逻辑和清理策略。
1. 核心工作原理
A. 内部存储结构的改变
当你为一个状态开启 TTL 后,Flink 不仅仅存储用户的数据,还会额外存储一个时间戳(Last Modification Timestamp)。
- 没有 TTL 时: 存储
Value - 开启 TTL 后: 存储
{Value, LastAccessTimestamp}
这意味着开启 TTL 会增加一定的存储开销(通常每个状态项增加 8 字节的 Long 类型时间戳)。
B. 判断过期的逻辑
Flink 默认使用处理时间(Processing Time)来判断状态是否过期。
逻辑很简单:
2. 配置与行为 (StateTtlConfig)
在使用 TTL 时,需要通过 StateTtlConfig 来定义行为。主要包含以下几个方面:
A. 更新类型 (Update Type)
决定何时重置状态的计时器(即更新 LastAccessTimestamp):
OnCreateAndWrite(默认): 仅在创建和写入(更新)状态时重置 TTL。读取状态不会延长其生存时间。OnReadAndWrite: 在读取、创建和写入时都会重置 TTL。这类似于 Session 的超时机制。
B. 过期可见性 (State Visibility)
决定当数据已经过期但尚未被物理删除时,用户是否还能读取到它:
NeverReturnExpired(默认): 严格模式。如果数据过期,即使还在内存/磁盘中,也返回null(就像它不存在一样)。ReturnExpiredIfNotCleanedUp: 宽松模式。如果数据过期但还没被清理机制删除,仍然返回该数据。这在数据准确性要求不绝对严格的场景下很有用。
3. 清理策略 (Cleanup Strategies)
这是 TTL 机制中最复杂也是最重要的部分。仅仅标记过期是不够的,必须物理删除数据以释放空间。Flink 提供了多种清理策略:
A. 惰性删除 (Lazy Cleanup)
- 机制:只有当你访问(读取或写入)某个 key 的状态时,Flink 才会检查它是否过期。如果过期,则执行删除并返回空(取决于可见性配置)。
- 优点:对系统性能影响最小。
- 缺点:如果某些 key 此后永远不再被访问(Cold Data),它们将永远占用存储空间,导致状态无限膨胀。
- 默认行为:这是默认开启的。
B. 全量快照清理 (Cleanup in Full Snapshot)
- 机制:在生成 Checkpoint 或 Savepoint 时,Flink 会遍历所有状态,过滤掉过期的状态,只将未过期的状态写入快照。
- 优点:减小了快照的大小,且重启后状态是干净的。
- 缺点:不会减少运行时的状态大小(Heap 或 RocksDB 本地文件依然包含过期数据),只影响备份。
C. 增量清理 (Incremental Cleanup)
为了解决“冷数据”不被访问就不删除的问题,Flink 提供了后台清理机制,但根据 StateBackend 的不同,实现方式完全不同:
1. 针对 Heap StateBackend (HashMapStateBackend)
- 机制:在每次状态访问或处理数据时,Flink 会额外随机遍历一部分状态迭代器,检查并移除过期数据。
- 配置:
StateTtlConfig.newBuilder(...).cleanupIncrementally(cleanupSize, runCleanupForEveryRecord) - 代价:会增加处理每条数据的延迟(因为要多做几次迭代检查)。
2. 针对 RocksDB StateBackend (EmbeddedRocksDBStateBackend)
- 机制:利用 RocksDB 的 Compaction(压缩) 机制。Flink 注册了一个自定义的 RocksDB Compaction Filter。当 RocksDB 在后台合并 SST 文件时,过滤器会检查时间戳,丢弃过期的键值对。
- 配置:
StateTtlConfig.newBuilder(...).cleanupInRocksdbCompactFilter(queryTimeAfterNumEntries) - 优点:非常高效,利用了 RocksDB 原有的后台进程,不阻塞主数据流的处理。
- 注意:这是处理大规模状态且带有 TTL 的推荐方式。
4. 代码示例
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.minutes(10)) // 1. 设置 TTL 时长
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // 2. 设置更新策略
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) // 3. 设置可见性
// 4. 设置清理策略 (针对 RocksDB)
.cleanupInRocksdbCompactFilter(1000)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("myState", String.class);
stateDescriptor.enableTimeToLive(ttlConfig); // 5. 绑定 TTL 配置5. 注意事项与限制
- 序列化开销:由于需要存储时间戳,序列化器会发生变化。如果从无 TTL 的作业迁移到有 TTL 的作业(或反之),通常需要注意状态兼容性(Flink 内部处理了大部分兼容性,但需谨慎)。
- 处理时间依赖:TTL 依赖于处理时间(机器的系统时钟)。如果恢复作业(Checkpoint/Savepoint),过期的判断是基于重启时的当前时间,而不是快照生成时的时间。
- MapState 的特殊性:对于
MapState,TTL 是针对每个 Key-Value 对(Entry)独立计算的,而不是整个 Map。 - ListState 的特殊性:对于
ListState,TTL 是针对整个 List 的每个元素独立计算的(每个元素都会被包装成带时间戳的对象)。
总结
Flink 的 TTL 机制通过包装状态值以存储时间戳,结合惰性删除和后台清理策略(特别是 RocksDB 的 Compaction Filter),实现了高效的状态生命周期管理。它是解决 Flink 状态无限增长问题的首选方案。