 播面
播面 Flink的Keyed State(键控状态)和 Operator State(算子状态)
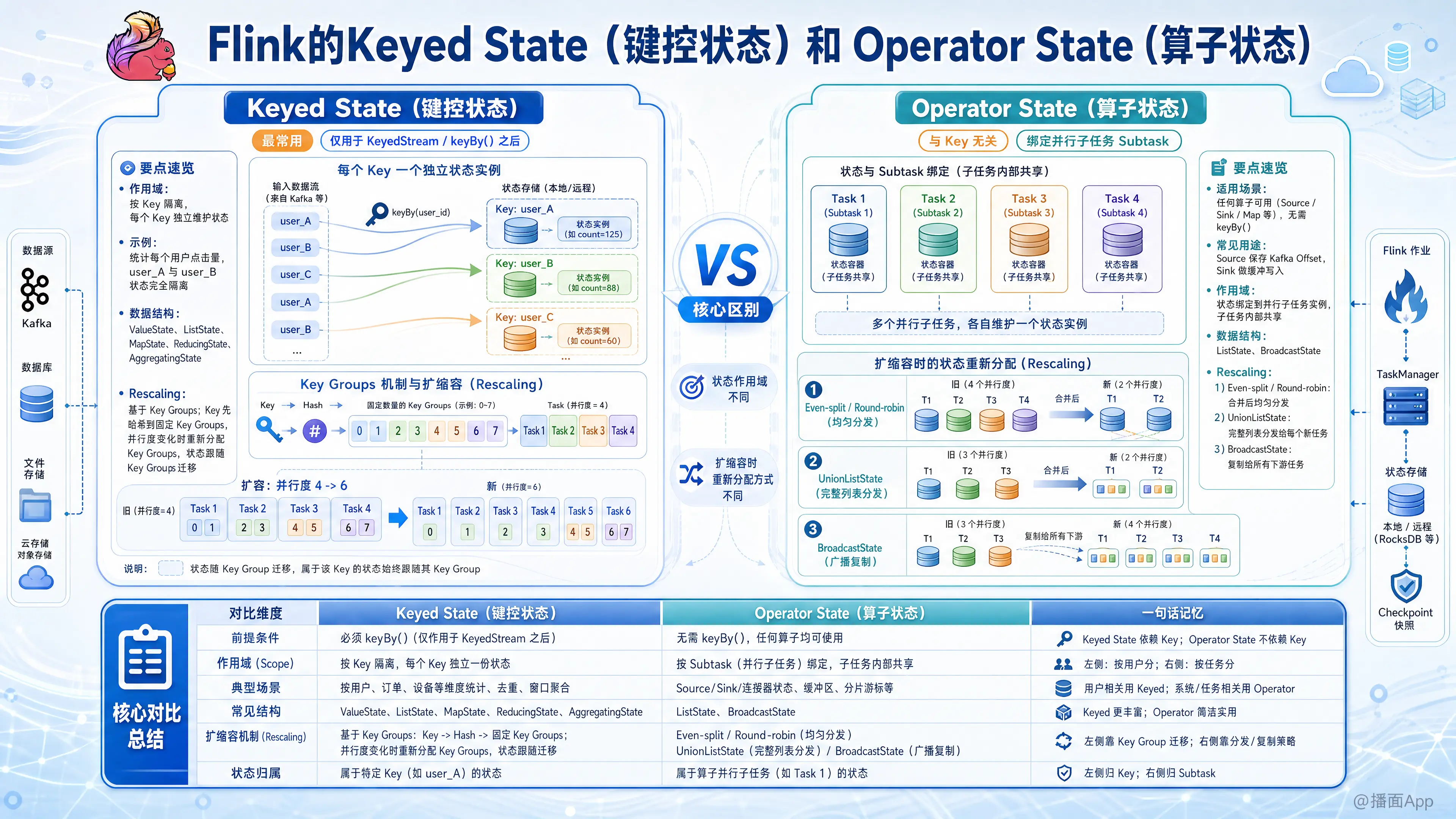
Apache Flink 中的状态(State)是其流处理能力的核心,用于记忆过去的数据以影响未来的处理结果。Flink 将状态主要分为两大类:Keyed State(键控状态) 和 Operator State(算子状态)。
这两者的核心区别在于状态的作用域(Scope)以及在并行度发生变化(扩缩容)时状态如何重新分配。
以下是详细的对比和解析:
1. Keyed State (键控状态)
这是 Flink 中最常用的状态类型。
- 适用场景:只能用在
KeyedStream上,即在调用keyBy()算子之后。 - 作用域:
- 状态是根据 Key 来隔离的。
- 对于每一个 Key,都有一个独立的状态实例。
- 例如:如果你在统计每个用户的点击量,Key 是
userId,那么user_A的计数器和user_B的计数器是完全隔离的。
- 数据结构:Flink 提供了丰富的接口来操作 Keyed State:
ValueState<T>: 保存单个值(如计数器)。ListState<T>: 保存一个列表。MapState<K, V>: 保存键值对映射。ReducingState<T>: 保存聚合后的结果(通过 reduce 函数更新)。AggregatingState<IN, OUT>: 保存聚合结果(比 Reducing 更通用)。
- 扩缩容(Rescaling)机制:
- Flink 使用 Key Groups(键组) 机制。
- 所有的 Key 被哈希分配到固定的 Key Groups 中(默认最大并行度通常为 128 或更大)。
- 当并行度改变时,Flink 会将 Key Groups 重新分配给新的 Task。状态随着 Key Group 走,因此特定的 Key 总是能访问到它之前的状态。
2. Operator State (算子状态)
Operator State 与 Key 无关,它绑定到算子的并行子任务(Subtask)。
- 适用场景:可以用于任何算子(Source, Sink, Map 等),不需要
keyBy()。常用于 Source 连接器(保存 Kafka Offset)或 Sink 连接器(缓冲写入数据)。 - 作用域:
- 状态绑定到当前的并行子任务(Task 实例)。
- 如果一个算子的并行度是 4,那么就有 4 个独立的 Operator State 实例。
- 子任务内部的所有数据共享这一个状态。
- 数据结构:
ListState<T>: 列表状态。BroadcastState<K, V>: 广播状态(一种特殊的 Operator State,用于将配置广播到所有 Task)。
- 扩缩容(Rescaling)机制:
- 当并行度发生变化时,Operator State 需要定义“如何分配”状态数据。主要有三种模式:
- ListState (Even-split / Round-robin): 将所有并发的状态合并成一个大列表,然后均匀分配给新的并发任务(最常用)。
- UnionListState: 将所有并发的状态合并,然后把完整的列表广播给每一个新的并发任务(每个任务都收到全量数据)。
- BroadcastState: 总是复制给所有下游任务。
- 当并行度发生变化时,Operator State 需要定义“如何分配”状态数据。主要有三种模式:
3. 核心对比总结表
| 特性 | Keyed State (键控状态) | Operator State (算子状态) |
|---|---|---|
| 前提条件 | 必须在 keyBy() 之后使用 |
可以在任何算子中使用 |
| 绑定对象 | 绑定到 Key | 绑定到 Operator Subtask (并行子任务) |
| 访问方式 | 通过 RuntimeContext 访问 (getState, getMapState 等) |
通常通过实现 CheckpointedFunction 接口访问 |
| 数据结构 | Value, List, Map, Reducing, Aggregating | ListState, BroadcastState |
| 扩缩容行为 | 基于 Key Group 自动重新分片,Key 的状态跟随 Key 走 | 逻辑重分配 (均匀拆分、全量广播等) |
| 典型用例 | 聚合窗口、去重、基于 Key 的模式匹配 | Kafka Source (Offset)、文件 Sink、广播配置 |
| 状态大小 | 通常较大(Key 的数量可能是一亿级) | 通常较小(仅与并行度相关) |
4. 代码层面的区别
Keyed State 示例
通常在 RichFunction 中使用:
java
public class CountWindow extends RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>> {
// 1. 定义状态句柄
private transient ValueState<Integer> countState;
@Override
public void open(Configuration parameters) {
// 2. 初始化状态描述符
ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<>(
"count-state", // 状态名称
Integer.class); // 状态类型
countState = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(Tuple2<String, Integer> value, Collector<Tuple2<String, Integer>> out) throws Exception {
// 3. 访问状态(自动根据当前处理数据的 Key 获取对应值)
Integer currentCount = countState.value();
if (currentCount == null) {
currentCount = 0;
}
currentCount += 1;
// 4. 更新状态
countState.update(currentCount);
out.collect(Tuple2.of(value.f0, currentCount));
}
}Operator State 示例
通常实现 CheckpointedFunction 接口:
java
public class BufferingSink implements SinkFunction<String>, CheckpointedFunction {
private final int threshold;
private List<String> bufferedElements; // 内存中的临时缓冲
// 1. 定义状态句柄
private transient ListState<String> checkpointedState;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
@Override
public void invoke(String value, Context context) {
bufferedElements.add(value);
if (bufferedElements.size() == threshold) {
// 发送到外部系统...
bufferedElements.clear();
}
}
// 2. 制作快照时调用 (Snapshot)
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear();
// 将当前内存数据放入状态中保存
for (String element : bufferedElements) {
checkpointedState.add(element);
}
}
// 3. 恢复状态时调用 (Restore)
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<String> descriptor = new ListStateDescriptor<>(
"buffered-elements",
String.class);
// 获取 Operator State
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
// 如果是故障恢复,从状态中加载数据回内存
if (context.isRestored()) {
for (String element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}总结
- 如果你需要处理每个用户、每个设备、每个订单的数据,请使用 Keyed State。
- 如果你需要处理Kafka Offset、全局配置、或者与特定 Key 无关的缓冲数据,请使用 Operator State。